


 in Image Segmentation")
Explained: Reverse Attention Network (RAN) in Image Segmentation
Last Updated on October 1, 2022 by Editorial Team
Author(s): Leo Wang
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Table Of Contents
· ⭐️ Problems
· ⭐️ A Solution
· ⭐ ️Reverse Attention Network (RAN)
∘ Reverse Branch (RB)
∘ Reverse Attention Branch (RAB)
∘ Combine the result
· ⭐️ Training
· ⭐️ Performance
· Citation
⭐️ Problems
- Most CNN-based semantic segmentation methods focus on simply getting the predictions right without mechanisms teaching the model to discern the difference between classes. (so characteristics of less common classes might be ignored)
- High-level features are shared in different classes due to the visual similarity among classes, which may yield confusing results in regions containing the boundaries of different classes (e.g., background with an object because they have similar activation strength) or when they are mixed together.
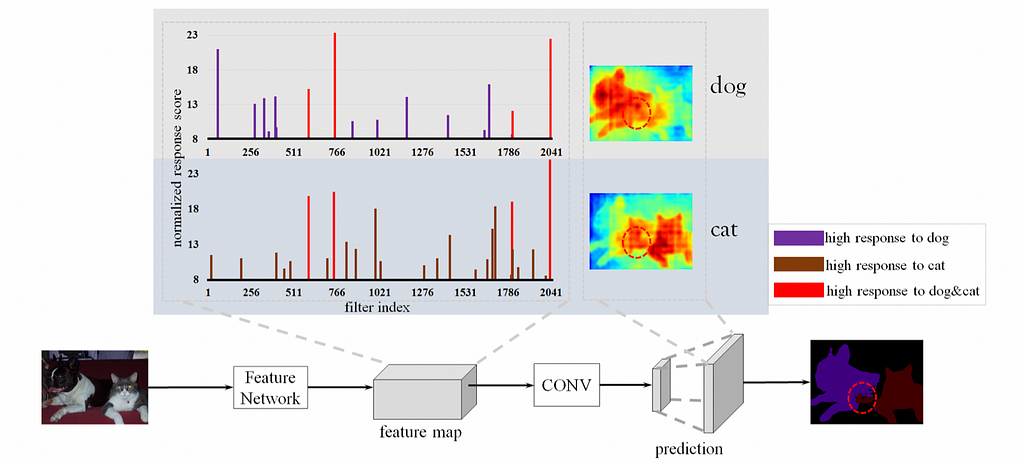
To have a better understanding of the problem, please see Fig. 1. As seen from the attention heatmap, it is obvious that most nowadays encoder-decoder models would have strong neural activations on parts that two objects are “mixed” together (aka. have obscure boundaries or regions where 2+ objects share similar spatial patterns), where the model should not pay too much attention on those “mixed” parts during predictions at all.
⭐️ A Solution
- The authors devised a mechanism to identify those mixed special regions and amplify the weaker activations to capture the target object, so the network learns not only to discern the background class but also learns to discern different objects all present in the image.
Therefore, they proposed a novel architecture and dubbed it“Reverse Attention Network” (RAN) to address the aforementioned problems.
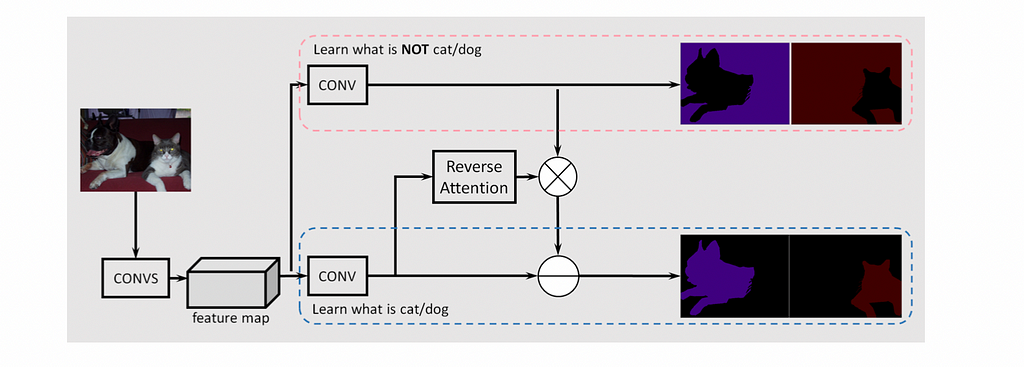
In RAN, there are two different branches (one circled in red and one circled in blue) designed to learn background features and the object’s features, respectively.
To further highlight the knowledge learned from the object class, a reverse attention structure is designated to generate per-class masks to amplify the object class’s activations in the confused region.
Lastly, the predictions are fused together to yield the final prediction.
⭐ ️Reverse Attention Network (RAN)
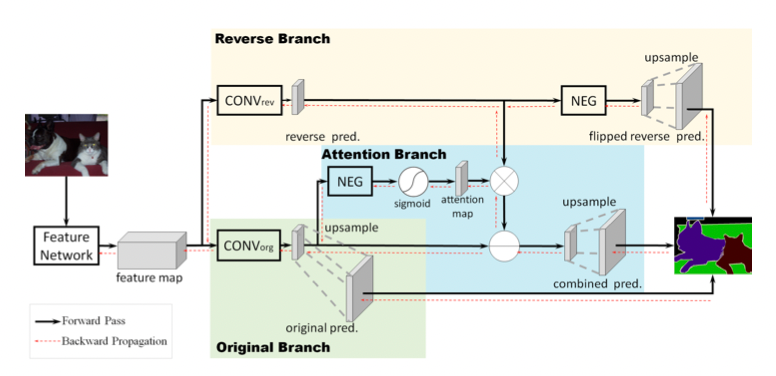
To have a more detailed understanding of the proposed model, please see Fig. 3.
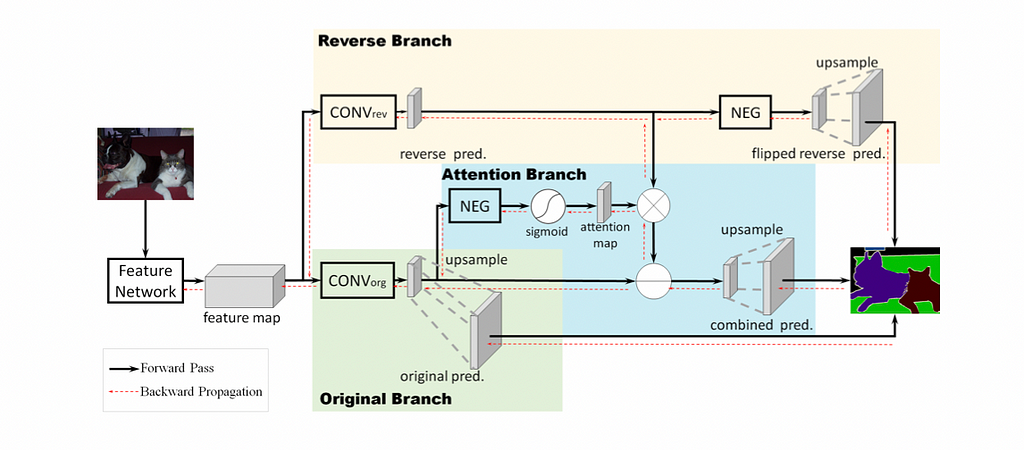
To break down the process into a few steps after the input image is given:
- A feature map is generated using a selected model architecture (Usually ResNet-101 or VGG16, but it can vary) to learn object features.
- Then, the map is split into two branches.
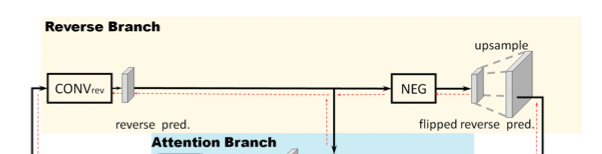
Reverse Branch (RB)
- Colored in yellow, the model first trains a CONV_rev layer to learn the “reverse object class” explicitly (the reverse object class is the reversed ground truth for the object class).
- In order to get the reverse object class, the background and other classes are set to 1, while the object class is set to 0.
- When it is a multi-class segmentation problem, however, an alternative is commonly used by reversing the sign of all class-wise activations (the NEG block) before feeding to the softmax-based classifier. This approach allows the CONV_rev layer to be trained using the same class-wise ground-truth label.
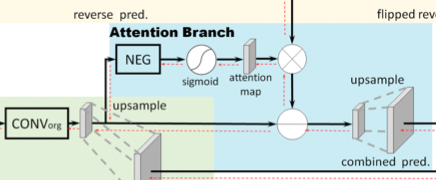
Reverse Attention Branch (RAB)
- Instead of directly applying element-wise subtractions to the original prediction by the activations of the reverse branch due to worse performance, the Reverse Attention Branch is proposed to highlight the regions overlooked by the original prediction (including mixed and background areas). The output of reverse attention would generate a class-oriented mask to amplify the reverse activation map.
- As shown in Fig. 3 and Fig. 5, the initial feature map from the input image is fed into the CONV_org layer.
- Then, the resulting feature map’s pixel values are flipped by the NEG block.
- Then, the sigmoid function is applied to convert pixel values between [0, 1], before feeding the feature map to the attention map, where an attention mask is applied.
- The aforementioned steps could be summarized into Formula 1, where i, j indicate the pixel location.
- Therefore, the region with small or negative responses will be highlighted by NEG and the sigmoid operations, but the areas of positive activations (or confident scores) will be suppressed in the reverse attention branch.
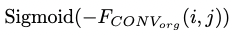
Combine the result
- Then, the map from the Reverse Attention Branch is element-wise-ly multiplied by the Reverse Branch. The resulting map is subtracted from the original prediction to generate the final prediction.
⭐️ Training
This is beyond the scope of this article, so we would just show you the original text from the paper:

⭐️ Performance
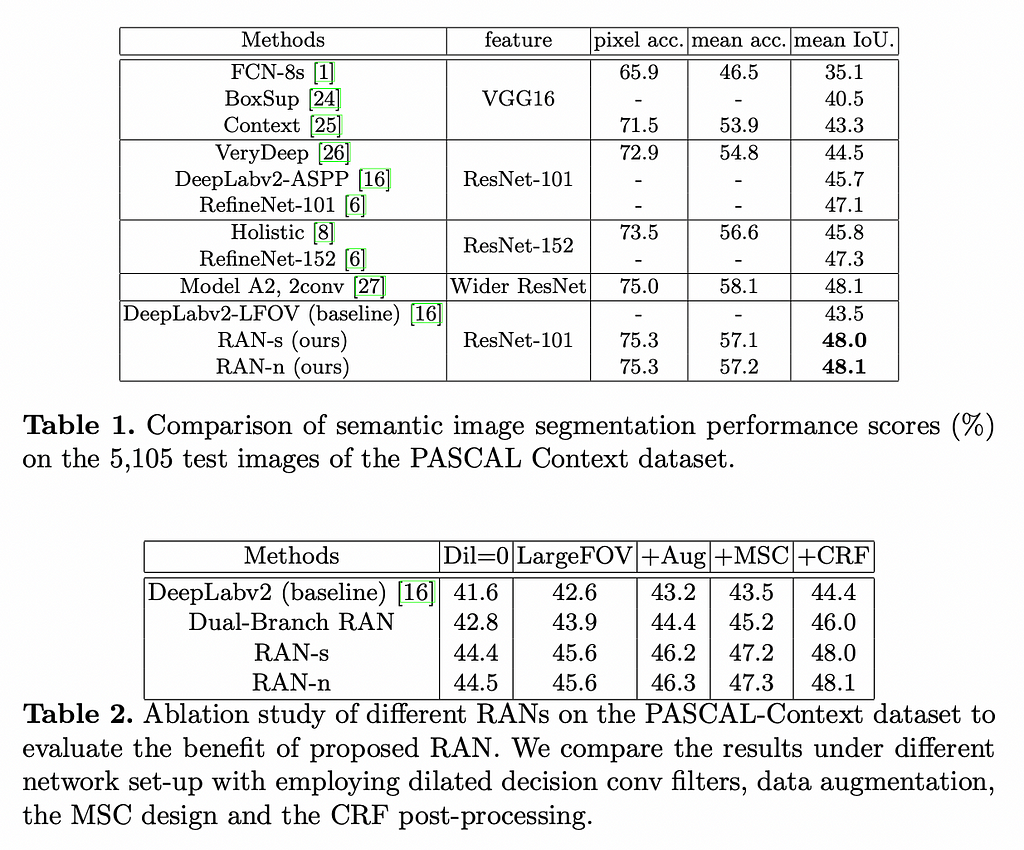
Thank you! ❤️
Citation
[1] Semantic Segmentation with Reverse Attention
Explained: Reverse Attention Network (RAN) in Image Segmentation was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


