


How to Get a Taste of Everything: Sampling Techniques
Last Updated on July 17, 2023 by Editorial Team
Author(s): Roli Trivedi
Originally published on Towards AI.
Mastering the art: Tips and tricks for successful sampling
Sampling is the process of selecting a subset(sample) from the population. It is done to get information about a population based on statistics from a subset of the population, i.e., a sample, without investigating every individual.
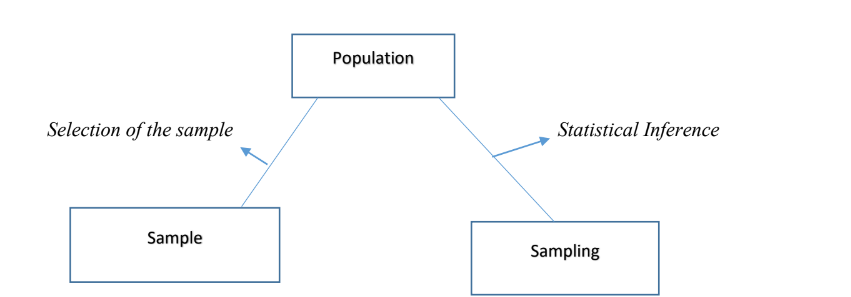
Types of Sampling
- Probability Sampling: When we use probability to sample observation from the population. In probability sampling, each element has an equal chance to get selected.
- Non Probability Sampling: When sampling is done on the basis of convenience and all the elements don't have an equal chance to get selected.

Probability Sampling Methods
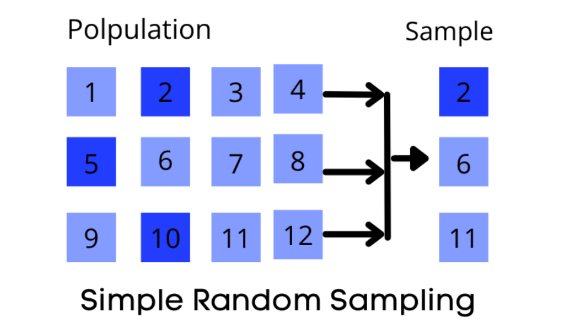
- Simple Random Sampling: One of the simplest probability sampling techniques. Here we select items at random. Every observation in the population has a chance of getting selected.
For Example, if you have a bag of white and black balls and you want to select one ball from it, then if you pick a ball from the bag, there are equal chances of the white and black balls being picked.
- Systematic Sampling: It is an extension of simple random sampling. Here we pick every n element from the first random element. The value of n is calculated by (total objects/sample size).
For Example, you want to pick 6 random balls, and there are 20 total balls.
n = 20/6 i.e 3
So you will pick every 3rd ball from the first random ball.
Note: It might also lead to bias if there is an underlying pattern in which we are selecting items from the population. Therefore make sure there is no hidden pattern.

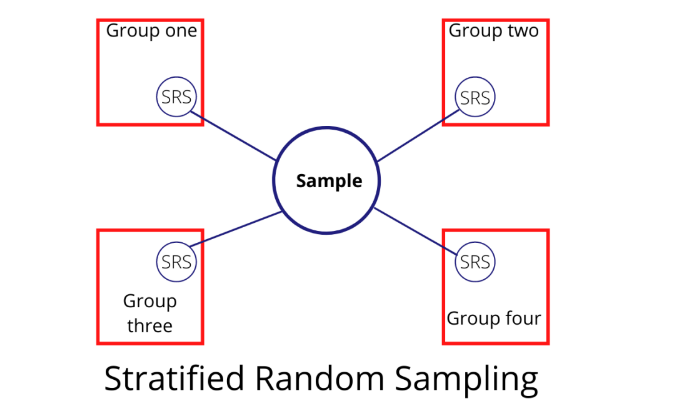
- Stratified Sampling: You will segregate the population based on the attribute which you want to study. Then from each subgroup randomly pick one element. Here each subgroup is called strata. We use this type of sampling when we want representation from all subgroups of the population.
For example, suppose a researcher wants to conduct a study on the satisfaction level of employees in a large company. They might divide the employees into strata based on their departments and then randomly select participants from each department.
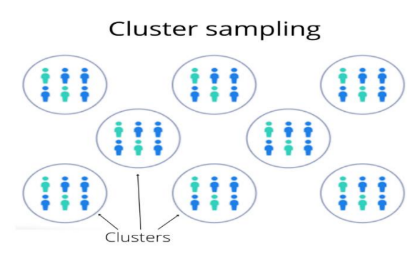
- Cluster Sampling: This type of sampling is used when we focus on a region area. Here we use subgroups of the population as sampling units rather than individuals. The population is divided into clusters, and then a cluster is selected at random as a sampling unit.
For example, suppose a researcher wants to study the eating habits of people in a certain city. They might divide the city into clusters based on the neighborhoods and then randomly select some of the neighborhoods to be included in the study. Within each selected neighborhood, the researcher could then select a sample of individuals to participate in the study.
Non-Probability Sampling Methods
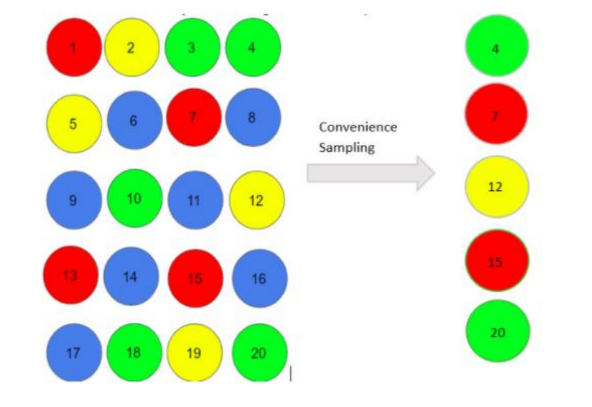
- Convenience Sampling: Here, individuals are selected based on their availability and willingness to take part. It is convenient for participants if they want to participate or not.
For Example, NGOs conduct convenience sampling at malls by distributing leaflets about upcoming events. They do that by standing at the mall entrance and giving out randomly.
- Quota Sampling: We choose items from a predetermined characteristic of the population. Here the population is divided into groups called strata, and then non-probability sampling, like convenience sampling or judgmental sampling, is applied to these groups based on quota. In quota sampling, the chosen sample might not be the best representation of the characteristics of the population that weren’t considered.
For Example, Consider that we have to select individuals
having a number in multiples of four for our sample. Therefore, the individuals numbered 4, 8, 12, 16, and 20 are already reserved for our sample.

- Snowball Sampling: Here, existing people are asked to nominate further people known to them so that the sample increases in size like a rolling snowball. This is effective when the sampling frame is difficult to identify. However, there is a significant risk of selection bias as referenced people will share common traits with the person who recommends them. This method of sampling is effective when a sampling frame is difficult to identify.
For example, there is research going on a particular product, so a number of users are selected for it, and then those users are asked to pick the next set of people who could try the product. This will be called snowball sampling. Here, we had randomly chosen person 1 for our sample, and then he/she recommended person 6, person 6 recommended person 11, and so on.
1 > 6 > 11 > 14 > 19

- Judgmental Sampling: It is also called selective sampling. It depends on the judgment of experts when choosing who should participate. It is also prone to bias by experts.
For Example, auditors find a basket more fishy as compared to other ones, so they select that particular basket for auditing. Here each basket doesn’t have an equal probability of being selected. Assume that our experts agree that people with the numbers 1, 7, 10, 15, and 19 should be included in our sample since they can help us better infer the population.

Thanks for reading! If you enjoyed this piece and would like to read more of my work, please consider following me on Medium. I look forward to sharing more with you in the future.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")