



FastML: Accelerate Model Building
Last Updated on August 30, 2022 by Editorial Team
Author(s): Ankit Sirmorya
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Introduction
Data science and artificial intelligence have caused a lot of controversy in today’s technologies. Machine learning (ML) is increasingly becoming the major approach for evaluating complex data in a variety of areas, including high-energy physics. Following the rapid rise of ML through deep learning algorithms, there is an ongoing re-investigation of processing technologies and strategies to accelerate deep learning and inference. People are seeking speed in their job as the need for modern and autonomous technologies develops since automation and speed may contribute to success in many areas. The work of data scientists, AI, and machine learning engineers is focused on the use of multiple algorithms that make our tasks easier and faster. However, selecting a single algorithm for a certain use case is usually challenging since there are numerous algorithms that can execute the tasks we need to perform equally effectively.
As machine learning techniques evolved, much of the focus went to constructing very large algorithms that handle complicated challenges such as language translation and speech recognition. However, in the aftermath of these findings, a wide range of scientific applications have emerged that can greatly benefit from the present rapid advancements. Furthermore, when individuals recognize how to alter their scientific approach in order to enjoy the benefits of the AI revolution, these applications have extended [7]. This can include AI’s ability to classify events in real-time, such as detecting a particle collision or gravitational wave merging. However, in all cases, accelerating ML is a driving factor in the design goal. When working as a Data Scientist, AI, or ML Engineer on a project, speed is essential. FastML allows for the rapid and flexible testing of models against numerous methods [1].
FastML is a Python library that allows us to test and train the processed data with the desired test size, as well as run several classification algorithms on the prepared data, all in a few lines of code [1]. This allows us to see the behaviors of all of the algorithms we decided to run in order to evaluate which algorithms function best with our data for future development utilizing our preferred algorithm. This also saves us the time and effort of creating around 300 lines of code manually if we don’t use fastML.
Understanding FastML
Fast-ML is a Python package that offers a host of features aimed at making data scientists’ lives simpler. It is a programming framework that allows users to create, train, and test recorded data with the desired test size, as well as execute different classification algorithms on the processed data, all with a single line of code [1]. This allows users to discover the behaviors of all of the algorithms they decided to run in order to determine which algorithms give the best outcomes with the data for future development using our preferred algorithm. This also alleviates the stress of manually writing around 300 lines of code if fastML is not used. This rapid machine learning technique is preferred by data scientists and machine learning engineering personnel for completing jobs swiftly and efficiently.
FastML mimics Scikit-learn capability by first learning the transforming parameters from the training dataset and then transforming the training/validation/test dataset [2]. FastML provides a ready-to-use neural net classifier built with Keras for deep learning classification [1]. Users may add whatever technique they choose to the project, including the neural net classifier. FastML is accessible on PyPI [8], making it easy to install locally using Python’s package management, pip. Before installing FastML for local development, users must ensure that Python and Pip are installed and added to the path.
Depending on the sort of data users have, the target data may need to be encoded. Encoding the target data is advantageous because it chooses values that can explain the target data and help machine learning algorithms determine what the target data actually is. With the fastML python package [1], encoding target data is also a breeze.
FastML Lab
FastML is a machine learning lab for fundamental sciences that operates in real time. The FastML Lab is a research team of physicists, engineers, and computer scientists interested in applying machine learning techniques to unique and demanding scientific applications [3]. Real-time, on-detector, and low latency machine learning applications, as well as high-throughput heterogeneous computing big data concerns, are among the projects under consideration. Researchers want to use strong machine learning techniques to improve fundamental physics research, from the world’s largest colliders to the universe’s most intense particle beams [3].
Few works with the advantage of FastML Lab
Real-time Artificial Intelligence for Accelerator Control: A Study at the Fermilab Booster
The use of a neural network trained through reinforcement learning to accurately regulate the gradient magnet power supply at the Fermilab Booster accelerator complex is detailed in [4]. Preliminary results were obtained by building a surrogate machine-learning model using actual accelerator data to mimic the Booster environment and then utilizing this surrogate model to train the neural network for its regulatory task.
Fast convolutional neural networks on FPGAs with hls4ml
On field-programmable gate arrays, an automated technique for deploying extremely low-latency, low-power deep neural networks with convolutional layers is shown (FPGAs). Pruning and quantization-aware training are presented, as well as examples of how resource use may be greatly decreased while maintaining model accuracy [5].
Compressing deep neural networks on FPGAs to binary and ternary precision with hls4ml
The hls4ml library’s implementation of binary and ternary neural networks is given and designed to automatically transform deep neural network models to digital circuits using FPGA firmware [6].
Domains and Techniques of FastML
The goal of fastML is to bring together the ideas of professionals from a variety of scientific fields, including particle physicists, material scientists, and health monitoring researchers, as well as machine learning experts and computer system designers. As scientific ecosystems become more complex and dynamic, new paradigms for data processing and reduction must be included in system-level design [9]. Various sectors, such as computer elements and systems, machine learning techniques, and science applications, are all expanding rapidly as a result of the momentum supplied by fast machine learning methods to expedite scientific discovery.
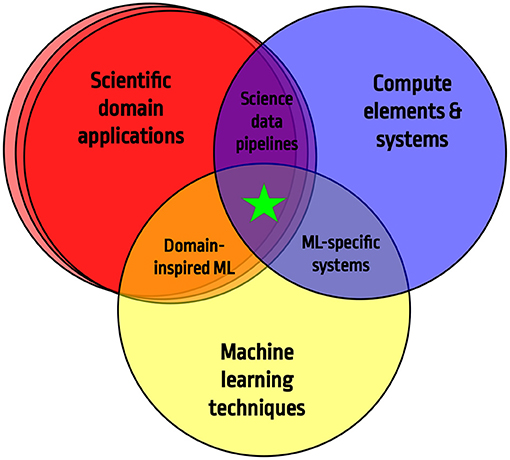
As the size and speed of scientific ecosystems grow, new paradigms for data processing and reduction must be included in system-level design. Quick machine learning implementations may appear widely diverse across domains and architectures, yet they may have identical underlying data formats and integration requirements. This section discusses a wide range of scientific fields spanning apparently unrelated vocations, as well as their current techniques and future requirements.
Techniques implemented in FastML
Fast machine learning with TensorFlow and Kubernetes
Training machine learning models might take a long time if you lack the requisite hardware. During the neural network training phase, you must compute the addition of each neuron to the total error. This might lead to hundreds of computations being run at each step. When paired with FastML, TensorFlow, a parallel computing framework, and Kubernetes, a platform that can scale up or down in terms of application usage [14], may easily speed up the operation.
TensorFlow is an open-source framework for creating and training machine learning models. It features several abstraction layers that allow you to deploy premade machine learning models quickly. Deepmind used this capacity to build AlphaGo Zero, which used 64 GPU workers and 19 CPU parameter servers to play 4.9 million GO games against itself in three days.
Kubernetes is an open-source platform for managing containerized applications at scale that is also a Google project. When there is a long queue of clients, the company quickly opens another register to accommodate a few of them. If an instance fails to function correctly, it is destroyed, and a new one is created immediately.
Distributing the computations for the machine learning project might help you save time. Combining a highly scalable library like TensorFlow with a flexible platform like Kubernetes allows users to make the most use of resources and time. Of course, things may be sped up even further by fine-tuning the machine learning models.
Random Forest using the fastai
Anyone who wants to study machine learning must first learn how to code. There are several autoML tools available, but most are still in their infancy and are much beyond the normal person’s budget. A data scientist’s sweet spot is combining programming with machine learning technologies.
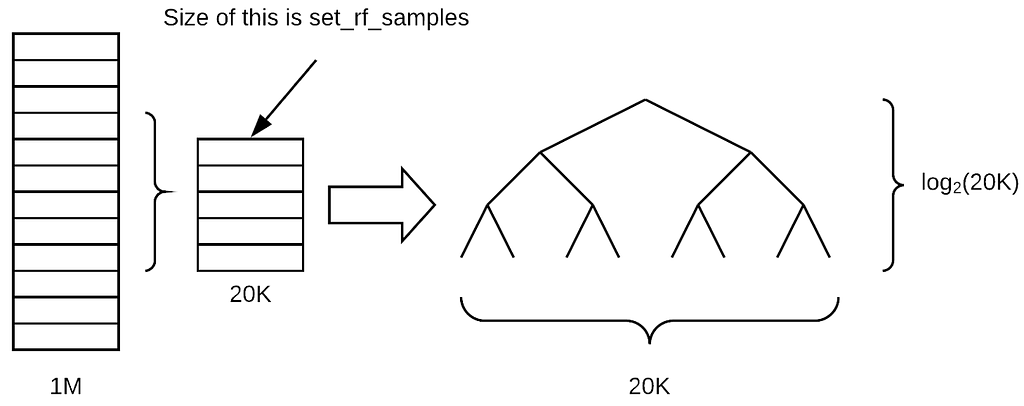
A random forest is a form of universal machine learning technique that may be used for both regression (with a continuous objective variable) and classification (with a categorical goal variable) [17]. As seen in Figure 4, Random Forest is a collection of trees known as estimators. In a random forest model, the parameter n estimator defines the number of trees. It can perform better when just a few features are required to alter the model.
Fast Machine Learning Development with MongoDB
A growing number of products now integrate machine learning and AI to provide a fantastic tailored user experience, and office software is no different. Spoke integrates artificial intelligence into every part of their office productivity solution by leveraging Google Cloud Platform and MongoDB’s flexible document architecture, dynamic indexing, scalable atomic operations, sophisticated database administration tools, and performance reliability [15].
Spoke [16] goes beyond traditional ticketing with its pleasant, AI-powered chatbot that saves workplace teams hours of time by responding to queries via Slack, email, SMS, and the web. Spoke employs MongoDB to do real-time dynamic model training from user interaction data and offers hundreds of models, with several customized models per client.
Domain Application Examples of FastML
High-intensity accelerator experiments
The Belle II Experiment’s ML-Based Trigger System
Due to the increasing brightness, the majority of the data acquired comes from unwanted but unavoidable background processes rather than electron-positron annihilation at the contact site (target luminosity is 8 1035cm2s1). Because of the high background rates, it is not only inefficient to keep all of the data, but it is also impractical to set up an infrastructure that saves all of the created data [7]. To determine which recorded events should be preserved online, a hierarchical trigger system is used.
Mu2e
The trigger system is based on detector Read Out Controllers (ROCs), which send out zero-suppressed data to Data Transfer Controller units (DTCs) on a continuous basis [7]. The proton pulses are delivered at a frequency of around 600 kHz and a duty cycle of about 30%. (0.4 s of the 1.4 s booster-ring delivery duration). Each proton pulse is regarded as a distinct event, with data from each event being pooled at a single server over a 10 Gbps Ethernet switch. The online reconstruction of the events then begins, followed by the selection of a trigger. The following conditions must be met by the trigger system: (1) provide signal efficiency of more than 90%; (2) limit the trigger rate to a few kHz — equivalent to 7 Pb/year Our major physics triggers make the ultimate judgment based on the information from the rebuilt tracks.
Biomedical Engineering
Inadequate training and testing data is a significant impediment to clinical ML adoption [7]. The medical data annotation procedure is both time-consuming and expensive for large image and video datasets that require specialized knowledge. The latency in trained model inference creates computer issues while performing real-time diagnosis and surgery. The quality of services for time-critical healthcare requires less than 300 ms in real-time video transmission (Shukla et al., 2019). A deep learning model’s efficiency and speed are important for generating 60 frames per second (FPS) high-quality medical footage.
Health Monitoring
Monitoring habits and behaviors with wearable devices raises several concerns. To begin, these devices should be capable of detecting dangerous behaviors properly and in real-time. The majority of current systems detect these hazardous habits by an offline ML strategy, in which the ML algorithm recognizes these actions after they have occurred. An offline approach prevents the delivery of therapy that can help people break bad behaviors. As a result, developing ML approaches capable of identifying these behaviors online and in real-time is critical in order to provide therapies such as just-in-time adaptive interventions (JITAIs). Second, because these gadgets capture sensitive information, protecting an individual’s privacy is vital. Finally, because these behaviors might occur in a number of settings, the health monitoring system should be agnostic to the activity’s location. [7] Such monitoring demands the creation of a number of machine learning models for diverse scenarios.
ML for Wireless Networking and Edge Computing
Traditional ML model implementations, particularly deep learning approaches, lag well below packet-level dynamics in terms of utility. Furthermore, for efficiency, current ML/AI services are typically performed in the cloud at the expense of higher communication overhead and latency. The development of a computer platform capable of running complex ML models at relevant timescales (10 ms) within small cell access points is a critical challenge in wireless networking and edge computing situations [7].
Cosmology
Cosmology is the study of the Big Bang, the evolution of the Universe, and its future (ultimate fate). The large-scale dynamics of the universe are governed by gravity, in which dark matter plays an important role, and the accelerating expansion rate of the cosmos, which is caused by dark energy [7].
As astronomy approaches the big data era with next-generation facilities like the Nancy Grace Roman Space telescope [10], Vera C. Rubin Observatory [11], and Euclid telescope [12], systematic uncertainties are expected to dominate the uncertainty budget in the estimation of cosmological parameters; understanding such uncertainties can lead to sub-percentage point estimates. The huge flood of cosmic photographs, on the other hand, will be difficult to examine in a traditional fashion (by human interaction); new automated techniques will be necessary to extract relevant astronomical data.
Gravitational Waves
Gravitational waves provide a novel method for studying fundamental physics, such as testing the theory of general relativity in the strong field regime, gravitational wave propagation speed and polarization, the state of matter at nuclear densities, black hole formation, quantum gravity effects, and much more. In addition to electromagnetic and neutrino astronomy, they have established a totally new window for exploring the Universe. This includes the study of populations of compact objects such as binary black holes and neutron stars, including their formation and evolution, determining the origin of gamma-ray bursts (GRBs), measuring the expansion of the Universe independently of electromagnetic observations, and other related research [13].
Conclusion
Fast Machine Learning is described in Science as the introduction of ML into the experimental data processing infrastructure to enable and accelerate scientific discovery. Combining advanced machine learning algorithms with experimental design minimizes “time to science” [1] and can range from real-time feature extraction as close to the sensor as possible to large-scale ML acceleration across distributed grid computing data centers [7]. The overarching objective is to lower the barrier to advanced machine learning methodologies and implementations in order to accomplish major breakthroughs in experimental capacity across a diverse spectrum of seemingly unrelated scientific applications. Effective solutions need collaboration among domain experts, machine learning researchers, and computer architecture designers.
Both ML training and deployment methods, as well as computer architectures, are extremely fast-moving topics, with new works appearing at an alarming rate, even for this study. While new approaches are continually being created in both industries, understanding the codesign of new algorithms for various hardware, as well as the ease of use of the tool flows for deploying such algorithms, is especially important [7]. Innovations in this field will allow for the rapid and broad deployment of powerful new machine learning hardware.
We’re looking forward to seeing how quickly advancements in apps, machine learning algorithms, and hardware platforms can be made and, more importantly, how they may be integrated to enable paradigm-shifting scientific advances.
Reference
[1] https://towardsdatascience.com/the-fastml-guide-9ada1bb761cf
[2] https://pypi.org/project/fast-ml/
[3] https://fastmachinelearning.org/
[4] https://arxiv.org/abs/2011.07371
[5] https://iopscience.iop.org/article/10.1088/2632-2153/ac0ea1
[6] https://iopscience.iop.org/article/10.1088/2632-2153/aba042
[7] https://www.frontiersin.org/articles/10.3389/fdata.2022.787421/full
[8] https://pypi.org/project/fastML/
[10] https://www.frontiersin.org/articles/10.3389/fdata.2022.787421/full#B504
[11] https://www.frontiersin.org/articles/10.3389/fdata.2022.787421/full#B297
[12] https://www.frontiersin.org/articles/10.3389/fdata.2022.787421/full#B46
[13] https://www.frontiersin.org/articles/10.3389/fdata.2022.787421/full#B8
[14] https://www.acagroup.be/en/blog/fast-machine-learning-with-tensorflow-and-kubernetes/
[15] https://cloud.google.com/customers/spoke
[17] https://www.analyticsvidhya.com/blog/2018/10/comprehensive-overview-machine-learning-part-1/
[18] https://blog.container-solutions.com/tensorflow-on-kubernetes-kubeflow
FastML: Accelerate Model Building was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")