



Evolutionary Adversarial Attacks on Deep Networks
Last Updated on July 17, 2023 by Editorial Team
Author(s): Moshe Sipper, Ph.D.
Originally published on Towards AI.
Despite their uncontested success, recent studies have shown that Deep Neural Networks (DNNs) are vulnerable to adversarial attacks. A barely detectable change in an image can cause a misclassification in a well-trained DNN. Targeted adversarial examples can even evoke a misclassification of a specific class, for example, misclassifying a car as a cat. Researchers have demonstrated that adversarial attacks are successful in the real world and may be produced for data modalities beyond imaging, such as natural language and voice recognition. DNNs’ vulnerability to adversarial attacks has raised concerns about applying these techniques in safety-critical applications.
Consider these examples from our own work: three original images, shown beside a successful attack and an unsuccessful one (we’ll talk about how we generated the attacks momentarily). The original images were taken from three well-known datasets (top to bottom): ImageNet, CIFAR10, and MNIST. Note how rows look identical, especially the higher-resolution ones (MNIST has low resolution).

To discover effective adversarial instances and to defend against attacks, most works employ gradient-based optimization. Gradient computation can only be executed if the attacker is fully aware of the model architecture and weights. Thus, such approaches are only useful in a white-box scenario, where an attacker has complete access and control over a targeted DNN.
Attacking real-world AI systems, however, might be far more arduous. The attacker must consider the difficulty of implementing adversarial instances in a black-box setting, in which no information about the network design, parameters, or training data is provided. In this situation the attacker is able to access only the classifier’s input-output pairs.
We have recently employed evolutionary algorithms in a number of works within the field of adversarial deep learning. Evolutionary algorithms are a family of search algorithms inspired by the process of evolution in Nature. An evolutionary algorithm solves a problem by evolving an initially random population of candidate solutions, through the application of operators inspired by natural genetics and natural selection, such that in time fitter (that is, better) solutions to the problem emerge.
We first began using an evolutionary algorithm in pixel space — that is, the algorithm sought solutions in the space of images — in our paper: “An Evolutionary, Gradient-Free, Query-Efficient, Black-Box Algorithm for Generating Adversarial Instances in Deep Convolutional Neural Networks”.
Our algorithm, QuEry Attack (for Query-Efficient Evolutionary Attack), is an evolutionary algorithm that explores a space of images, defined by a given input image and a given input model, in search of adversarial instances. It ultimately generates an attacking image for the given input image. Unlike white-box approaches, we make no assumptions about the targeted model, its architecture, dataset, or training procedure.
The adversarial examples shown above were generated by QuEry Attack. Here’s another batch of adversarial examples our algorithm generated — for CIFAR10 images. Again, witness how the images look the same to us. But — not to the model!

Next, we looked at XAI, in “Foiling Explanations in Deep Neural Networks” . In order to render a deep network more interpretable, various explainable algorithms have been conceived. Van Lent et al. coined the term Explainable Artificial Intelligence (XAI), which refers to AI systems that “can explain their behavior either during execution or after the fact”. For safety-critical applications, interpretability is essential and sometimes even legally required.
The importance assigned to each input feature for the overall classification result may be observed through explanation maps, which can be used to offer explanations. Such maps can be used to create defenses and detectors for adversarial attacks.
We showed that these explanation maps can be transformed into any target map, using only the maps and the network’s output probability vector. This was accomplished by adding a perturbation to the input image that is scarcely (if at all) noticeable to the human eye. This perturbation has minimal effect on the neural network’s output. Therefore, in addition to the classification outcome, the probability vector of all classes remains virtually identical.
Our black-box algorithm, AttaXAI, enables manipulation of an image through a barely noticeable perturbation, without the use of any model internals, such that the explanation fits any given target explanation. AttaXAI explores the space of images through evolution, ultimately producing an adversarial image; it does so by continually updating a Gaussian probability distribution used to sample the space of perturbations. By continually improving this distribution, the search improves.
Here’s a schematic of the workings of AttaXAI:

And here’s a sample result. The explanation map of the dress is transformed by the attack to the explanation map of the leopard (or is it a cheetah?).

The primary objective has been achieved: having generated an adversarial image (x_adv), virtually identical to the original (x), the explanation map (g) of the adversarial image (x_adv) is now, incorrectly, that of the target image (x_target); essentially, the two rightmost columns are identical.
We then turned to physical attacks, which generate patches that not only work digitally but also in the physical world, that is, when printed — and used: “Patch of Invisibility: Naturalistic Black-Box Adversarial Attacks on Object Detectors”.
Given a pretrained GAN (Generative Adversarial Network) generator, we sought a latent input vector corresponding to a generated image that leads the object detector to err. We leveraged the latent space’s (relatively) small dimension, approximating the gradients using an evolutionary algorithm and repeatedly updating the input latent vector by querying the target object detector until an appropriate adversarial patch is discovered.
Here’s a general schematic of our approach:
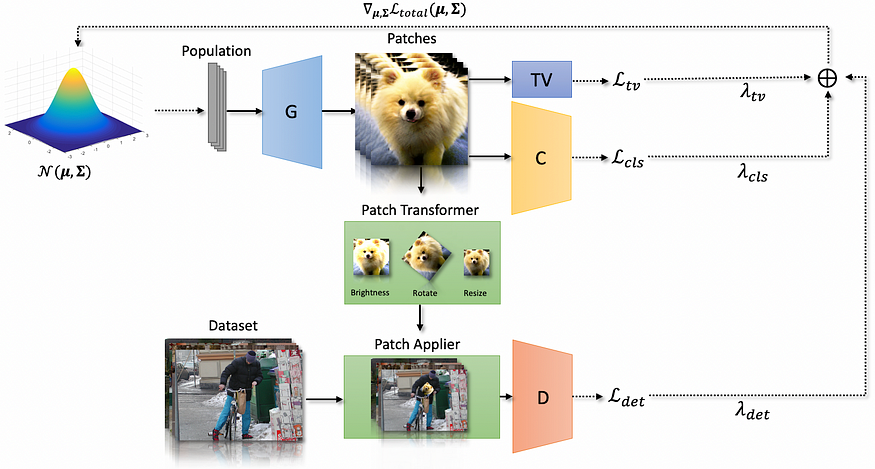
The patches we generated can be printed and used in the real world. We compared different deep models and concluded that is is possible to generate patches that fool object detectors. The real-world tests of the printed patches demonstrated their efficacy in “concealing’’ persons, evidencing a basic threat to security systems.
Below witnessed my talented grad student, Raz Lapid, standing beside his better half, showing how the evolved patch (printed, that is, physical) hides him from the deep learning model (no bounding box).

Given the ubiquity of deep models, adversarial attacks represent a real threat in sundry cases. Evolutionary techniques can help address many issues, and if your interest in them has been piqued, I invite you to read my post “Evolutionary Algorithms, Genetic Programming, and Learning”.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

