



Encoding Categorical Data- The Right Way
Last Updated on October 18, 2022 by Editorial Team
Author(s): Gowtham S R
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Table of Contents
· Types of Data
∘ Continuous Data
∘ Discrete Data
∘ Nominal Data
∘ Ordinal Data
· How to Encode Categorical data?
∘ Ordinal Encoding
∘ Nominal Encoding
∘ OneHotEncoding using Pandas
∘ Dummy Variable Trap
∘ OneHotEncoding using Sklearn
Types of Data
In statistics and machine learning, we classify data into one of two types namely — Numerical and Categorical
Numerical data is categorized into discrete and continuous data. Categorical data is divided into two types, nominal data, and ordinal data.
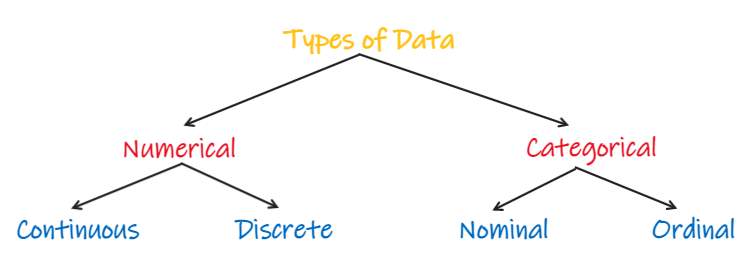
Continuous Data
Continuous data is data that takes any number(it can include decimal values). It has an infinite number of probable values that can be selected within a given specific range.
Example: Weight and height of a person, temperature, age, distance.

Discrete Data
Discrete data can take only discrete values(it can not have decimal values). Discrete information contains only a finite number of possible values. Those values cannot be subdivided meaningfully. Here, things can be counted in whole numbers.
Example: Number of people in a family, number of bank accounts a person can have, number of students in a classroom, number of goals scored in a football match.

How Should We Detect and Treat the Outliers?
Nominal Data
Nominal data is defined as data that is used for naming or labeling variables without any quantitative value. It is sometimes called “named” data.
There is usually no intrinsic ordering to nominal data. For example, Gender is a nominal variable having 2 categories, but there is no specific way to order from highest to lowest and vice versa.
Examples: letters, symbols, words, gender, color, etc.

Ordinal Data
Ordinal data is a type of data that follows a natural order. It is a type of categorical data with an order. The variables in ordinal data are listed in an ordered manner.
Examples: Customer rating(Good, Average, Bad), Medal category in Olympics(Gold, Silver, Bronze)

Simple ways to write Complex Patterns in Python in just 4mins.
How to Encode Categorical data?
Encoding categorical data is a process of converting categorical data into integer format so that the data can be provided to different models.
Categorical data will be in the form of strings or object data types. But, machine learning or deep learning algorithms can work only on numbers. So, being machine learning engineers, it is our duty to convert categorical data to numeric form.
Ordinal Encoding
We need to maintain the intrinsic order while converting ordinal data to numeric data. So, each category will be given numbers from 0 to a number of categories. If we have 3 categories in the data, such as 'bad', 'average', and 'good', then bad will be encoded as 0, average as 1, and good as 2. So that the order is maintained.
When we train the machine learning model, it will learn the pattern with the intrinsic order giving better results.
We make use of OrdinalEncoder class from sklearn to encode the ordinal data.

Standardization vs Normalization
Let us see how we can encode ordinal data practically.
import pandas as pd
import numpy as np
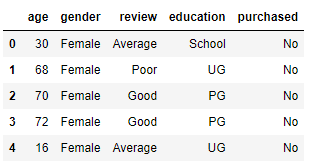
df = pd.read_csv('customer.csv')
df.head()
df['age'].unique()
array([30, 68, 70, 72, 16, 31, 18, 60, 65, 74, 98, 51, 57, 15, 75, 59, 22,19, 97, 32, 96, 53, 69, 48, 83, 73, 92, 89, 86, 34, 94, 45, 76, 39,23, 27, 77, 61, 64, 38, 25], dtype=int64)
df['gender'].unique()
array(['Female', 'Male'], dtype=object)
df['review'].unique()
array(['Average', 'Poor', 'Good'], dtype=object)
df['education'].unique()
array(['School', 'UG', 'PG'], dtype=object)
df['purchased'].unique()
array(['No', 'Yes'], dtype=object)
‘age’ — numerical data
‘gender’ — nominal categorical data
‘review’ — ordinal categorical data
‘education’ — ordinal categorical data
‘purchased’ — the target variable
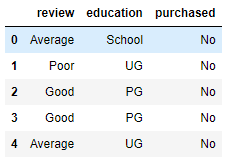
Let us separate ordinal data and learn how to encode them.
df = df.iloc[:,2:]
df.head()
X = df.iloc[:,0:2]
y = df.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size =0.2, random_state=1)
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder(categories=[['Poor','Average','Good'],['School','UG','PG']])
ordinal_encoder.fit(X_train)
X_train = ordinal_encoder.transform(X_train)
X_test = ordinal_encoder.transform(X_test)
In the above code, we can see that we are passing the categories in the order to the ordinalEncoder class, with poor being the lowest order and Good being the highest order in the case of feature review.
Similarly, in the case of the education column, school is the lowest order, and PG is in the highest order.
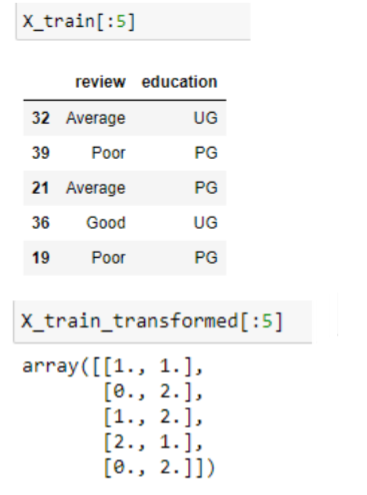
After transformation, we can observe the above result, which shows the first 5 rows.
The first row had review = Average and education = UG, so it is transformed as [1,1]
The second row had review = Poor and education = PG, so it is transformed as [0,2]
Nominal Encoding
Nominal data will not have intrinsic order, we make use of OneHotEncoder class from sklearn to encode the nominal data.
If we start encoding categories from 0,1,2 to all the categories, then the machine learning algorithm will give importance to 2 (more than 0 and 1), which will not be true as the data is nominal and will have no intrinsic order. So, this method will not work in the case of nominal data.
Here each of the categories will be transformed into a new column and will be given values of 0 or 1 depending on the occurrence of the respective category. So, the number of features will increase after the transformation.

Let us see how we can encode nominal data practically. Let us take a titanic dataset with features ‘Sex’ and ‘Embarked’ (both are nominal features).
import pandas as pd
import numpy as np
df = pd.read_csv('titanic.csv')
df.head()
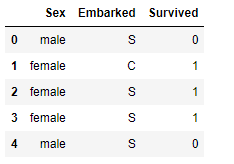
df['Sex'].unique()
array(['male', 'female'], dtype=object)
df['Embarked'].unique()
array(['S', 'C', 'Q'], dtype=object)
df['Survived'].unique()
array([0, 1], dtype=int64)
OneHotEncoding using Pandas
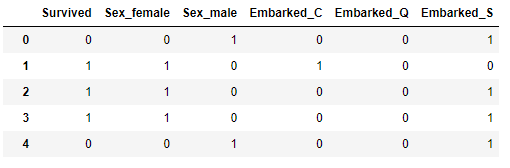
pd.get_dummies(df,columns=['Sex','Embarked'])
The below output shows how each of the categories is transformed into a column. The column ‘Sex’ has got transformed into ‘Sex_female’ and ‘Sex_male’ and the column ‘Embarked’ has got transformed into ‘Embarked_C’, ‘Embarked_Q’, and ‘Embarked_S’.
These new attributes/columns created are called Dummy Variables.
Dummy Variable Trap:
The Dummy variable trap is a scenario where there are attributes that are highly correlated (Multicollinear), and one variable predicts the value of others. When we use one-hot encoding for handling the categorical data, then one dummy variable (attribute) can be predicted with the help of other dummy variables. Hence, one dummy variable is highly correlated with other dummy variables.
Using all dummy variables for models leads to a dummy variable trap (Some of the machine learning algorithms, like Linear Regression, Logistic Regression suffer from multicollinearity)
Why Is Multicollinearity A Problem?
For Example —
Let’s consider the case of gender having two values male (0 or 1) and female (1 or 0). Including both dummy variables can cause redundancy because if a person is not male in such case, that person will be female, hence, we don’t need to use both variables in regression models. This will protect us from the dummy variable trap.
How do I Verify the Assumptions of Linear Regression?
So, the models should be designed to exclude one dummy variable. Usually, we drop the first variable as shown below.
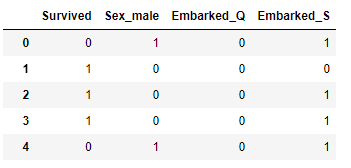
pd.get_dummies(df,columns=[‘Sex’,’Embarked’],drop_first=True)
The result shows that the first variable has been dropped. Sex_female and Embarked_C are the two columns dropped from the result.
OneHotEncoding using Sklearn
We can use OneHotEncoder class from sklearn to perform the above steps.
X = df.iloc[:,0:2]
y = df.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1)
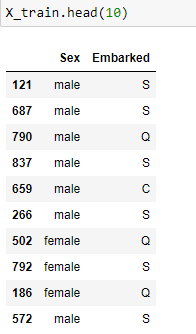
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='first',sparse=False,dtype=np.int32)
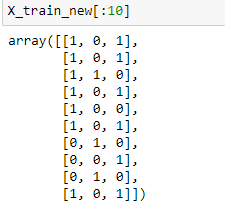
X_train_new = ohe.fit_transform(X_train)
X_test_new = ohe.transform(X_test)
Note that new features will be created according to alphabetical order. In the given an example ‘Sex’ column was transformed to Sex_female and Sex_male alphabetically, and the female got dropped as it was the first column.
And In the ‘Embarked’ feature, Embarked_C, Embarked_Q, and Embarked_S were the new columns according to alphabetical order, and category ‘C’ has got dropped, so the array [0,0] will represent C. [1,0] represents ‘Q’ and [0,1] represents ‘S’.
5 Regression Metrics Explained in Just 5mins
Encoding Categorical Data- The Right Way was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



