



Explaining AI for High Resolution Images
Last Updated on January 6, 2023 by Editorial Team
Author(s): Joseph Early
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Explaining AI for High-Resolution Images
AI can be used to make automated decisions based on high-resolution images, but can we understand those decisions? In this article, I discuss how interpretable multiple instance learning can be used to tackle this problem.
Modern computer vision datasets can contain millions of images. However, these images are often small in size. For example, in ImageNet [1], the average image is only 469 x 387 pixels. But what if each image is over 10,000 x 10,000 pixels in size? Or over 100,000 x 100,000?
In this article, I explore how AI can be adapted for use with high-resolution images, and then discuss methods for explaining how these AI models make decisions.
High-Resolution Data
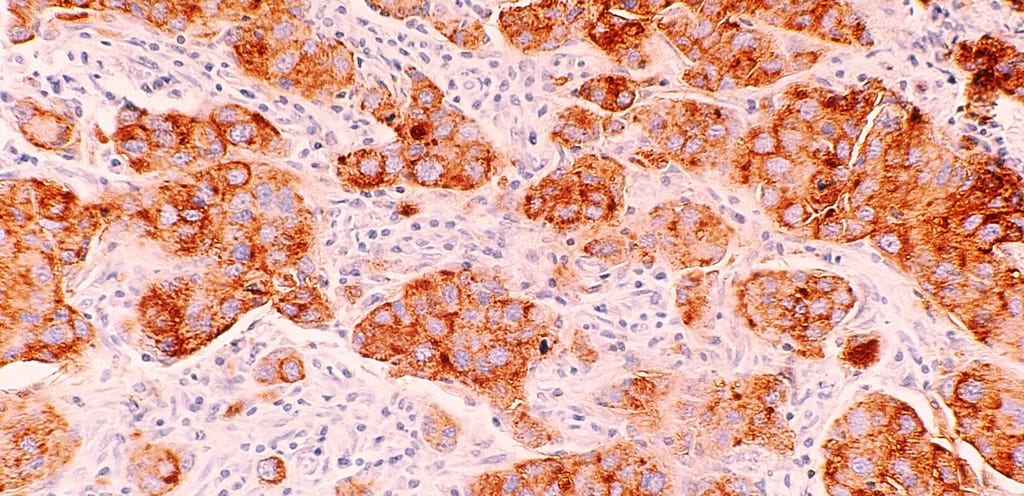
Before I delve into how machine learning can be applied to high-resolution imagery, it’s worth discussing what kinds of data actually exist in this domain. I have given two examples in the images above, and talk about them further below:
Satellite data — There is an increasing amount of data being collected from space by observing the Earth with satellites. The amount of data being gathered is huge; well over 100 Terabytes per day. The data this is collected is often very high resolution, and can also have multiple spectral bands (e.g., infra-red as well as visible light).
Medical data — Certain types of medical data are high resolution. For example, tissue samples from the body can be stained and examined under a microscope. These samples can then be digitized to produce whole slide images (WSIs), which are very high resolution (100,000 x 100,000 pixels!).
In both of these example cases, processing the high-resolution images is impossible for conventional computer vision methods, because:
- If the images are kept at their original resolution, the machine learning models become too large to train. This is because the number of parameters in the model scales with the size of the input images.
- If the images are resampled to be smaller, important information is often lost. For example, in WSI data, the individual cells will not be identifiable if the image is down-sampled. Or in satellite data, resolving features such as individual buildings will be impossible.
So, how do we solve this problem? In the next section, I discuss a popular approach known as multiple instance learning.
Multiple Instance Learning for High-Resolution Images
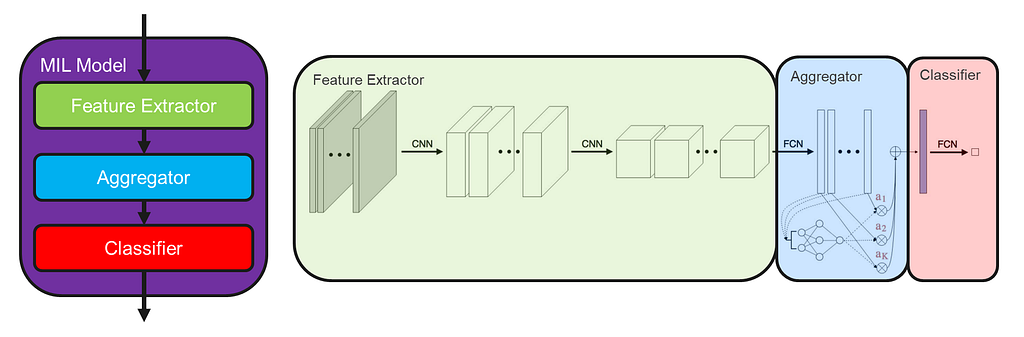
In multiple instance learning (MIL), data is organized into bags of instances. For high-resolution images, this takes the form of splitting the original high-resolution image into smaller image patches. However, MIL only requires labels on the bag label. This means we don’t have to label every single instance, which saves a lot of time and money. Below is a short animation that explains the process in more detail.
The upshot of using MIL for high-resolution imagery is that it deals with both of the problems highlighted above. First, as the model is now only processing smaller patches, the number of model parameters is far less. This makes it possible to actually train the model. Second, the patches that are extracted preserve the fine detail that is captured in the original high-resolution image, so no information is lost.
Given that MIL is a suitable approach for applying machine learning to high-resolution images, how can we understand how trained models make decisions?
Interpreting Multiple Instance Learning
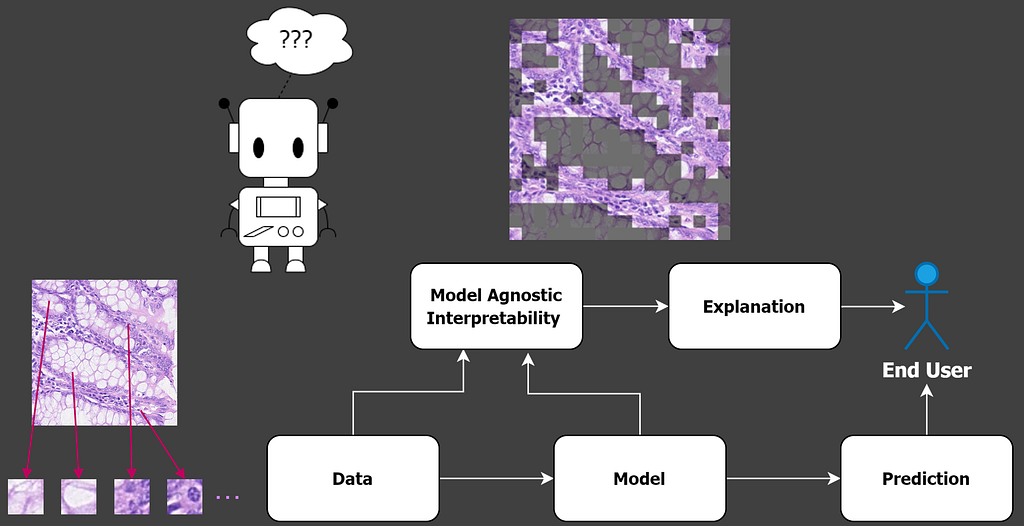
Understanding how MIL models make a decision is an area of research that I’ve recently been working on [3], leading to a new method: Multiple Instance Learning Local Interpretations (MILLI). I approached this from a model-agnostic standpoint. This means no assumptions were made about the underlying MIL model. As such, my methods are applicable to any type of MIL model; current or future.
In general, the aim of interpretable MIL is to understand two objectives:
- Which are the important instances in a bag? These are the instances that are being used to make decisions.
- What outcomes do these instances support? Different instances can support different outcomes, so solely identifying the key instances does not provide a full explanation.
For high-resolution images, answering both of these questions can be achieved by highlighting the important patches in the image that support different outcomes. For example, digital histopathology could be identifying different types of cell nuclei that indicate the risk of cancer [4]. The explanation of decision-making is then provided alongside the model’s prediction. This can be used to inform an end-user of why a particular decision has been reached, facilitating trust in the model.
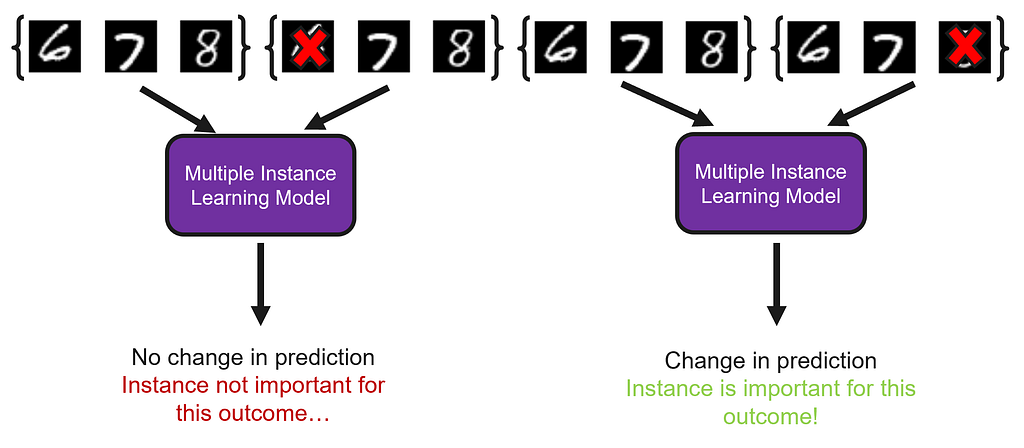
MILLI allows us to understand how MIL models make decisions by exploiting a common property of all MIL models. As MIL bags don’t have to be the same size (i.e., they can have different numbers of instances per bag), all MIL models, by design, have to be able to process bags of different sizes. This means we are able to remove instances from the bags and still make predictions, a property that is unique to MIL (in non-MIL models it is impossible to simply remove features). By removing instances and observing the change in prediction, it is possible to build up a picture of which instances drive the model’s decision-making, and what outcomes those instances support.
Approaching interpretable MIL in this way is much more effective than existing approaches. These existing approaches include certain types of MIL models that are inherently interpretable. As part of their processing, these models produce their own interpretations of decision-making. For example, this can include making instance predictions as well as bag predictions [5] or assigning values to indicate how much attention the model is paying to each instance [2]. Not only are the interpretations provided by MILLI more effective and accurate than the inherently interpretable models, MILLI is model agnostic, meaning it is applicable to any type of MIL model. Conversely, the inherently interpretable approaches only work for specific types of models, limiting their applicability.
Summary
High-resolution images cannot be processed using conventional machine learning techniques. Instead, a special approach known as multiple instance learning can be used. New techniques allow us to understand how trained multiple instance learning models use data to make decisions, and provide explanations of decision-making to end-users.
References
[1] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A
large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, IEEE, 2009.
[2] M. Ilse, J. Tomczak, and M. Welling, “Attention-based deep multiple in-
stance learning,” in International Conference on Machine Learning, pp. 2127–
2136, PMLR, 2018.
[3] J. Early, C. Evers, and S. Ramchurn, “Model agnostic interpretability for
multiple instance learning,” in International Conference on Learning Representations, 2022.
[4] K. Sirinukunwattana, S. E. A. Raza, Y.-W. Tsang, D. R. Snead, I. A. Cree,
and N. M. Rajpoot, “Locality sensitive deep learning for detection and classification of nuclei in routine colon cancer histology images,” IEEE Transactions on Medical Imaging, vol. 35, no. 5, pp. 1196–1206, 2016.
[5] X. Wang, Y. Yan, P. Tang, X. Bai, and W. Liu, “Revisiting multiple instance
neural networks,” Pattern Recognition, vol. 74, pp. 15–24, 2018
Explaining AI for High Resolution Images was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

