



From UNet to BERT: Extraction of Important Information from Scientific Papers
Last Updated on September 21, 2022 by Editorial Team
Author(s): Eman Shemsu
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Objective
Despite an increase in the number of papers published each year, little work is done on the application of Machine Learning to scientific papers. Machine learning models are becoming smarter as well. Even though scientific papers are hard to understand even by us humans, they contain unique structures, formatting, and languages which set them apart from other documents.
In this project, I will demonstrate how we can extract and summarize important information from such documents following a multidisciplinary approach of Natural Language Processing and Computer Vision. Please note that this is a continuation of my previous blog on the Extraction of important information from scientific papers.
Recap
I have covered the computer vision part in my previous blog here. The following is a summary of what was covered.
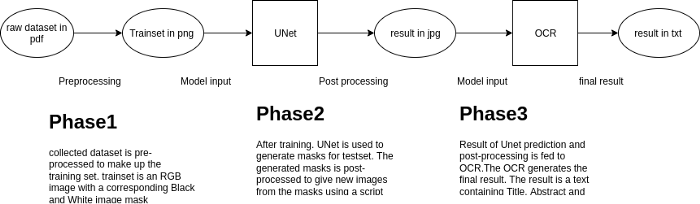
The computer vision part contains a UNet-OCR pipeline that does the following:
- Extraction of important sections learned by UNet and
- Conversion of learned sections into text using the OCR
The UNet generates a black and white mask that highlights the Title, Author/Authors, and Abstracts sections of a given paper. A post-processing step follows where the masked image is reconstructed into an RGB image. This image is then passed to an Optical character recognition(OCR) engine to be converted into text. I have used Tesseract with default parameters for the OCR.
Text Summarization with BERT
Text summarization is a machine learning technique that aims at generating a concise and precise summary of a text without overall loss of meaning. Text summarization is a popular and much-researched domain of Natural language Processing.
There are two approaches to text summarization which are:
- Extractive text summarization
- Abstractive text summarization
In Extractive text summarization, the summary is generated using excerpts from the texts. No new text is generated; only existing text is used in the summarization process. This can be done by scoring each sentence and generating the k most important sentences from the text.
Abstractive summarization is how a human would do a summary of content i.e explain in one’s own words. The summary would include words, phrases, and sentences not in the text.
I followed an Extractive text summarization approach for this project and used the open source Bert-extractive summarizer[1] repository.
BERT[2] stands for Bidirectional Encoder Representations from Transformers[3] and is a model that has learned sentence representation from training on a very large corpus. Only the encoder part is taken from the Transformers’ encoder-decoder architecture for the BERT model.
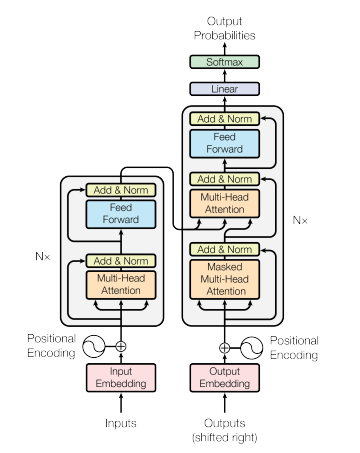
In short, the encoder part accepts the word embedding of an input text. Positional encoding transforms the word embedding to add meaning to each word with respect to its positional context. The attention block (Multi-head Attention) computes the attention vector for each word. These vectors are then fed to the feed-forward Neural Network one vector at a time. This result consists of a set of encoded vectors for each word which is the final output of the BERT model.
The Bert-extractive-summarizer repository is based on the paper Leveraging BERT for Extractive Text Summarization on Lectures [4]. The paper explains using BERT to generate sentence representation and then using the K-mean algorithm to cluster these representations around k concepts. The k sentences closest to their respective centroids are then returned as a representative summary for their cluster.
Getting started
Start by cloning my repository available at Dagshub[5].
git clone https://dagshub.com/Eman22S/Unet-OCR-2.0.git
Install DVC.
pip install dvc
Install dagshub.
pip install dagshub
Install Tesseract.
sudo apt install tesseract-ocr-all -y
Install Bert.
pip install bert-extractive-summarizer
Configure your DVC origin.
dvc remote modify dv-origin — local auth basic
dvc remote modify dv-origin — local user {your Dagshub username}
dvc remote modify dv-origin — local password {your Dagshub password}
If you feel confused about configuring your DVC, refer to this documentation.
Next, pull my tracked dataset into your system using this command.
dvc pull -r dv-origin
Run tesseract on your image inside a python shell.
import subprocess
result= subprocess.run(['tesseract','postprocessed/1409.1556_0.jpg',
'-','-l','eng'], stdout=subprocess.PIPE)
result = result.stdout
result = str(result)
Pass this result to the Summarizer model.
from summarizer import Summarizer
body = result
model = Summarizer()
result = model(body, ratio=0.2) # Specified with ratio result = model(body, num_sentences=3) # Will return 3 sentences
print(result)
The above code block calls the model with your text (body) and a number of sentences = 3. This means the model will summarize your text in 3 sentences. You can increase or decrease the number of sentences depending on your use case. If you are on Google Colab Notebook refer to this notebook.
What did I use?
- Colab notebook free version
- Dagshub as my online repository
- DVC to track my dataset
- Bert-extractive-summarizer
Project Pipeline
The Figure below shows the output on 1409.1556_0.jpg found here.

Conclusion
You can train the UNet to extract any set of sections from scientific papers but for this experiment, I chose the Abstract, Author/s, and Title sections. BERT gives us the final result which is a summary of sections found in Abstract, Author/s, and Titles. While most papers have more or less similar formatting, structure, and sections, the challenge for this project was to extract a given section where that section might/might not be there for a given paper.
With that, we have reached the final milestone. Congratulations on making it this far! Feel free to reach out for any questions or feedback. Would be happy to hear from you!
References
[1] https://github.com/dmmiller612/bert-extractive-summarizer
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
[3] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[4] Miller, Derek. “Leveraging BERT for extractive text summarization on lectures.” arXiv preprint arXiv:1906.04165 (2019).
- Approaches to Text Summarization: An Overview – KDnuggets
- A Gentle Introduction to Text Summarization in Machine Learning
https://www.youtube.com/watch?v=TQQlZhbC5ps
From UNet to BERT: Extraction of Important Information from Scientific Papers was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

