



EfficientNet — An Elegant, Powerful CNN.
Last Updated on October 1, 2022 by Editorial Team
Author(s): Leo Wang
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
EfficientNet — An Elegant, Powerful CNN.
No Fancy Techniques but worked extremely well.
OUTPERFORMED ResNet, ResNeXt, DenseNet, InceptionNet, SENet, AmoebaNet, and is MORE EFFICIENT.
📖 Table of Contents
· ⭐ ️Introduction
· ⭐Intuition
· ⭐ Compound Scaling Method
∘ ⭐ MBConv Block
· ⭐ Performances
· Implementation
· References
⭐ ️Introduction
Being efficient is, in layman’s terms, the ability to achieve a good result without a high cost.
While state-of-the-art (SOTA) deep learning models strive for higher performances, they are at the same time becoming more costly to train as well.
However, sometimes we don’t even need that 2100M+ number of parameters in order to achieve the same result. We just need to find a way to be more efficient.
⭐Intuition
In neural networks, there are several properties:
- Depth (d): Number of layers (including output but excluding input. E.g., 101). The deeper the network is, the more likely it will experience exploding or vanishing gradients, but it would be more complex and maybe more performant.
- Width (w): Highest number of convolution kernels (channels). As pointed out by Zagoruyko and Komodakis, “wider networks tend to be able to capture more fine-grained features and are easier to train.” However, a model too wide and too shallow would have difficulties in capturing higher-level features (e.g., 1024).
- Resolution (r): Input image’s dimension (image height * image width. e.g. 256 x 256). The higher the resolution, the more likely CNNs will be to capture fine-grained patterns, but the accuracy gain diminishes for very high resolutions (e.g., 560 x 560)).
In 2020, Tan et al. found that most of the existing network architectures, such as ResNet, usually develop their baselines first and then scale up by simply increasing depth (number of layers), such as from ResNet-18 to ResNet-200. Other networks may scale up other properties randomly.
However, EfficientNet authors pointed out that it is wrong. Specifically, such arbitrary scaling requires tedious manual tuning and often results in sub-optimal efficiency.
❗️Also, scaling up any properties (width, depth, resolution) improves accuracy, but the accuracy gain diminishes for bigger models.
The authors found out that there is a fixed relationship between those networks’ properties (which will be elaborated on), and there is a much more efficient way to scale up the network, so people would worry less about using a bulky model but bad performance.
The method is Compound Scaling Method.
⭐ Compound Scaling Method
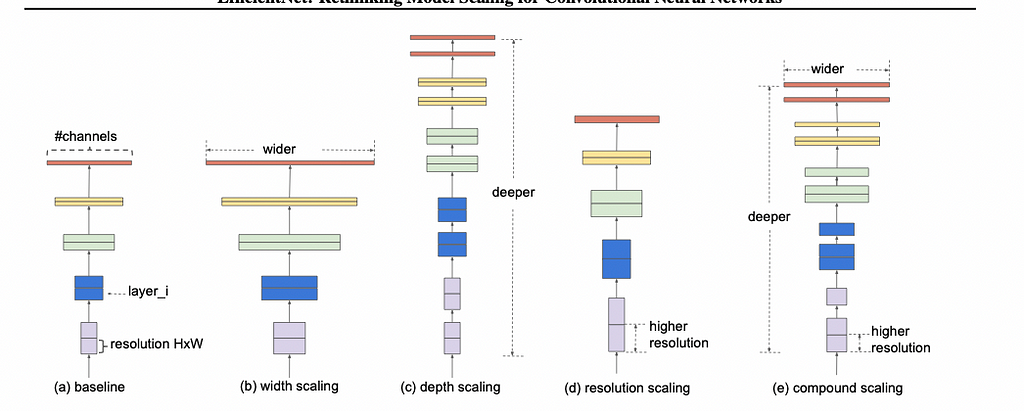
Different network properties are interdependent on each other. For example, when increasing the resolution of the model (input dimensions), the depth and width should also be increased to exploit more information from the picture (larger receptive field) and capture more fine-grained patterns with more pixels.
However, how should other properties change in response to one property’s change?
Nothing is more direct than seeing some maths. Don’t worry. I’ll make sure you are reading plain English.
Let’s assume:
- Depth = d^ϕ
- Width = w^ϕ
- Resolution = r^ϕ
d, w, r are constants, and they are optimized by doing a random grid search while fixing ϕ=1, and are constrained such that
- d * w²* r² ≈ 2
- d ≥ 1, w ≥ 1, r ≥ 1
🔥 So now, to scale up, you just need to change only the value of ϕ. You do not need to tune properties like depth, width, and resolution at the same time anymore. 🔥
They designed the equation so that for any values of ϕ, the total FLOPS (floating point operations per second, here measuring the speed of training) would approximately increase by 2^ϕ.
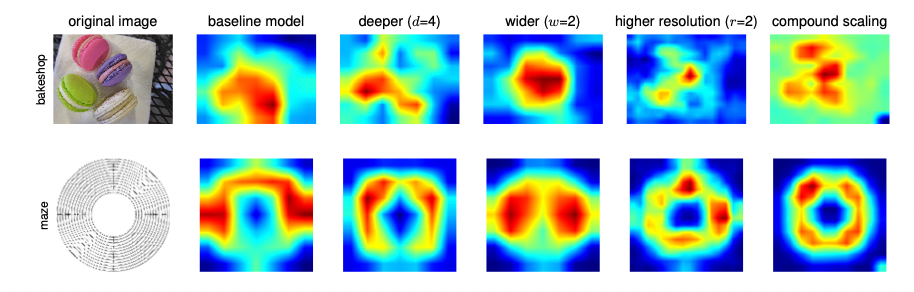
Fig. 3 shows the model’s attention changes drastically by varying the model’s different properties, but only the compound scaling shows that the model has the “most correct” attention.
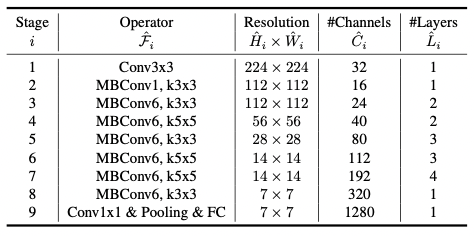
Knowing d, w, and r, EfficientNet-B0 is proposed.
MBConv is an inverted residual bottleneck block with depth-wise separable convolution. Let me explain this in detail first.
⭐ MBConv Block
Conventionally, a 3×3 convolution operation is simply just running a kernel with (3,3) size on input with depth D1 and producing an output with depth D2.
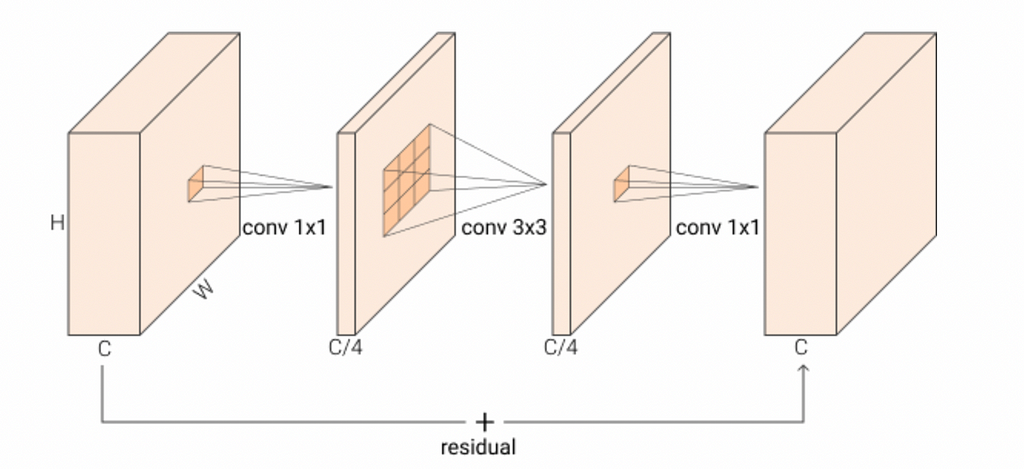
However, for a normal residual bottleneck block, the input’s depth is reduced first through a 1×1 convolution. Then, a 3×3 convolution is applied to the reduced-depth input. Finally, the depth is re-expanded through the 1×1 convolution. The graphical illustration is shown in Fig. 4.
This fancy operation is called depth-wise separable convolution. Indeed, it separates the simple 3×3 convolution into the1x1 compression, 3×3 on the compressed, 1×1 expansion process.
Then, the initial and the ending feature maps are added to the network can learn more diverse features.
This fancy operation uses significantly fewer parameters and is more efficient in computation.
For an inverted residual block, the depth changing scheme is “inverted,” as shown in Fig. 6. So, from Wide → Narrow → Wide to Narrow → Wide → Narrow.
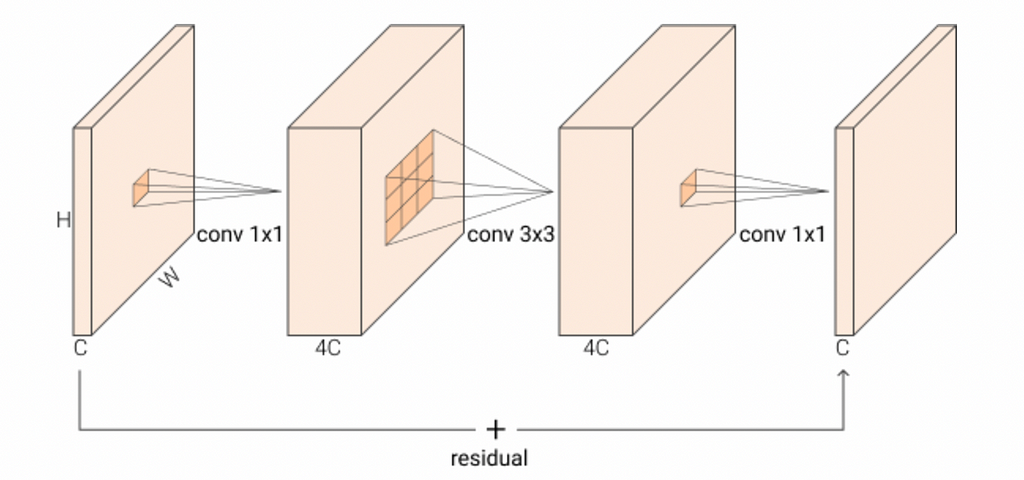
The inverted version is proven to work better and is more memory efficient because it can now remove the non-linearities in the narrow layers to have better representation power (I know it sounds hard to understand the reason, so if you don’t, don’t worry about it).
⭐ Performances
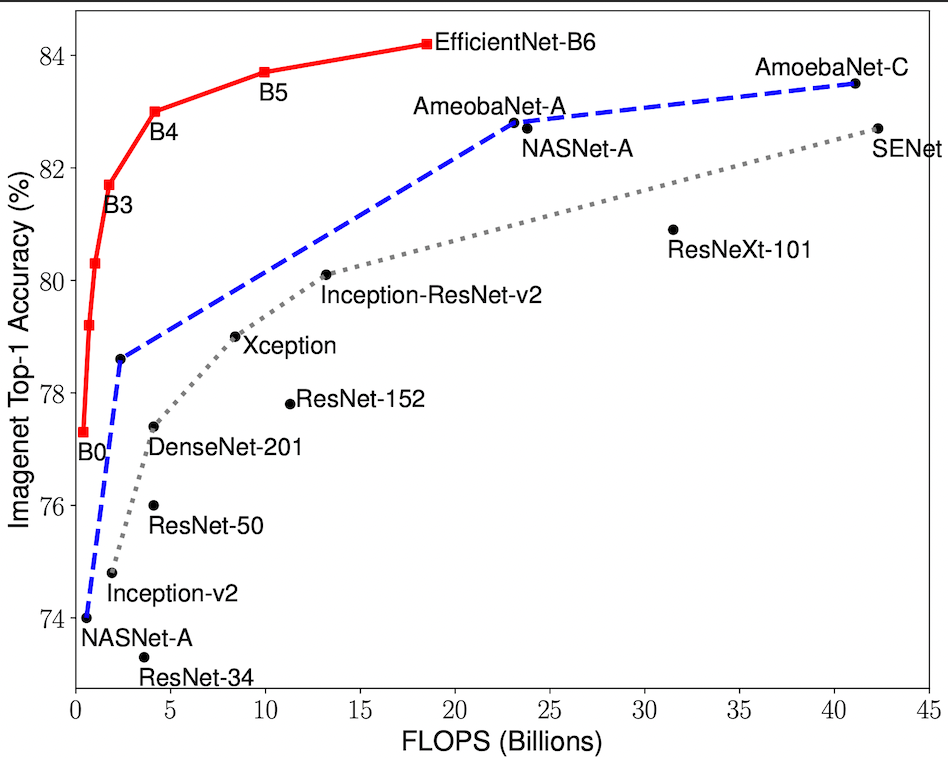
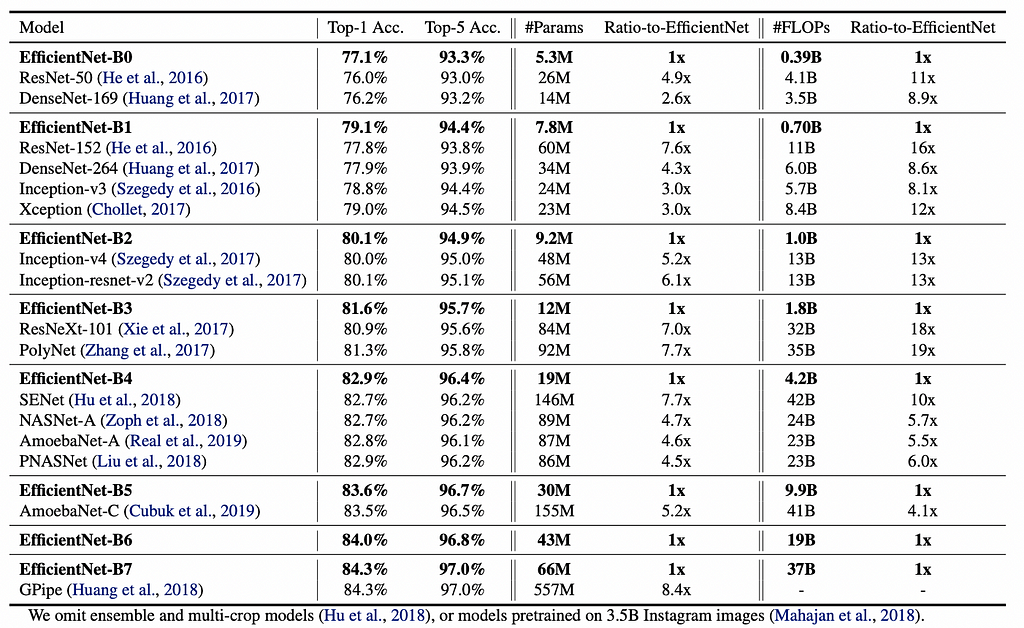
EfficientNet B0 to B7 achieved superior performances.
Fig. 7 shows the detailed performance data of EfficientNet-B0 to EfficientNet-B7 compared to other models. As you can see, EfficientNet has achieved both speed and performance. That’s why it is “efficient.”
However, EfficientNet is taken even further. Next, we are going to talk about EfficientNetV2, which is even more powerful.
Thank you! ❤️
May we plead you to consider giving us some applauds! ❤️
Implementation
Official EfficientNet implementation in TensorFlow
References
[1] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
[2] MobileNetV2: Inverted Residuals and Linear Bottlenecks
[3] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[4] https://python.plainenglish.io/implementing-efficientnet-in-pytorch-part-3-mbconv-squeeze-and-excitation-and-more-4ca9fd62d302
Mlearning.ai Submission Suggestions
EfficientNet — An Elegant, Powerful CNN. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


