


Ensemble Learning: Bagging, Boosting, and Stacking
Last Updated on July 26, 2023 by Editorial Team
Author(s): Dhrubjun
Originally published on Towards AI.
“Alone we can do so little; together we can do so much.” — Helen Keller
In machine learning, bias and variance tradeoff is one of the key concerns for every practitioner while dealing with any algorithm. To tackle this tradeoff they can take advantage of some Ensemble Learning based techniques. It is based on the theory of ‘wisdom of crowds’ which assumes that the collective opinion of a diverse independent group of individuals is better than that of a single expert.
What are Ensemble Techniques ?
Ensemble techniques are the methods that use multiple learning algorithms or models to produce one optimal predictive model for better predictive performance.
Ensemble learning is a machine learning technique in which several models are combined to build a more powerful model. The ensemble is primarily used to improve the performance of the model. These techniques are some of the most useful machine learning techniques used nowadays as they exhibit great levels of performance at relatively low cost.
What are the types of Ensemble Techniques?
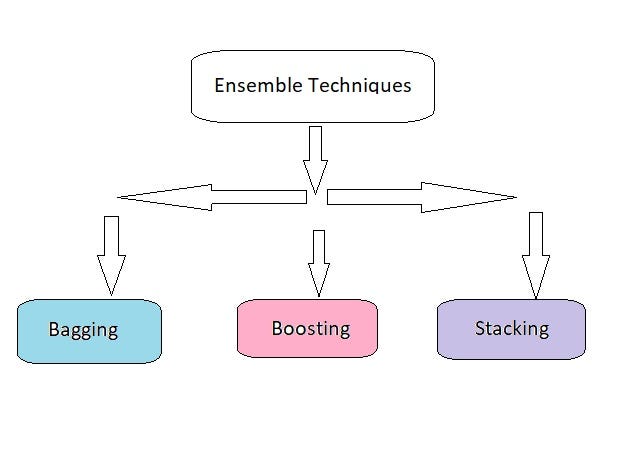
What are Bagging Techniques?
Bagging is a method where the results of multiple homogenous machine learning models (for instance, all Decision trees) are combined to get a generalized result.
But what happens when we try to create all the models on the same set of data and then combine it? Will it be useful? There is a high chance that these models will give the same result since they are getting the same input. Here comes the Bootstrapping technique, which is a random sampling technique in which we create subsets of the original dataset, with replacement. In statistics, random sampling with replacement is called bootstrapping.
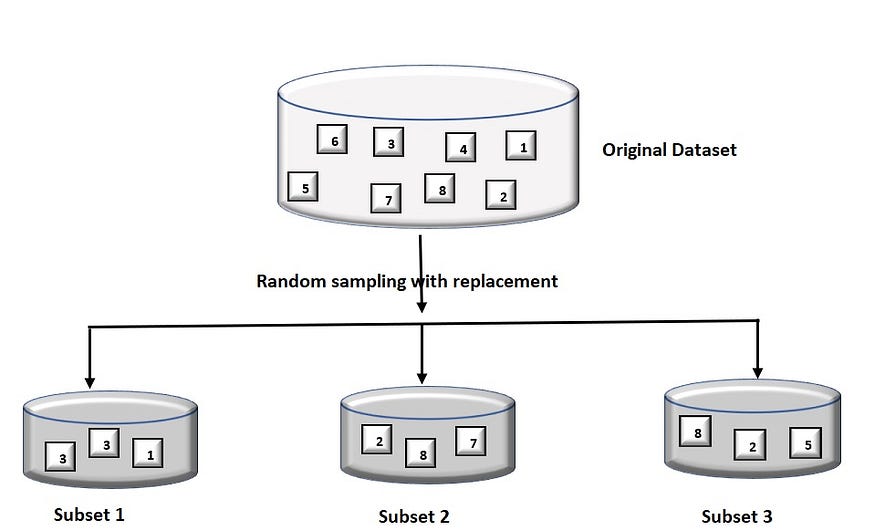
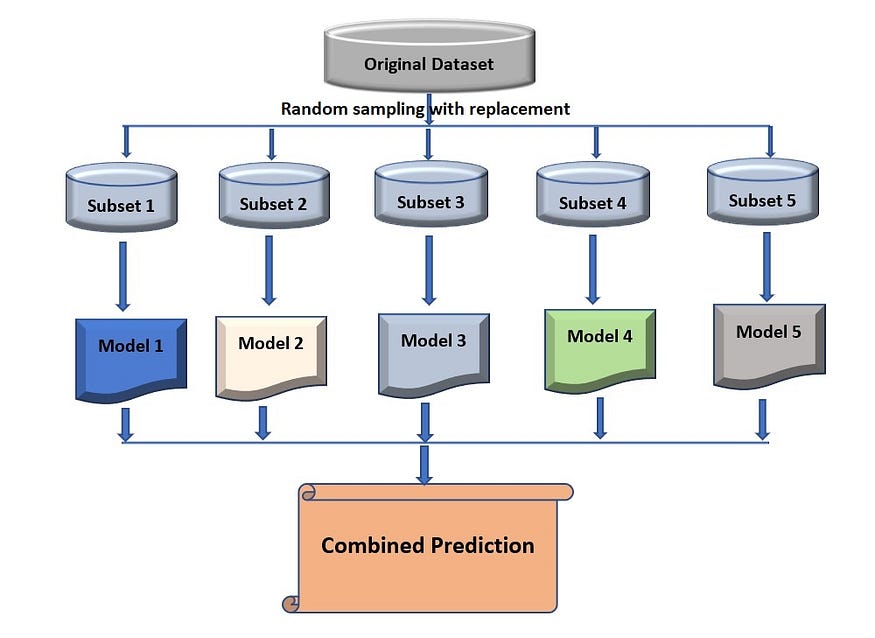
A base model (weak model) is created on each of these subsets. The models will run in parallel and are independent of each other. The final predictions are made by combining the predictions from all the models to build the meta-classifier or regressor. In the case of regression, it takes the mean or average of all the models and for the classification problems, it goes for the voting approach.
What is Boosting?
In bagging, we assumed that all the base models will give us the correct result or prediction. What happens when a data point is incorrectly predicted by a base model and then the next (probably all)? Will it be useful to combine all the predictions from the base models? Well, in that case, Boosting comes to rescue us.
Boosting is a sequential technique in which each subsequent model tries to improve the stability of the model by focusing on the errors made by the previous model. The succeeding models are dependent on the previous model.
The term ‘Boosting’ refers to a family of algorithms that combines a number of weak learners to form a strong learner.
Let’s consider the example of spam email identification. Here, to identify whether the mail is spam or not, the following criteria are usually used:
i. If the mail contains infected attachments or suspicious links, then its a SPAM.
ii. If the mail has only one image (promotional), it’s SPAM.
iii. If it contains sentences like “You have won a prize money of xxxxx” , its a SPAM
iv. If it is from a known source, then it’s not SPAM.
v. Mail from a known source, not SPAM.
To classify an email as SPAM or NOT SPAM, we have defined the above rules. Individually, these rules are not powerful enough to classify an email into ‘spam’ or ‘not spam’. Therefore, these rules are called weak learners. To convert weak learners to strong learners, we’ll combine the prediction of each weak learner using methods like:
a. Using average/weighted average
b. Considering prediction has higher votes.
For example, we have defined five weak learners. Out of these five, 3 are voted as SPAM, and 2 are voted as NOT SPAM. In that case, we will classify the mail as SPAM because we have the higher votes for SPAM.
Boosting is an iterative and sequential approach. It adaptively changes the distribution of training data after each iteration.
Steps in Boosting:
- A subset is created from the original dataset.
- Initially, all the data points are given equal weights, i.e. all the data points are considered equally likely for random sampling.
- A base model is trained on the randomly sampled subset.
- Errors are calculated using actual values and predicted values.
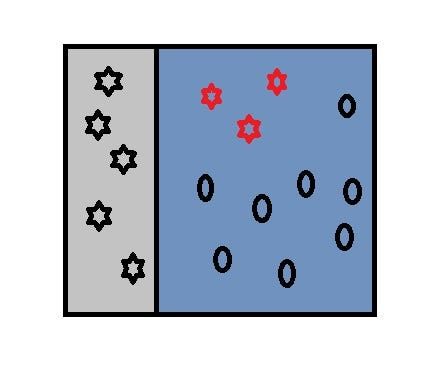
5. The observations which are incorrectly predicted, are given higher weights. (Here, the three misclassified red-star points will be given higher weights). These observations will be picked first on the next data sampling for the next model training because of their high weight, and then the rest are picked randomly if needed.
6. Another model will be created and predictions are made on the dataset. (This model tries to correct the errors from the previous model).
7. Similarly, multiple models will be created with updated weights, each correcting the errors of the previous model.
8. When all training processes of weak learners are done, they are combined together to form a strong learner. The final model (strong learner) is the weighted mean of all the models (weak learners).

What is the Stacking technique?
Stacking is an ensemble learning technique that uses predictions from multiple models (for example, decision tree, KNN or SVM) to build a new model. This model is used for making predictions on the test set.
The steps for a simple stacking ensemble learning technique are as follows:
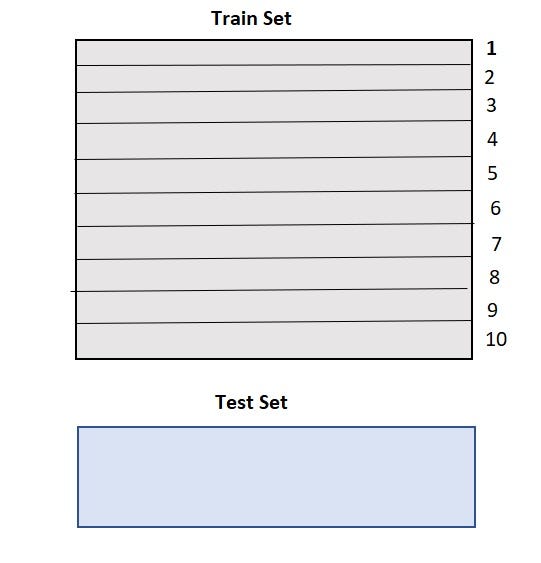
- The train set is split into 10 parts.
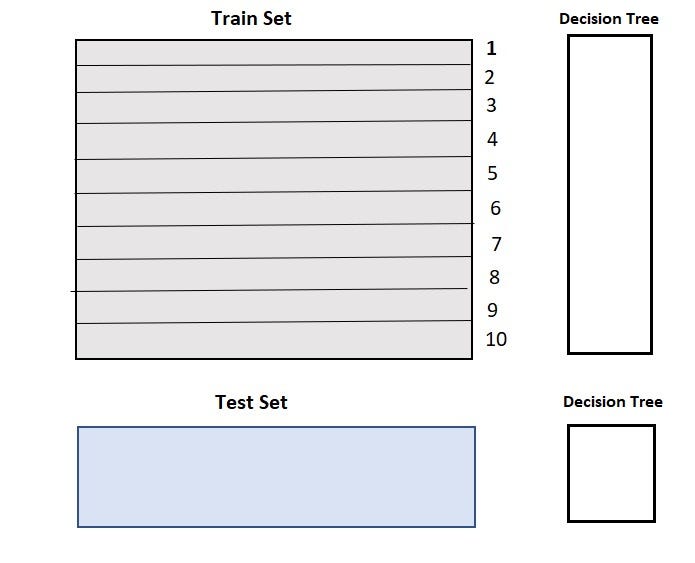
2. A base model (suppose a decision tree) is fitted on 9 parts and predictions are made for the 10th part. This is done for each part of the train set.

3. The base model (in this case, decision tree) is then fitted on the whole train dataset.
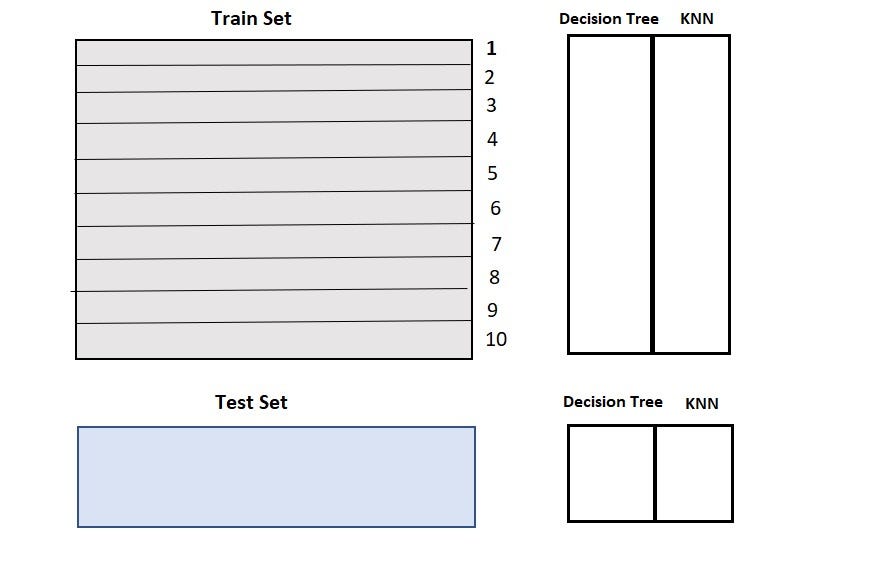
4. Steps 2 to 4 are repeated for another base model (say KNN) resulting in another set of predictions for the train set and test set.
5. The predictions from the train set are used as features to build a new model.
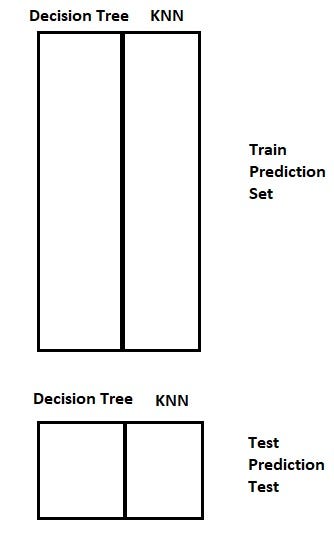
6. This model is used to make final predictions on the test prediction set.
Difference between Bagging and Boosting:
- Bagging aims to decrease variance, not bias. But boosting tries to decrease bias, not variance.
- Bagging tries to solve the over-fitting problem. Boosting for its part doesn’t help to avoid over-fitting; in fact, this technique is faced with this problem itself.
- In the case of bagging, each model is built independently. But in the case of boosting, each new model is influenced by the performance of the previously built model.
- In bagging, different training data subsets are drawn randomly with replacements from the entire training data set. But, in the case of boosting, every new subset contains the elements that were misclassified by the previous model.
- If the classifier is unstable (high variance), then we should apply bagging. Whereas, if the classifier is stable and simple (high bias), we should go for boosting.
That’s all for today. Hope you like the article. Happy reading!!!
Mlearning.ai Submission Suggestions
How to become a writer on Mlearning.ai
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

