


 Networks")
Demystifying the Architecture of Long Short Term Memory (LSTM) Networks
Last Updated on July 20, 2023 by Editorial Team
Author(s): Manish Nayak
Originally published on Towards AI.
Architecture of LSTMs U+007C Towards AI
Introduction
In my previous article, I explain RNNs’ Architecture. RNNs are not perfect and they mainly suffer from two major issues exploding gradients and vanishing gradients. Exploding gradients are easier to spot, but vanishing gradients is much harder to solve. We use the Long Short Term Memory(LSTM) and Gated Recurrent Unit(GRU) which are very effective solutions for addressing the vanishing gradient problem and they allow the neural network to capture much longer range dependencies.
Exploding Gradients
When backpropagation through time(BPTT ) algorithm gives huge importance to the weights and the values of weights become very large. This could result in values overflow and NaN values for the weights. This leads to an unstable network.
We can detect exploding gradients during the training of the network by observing the following signs.
- The values of the model’s weights quickly become very large during training.
- The values of the model’s weights become NaN during training.
- The error gradient values are consistently above 1.0 for each node and layer during training.
We can handle several ways exploding gradients problem. The following are popular techniques.
- This problem can be easily solved. Look at your gradient vectors, and if it is bigger than some threshold, re-scale some of your gradient vectors so that it is not too big. This is known as gradient clipping.
- We can use weight regularization by checking the values of the network’s weights and applying a penalty to the network loss function for large weight values.
- We can use LSTMs or GRUs instead of RNNs.
- We can use Xavier initialization or He initialization for the weights initialization.
Vanishing Gradients
The vanishing gradient occurs generally when the gradient of the activation function is very small. In backpropagation algorithm, when weights are multiplied with the low gradients, they become very small and vanish as they go further into the network. This makes the neural network forget the long-term dependency.
We know that long-term dependencies are very important for RNNs to function correctly. To understand the importance of long-term dependencies, consider the following two statements, which will feed to the RNN word by word to predict the next words.
The cat had enjoyed eating fish, the fish was delicious and was eager to have more.
The cats had enjoyed eating fish, the fish was delicious and were eager to have more.
- The network must have to remember the subject(singular or plural) of the sentence(cat) at time step 2 in order to predict the word at time step 12 for both statements.
- In the training, errors are backpropagated through time. The layer’s weights which are closer to the current time step are affected more than the layer’s weights of earlier time steps.
- The weights in the recurrent layer, which are normally updated in proportion to these partial derivatives at each time step, are not nudged enough in the right direction, This leads the network to learn any further.
- The model is unable to update the layer weights to reflect long-term grammatical dependencies from earlier time steps.
We can handle several ways vanishing gradients problem. The following are popular techniques.
- Initialize network weights for the identity matrix so that the potential for a vanishing gradient is minimized.
- We can use ReLU activation functions instead of sigmoid or tanh.
- We can use LSTMs or GRUs instead of RNNs. LSTMs or GRUs are design to capture long-term dependencies in sequential data.
LSTM Architecture
The LSTMs is a variant of RNNs that is capable of learning long term dependencies.
- The key of LSTMs is the cell state(C) which store information.
- LSTMs does have the ability to remove or add information to the cell state.
- The ability to remove or add information to the cell state regulated by structures called Gates.
- Gates are composed of a sigmoid neural network layer and a pointwise multiplication operation.
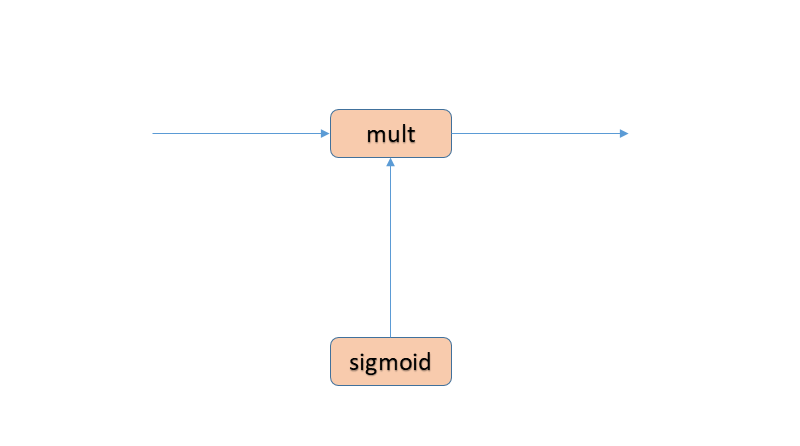
- The sigmoid layer outputs numbers between 0 and 1.
- 1 represents “completely keep this” and a 0 represents “completely get rid of this.”
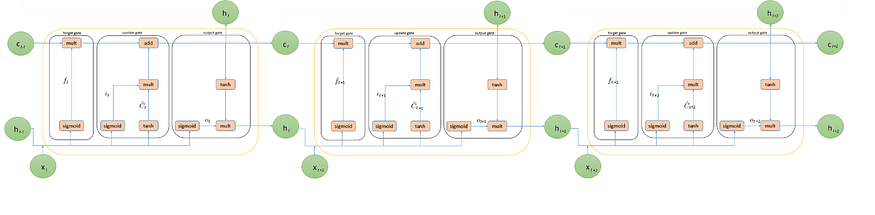
- LSTMs unit is composed of three key components forget, update and output gate.
Forget Gate Architecture
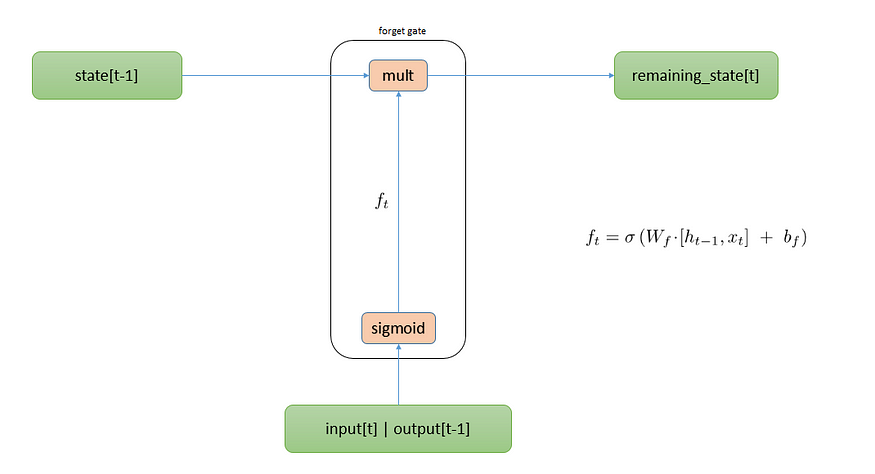
The Forget Gate is a cell state in LSTMs that stores the information. It decides what information need to keep and what information needs to be throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate” layer.
- It takes previously hidden layer activation h<t−1> and current input x<t> and apply a sigmoid layer on it and outputs a tensor with values between 0 and 1
- Multiply this tensor with the previous cell state C<t−1> in order to keep relevant information and throw away irrelevant information.
Let’s go back to our previous example
The cat had enjoyed eating fish, the fish was delicious and was eager to have more.
The cats had enjoyed eating fish, the fish was delicious and were eager to have more.
To predict the word at the 12th time step in each sequence, the network must remember the subject of the sentence (cats), seen at time-step 2, is a singular or plural entity.
The model will try to predict the next word at time step 12 for both statements based on all the previous input. the cell state must include the subject of the sentence (cats) seen at time-step 2, which is singular or plural.
When it sees a subject(cats), it want to keep information about the subject whether it was singular or plural.
Update Gate Architecture

The Update Gate decide what new information needs to store in the cell state.
- A sigmoid function called the “input gate” layer decides which values need to update. It gives an output a tensor with values between 0 and 1
- A tanh function creates a vector of new candidate values, C~<t>, that could be added to the state. It is also a tensor.
- Multiply these two tensor and create an update to the state.
- This update will be added to the cell state.
In our previous example of our language model, it wants to add the subject of the sentence to the cell state.
Output Gate Architecture

The Output Gate decides what is going to output. This output will be based on a cell state but will be a filtered version.
- A sigmoid layer which decides what parts of the cell state are going to output.
- Pass cell state through the tanh layer(to push the values to be between −1 and 1).
- Multiply it by the output of the sigmoid gate, so that it output only the parts it decided.
In our previous example of language model, since it just saw a subject, it might want to output information relevant to a verb. For example, it might output whether the subject is singular or plural so that it know what form a verb should be predicted next.
Accompanied jupyter notebook for this post can be found on Github.
Conclusion
RNNs are used for processing sequential data. But RNNs suffer with two major issues exploding gradients and vanishing gradients. RNNs forget the long-term dependency. LSTMs is a variant of RNNs that is capable of learning long term dependencies.
I hope this article helped you to get an understanding of LSTMs and how it is capable of learning long term dependencies. It also provide a good explanation of the key components of LSTMs and why we use LSTMs to handle exploding gradients and vanishing gradients issues.
References
Christopher Olah, Understanding LSTM Networks Networks. https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


