



Deep Learning Explained : Perceptron
Last Updated on January 27, 2023 by Editorial Team
Author(s): Clément Delteil
Originally published on Towards AI.
Deep Learning Explained: Perceptron
The key concept behind every neural network.
Nowadays, frameworks such as Keras, TensorFlow, or PyTorch provide turnkey access to most deep learning solutions without necessarily having to understand them in depth.
But this can get problematic as soon as your model is not working as expected. You may need to tweak it yourself.
So, if you are here to understand the concept of Perceptron in deep learning, I think you are on the right track if you want to be able to contribute one day to this ecosystem in any way, it is essential to understand the roots of these systems.
Otherwise, if you are already familiar with the concept of Perceptron, it’s not a big deal. I still hope to surprise you!
In this article, I’ll introduce the idea of the Perceptron. We’ll see how it was thought back in 1950 and how it works.
Let’s get into it.
A bit of history
Beginning
Back in 1943, McCulloch and Pitts published a paper entitled A logical calculus of the ideas immanent in nervous activity — known today as the first mathematical model of a neural network.
The idea of this article is part of the dynamics of the time of wanting to create intelligent machines by reproducing the functioning of the human brain.
I take as evidence the beginning of the abstract of it.
Because of the “all-or-none” character of nervous activity, neural events and the relations among them can be treated by means of propositional logic.
At that time, the functioning of the human brain was popularized as interconnected nerve cells transmitting electrical and chemical signals like a simple logic gate!

The Perceptron itself
Now let’s jump forward 14 years to 1957 and the publication of an article by Rosenblatt called The Perceptron — A Perceiving and Recognizing Automaton.
It is in this article that we find the perceptron as it is understood today.
A system to learn the optimal weights to multiply with the inputs to determine whether a neuron activates or not.
Below you can see the first perceptron trained to recognize objects or patterns, in this case, the letters of the alphabet.

Now that you have an idea of the history of this concept let’s move on to its application in deep learning.
Perceptron applied to Deep Learning.
The basic perceptron is used for binary classification in supervised machine learning.
As a reminder, binary classification implies that there are only two classes to predict 1 and -1, for example.
And supervised machine learning refers to training the model via already labeled data (with their associated classes).
Mathematical definition
- We define the inputs 𝑥, outputs y, and weights 𝑤 the following way.
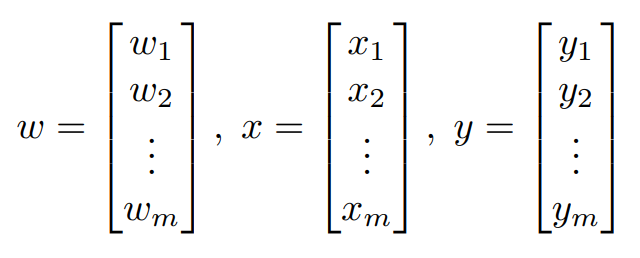
Where m is the size of the vector 𝑤, 𝑥 or y.
- Let 𝑧 be the net input composed of a linear combination of 𝑥 and 𝑤.
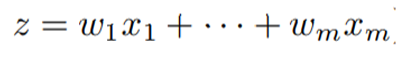
- The classification is defined by an activation function phi: 𝜙 (𝑧) with a threshold theta: 𝜃 corresponding to the so-called bias, we will see it later.
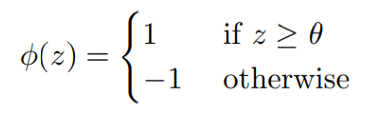
The activation function defines in a way how the incoming element will be classified.
If the neuron activates, that is to say, if z ≥ 𝜃, then the current input will be assigned class 1, -1 otherwise.
This kind of function is called a Heaviside step function.
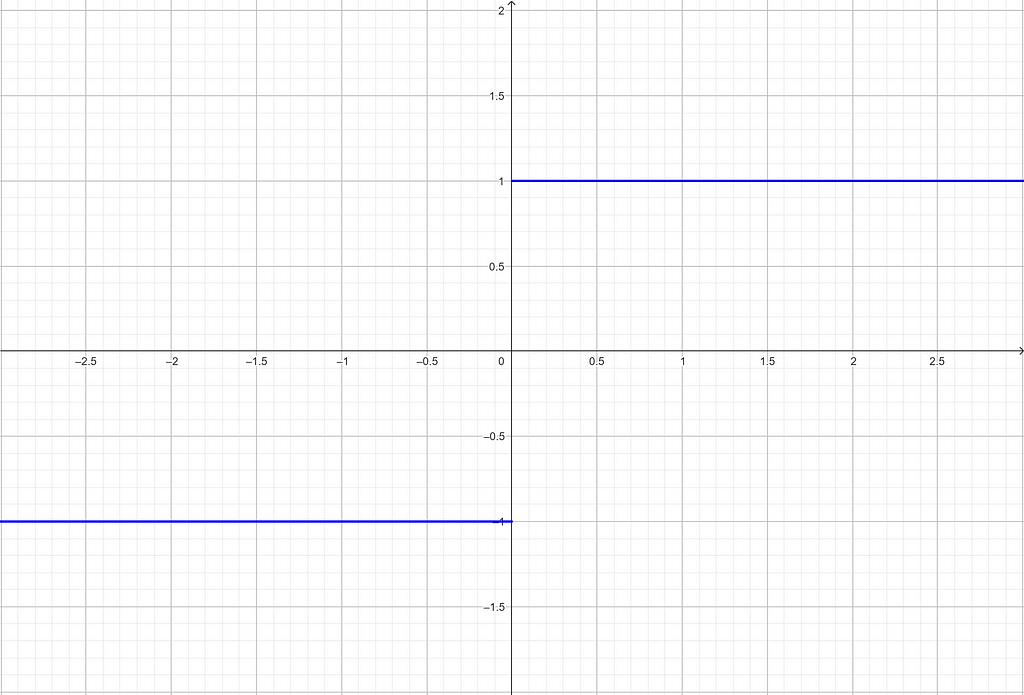
Above, theta is equal to 0. By changing this value, we shift the curve to the left or the right.
To recap, now that we have added theta, the equation for the net input z changes a little bit.
We now have :
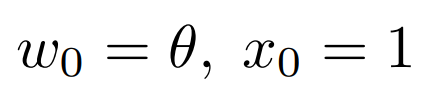
With :
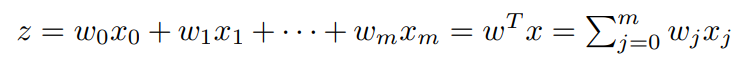
Congratulations! You now know the mathematical definition of a perceptron.
Here is the graphical equivalent:
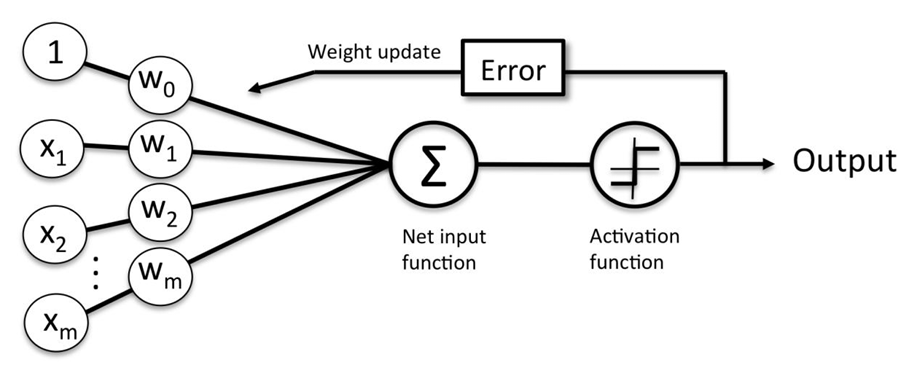
But how do you train a perceptron?
Training a perceptron
Here are the training steps:
- Initialization of the weights to 0 (or a small random number)
2. For each training example x⁽ⁱ⁾ :
– Calculate the estimated output ŷ⁽ⁱ⁾
– Update the weights
The update of each weight of the vector w
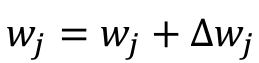
is done as follows :
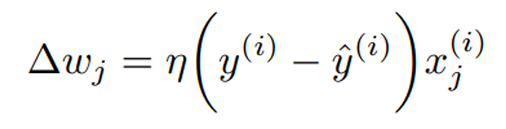
Where we introduce eta: 𝜂, the learning rate (between 0.0 and 1.0).
Depending on whether or not you are comfortable with these notations, you may have trouble imagining how a perceptron is trained.
Let’s take some examples.
Example
For the sake of simplicity, let us assume that the learning rate is equal to 1 and that we know the following values.
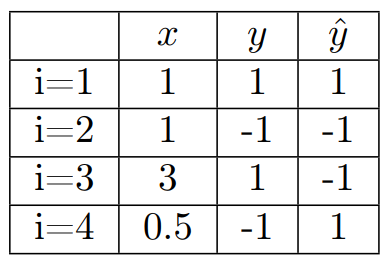
We consider that there is only one feature in the dataset to simplify the calculations. Here are some examples of the calculation of the delta of the first weight in the perceptron.

You can see that the estimated output value given by the activation function is systematically subtracted from the real output value.
When the estimated value is the same as the real value, it is equal to 0 so there is no update.
Otherwise, the weight must be updated.
This is the case in the last two examples. We can notice that the value scale of the input 𝑥 makes the weight update vary more or less.
In example number 3, 𝑥 = 3, and so we have a weight difference of 6, whereas in example number 4, 𝑥 = 0.5, so the weight difference is only 1.
Bias
Earlier I intentionally skipped the explanation of the bias so as not to overload you with information.
As explained above, the bias is a scalar value that is added to the net input z before passing through the activation function.
It allows the decision boundary of the perceptron to be shifted away from the origin, which can be useful in situations where the data is not linearly separable.
The bias is an addition to the perceptron that has its own weight. This weight is also learned during the learning phase.
Learning rate
The learning rate is a scalar value that controls the step size of the weight updates during the training process.
Depending on its value, the weights are more or less modified when there is a prediction error.
Its value is defined before the training process. So, you have to be careful because its value remains the same during the whole training.
If you set its value too high, the perceptron may overshoot the optimal solution and may not converge to a good solution. That is to say, it will take large steps in the weight space, which can result in moving past the optimal point and ending up in a region of the weight space that is worse than the optimal solution.
Also, if you set its value too low, the perceptron will converge too slowly, and it may take a long time to train it. Additionally, it might get stuck in a local minimum and fail to find the global minimum.
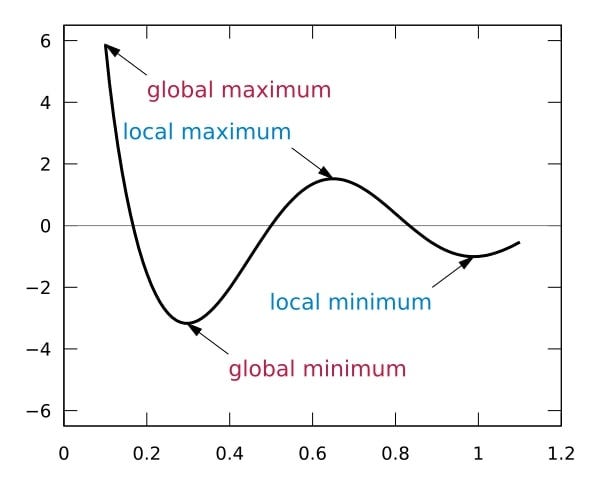
The optimal value of the learning rate depends on many factors. It is common to experiment with different values during training to find the one that gives the best performance.
In summary…
- The concept of the perceptron goes back to the 40s and 50s.
- It is based on our understanding of the human brain.
- It is initially used for binary classification.
- A neuron or perceptron activates when the current net input value passes the activation function test. That is, when it is greater than the bias: theta.
- The bias controls the decision boundary of the perceptron.
- The learning rate determines how much the weights are adjusted in response to an error of prediction.
References
[1] McCulloch, W.S. and Pitts, W. (1943) “A logical calculus of the ideas immanent in nervous activity,” The Bulletin of Mathematical Biophysics, 5(4), pp. 115–133. Available at: https://doi.org/10.1007/bf02478259.
[2] Rosenblatt, F. (1957) “The Perceptron: A Perceiving and Recognizing Automaton,” Cornell Aeronautical Laboratory, Report 85–60–1. Available at: https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf
[3] Grove, M. and Blinkhorn, J. (2020) “Neural networks differentiate between middle and later stone age lithic assemblages in Eastern Africa,” PLOS ONE, 15(8). Available at: https://doi.org/10.1371/journal.pone.0237528.
I hope you enjoyed reading this. If you’d like to support me as a writer consider following me and giving me feedback on my writing ✨.
Deep Learning Explained : Perceptron was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





