



Deal With an Imbalanced Dataset With TensorFlow, LightGBM, and CatBoost
Last Updated on January 6, 2023 by Editorial Team
Last Updated on November 8, 2022 by Editorial Team
Author(s): Konstantin Pluzhnikov
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Add new instruments to your toolbox when customizing your models
You have an imbalanced dataset; you want to reduce the count of false negatives (FN) or even false positives (FP). Maybe you like custom things and want to practice adding changes to standard models. If so, this article is for you.
One way is to customize your model’s loss function with a particular coefficient. This article aims to show customization approaches in TensorFlow, LightGBM, and Catboost. If you want to get a feeling of the whole idea with related math and see the same concept for XGBoost, look at my article on Medium.
Also, I aim to provide a way to embed a custom hyperparameter to a custom function, which opens the door to an advanced tuning of new parameters as ordinary ones.
I use the Titanic dataset for demonstration because it is approachable and imbalanced. Basic models, as well as customized models, are in my GitHub repository.
LightGBM
It is one of the most effective gradient-boosting algorithms developed by Microsoft. It outperforms XGBoost in speed and is comparable in accuracy. For more details, check this article by BexBoost. LightGBM is a younger brother of XGBoost, so it has all its achievements.
I have used embedded user-defined functions to introduce beta as a core part of the logloss function (it is no more an external hyperparameter).
You can see that the outer function presents betato the internal, which calculates derivatives. The same applies to a custom metric. Now you can tune it with other hyperparameters with special packages like the Optuna library.
beta should be < 1.0 to penalize FN. To punish FP, it should be more than 1.0. For details, please see my article on Medium.
There are some differences compared to the XGBoost custom loss function. Firstly, LightGBM puts y_predin logit_raw format, and the logit transformation is needed. Secondly, LightGBM custom metric outputs three results (the name of the custom metric (e.g., “logreg_error”), the value of metrics, and the boolean parameter that should be set Falsebecause our goal is to reduce custom metric value).
There is one more interesting detail in a logit transformation of predt ; I have used np.where function to ensure stability and avoid overflow when dealing with negatives logit_raw. It is mentioned as the best practice in different examples on Stackoverflow and models’ documentation.
Let’s plot confusion matrices of the results of a standard LightGBM model and the one with custom loss:
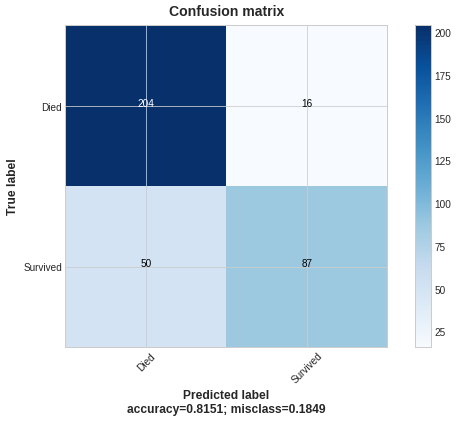
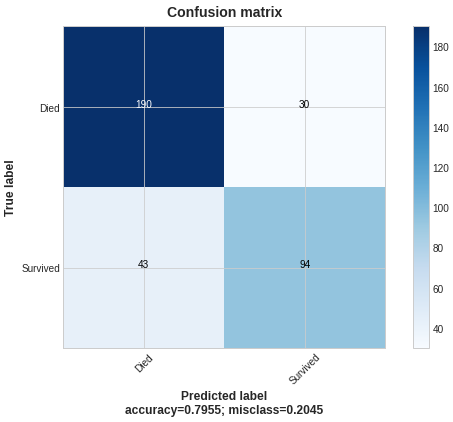
The custom loss with beta< 1 led to the growth of FPs and TPs; to the depletion of FN and TN.
CatBoost
The full name is Categorical boosting, developed by Yandex. It has a massive advantage over other algorithms as you do not need to encode categorical features of your dataset; you list them in the model, and it deals with them on its own. Dmytro Iakubovskyi uses it broadly in his analysis of the different datasets (IMDB, wine, beer, and many more tables with statistics). CatBoost inherits the most perks of XGBoost and LightGBM.
You can see the difference between Catboost (using object-oriented programming) and LightGBM (a standard user-defined function) realizations. I take code for the CatBoost class from the official documentation. I only add the beta to the initialization of the class. You can write the code for these functions in any form you like (OOP or UDF). The choice is yours!
Plotting the results:
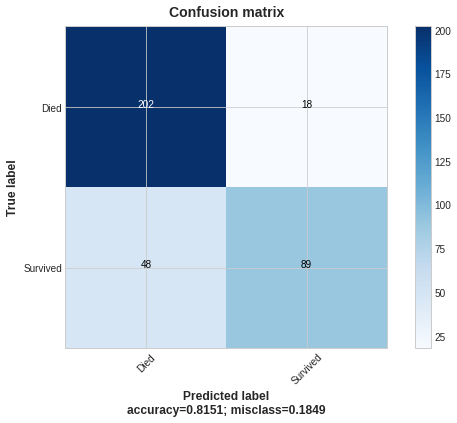
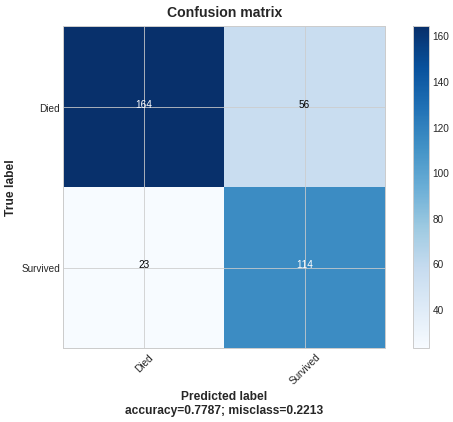
The logic of the results is the same as for a LightGBM model.
TensorFlow
It is a well-known and super powerful family of algorithms by Google. Setting up a custom loss here is a kind of different story. You do not need to write down derivatives and a custom metric explicitly; there is no `beta` no more ( betais dead, long live to pos_weight!). TF has a suitable function, tf.nn.weighted_cross_entropy_with_logitswhich makes things much more manageable.
pos_weight should be > 1.0 to penalize FN, and < 1.0 to punish FP. It is the opposite situation compared to beta. pos_weight is a coefficient that multiplies FN part of logloss while beta is a factor of FP part.
Plotting the results:
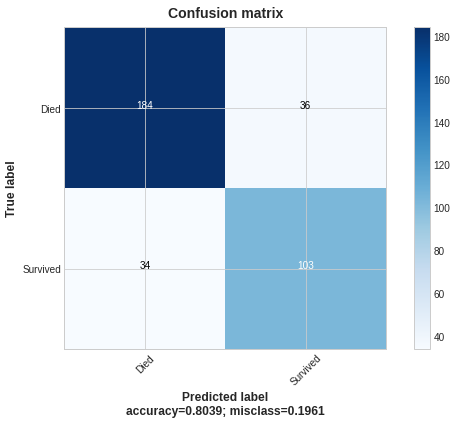
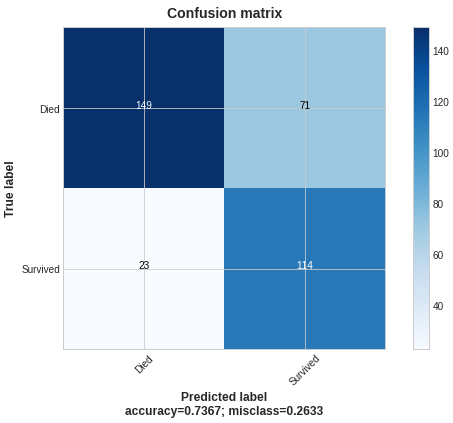
My custom model showed rather bad performance while the TF standard model has done great; I hope you excuse me for the poor results because the main goal here is demonstration.
Conclusion
Overall results are comparable for all models. The trade-off between FN and FP is also in place. But if reducing FN is your goal, these custom losses are at your disposal.
Advantages
- Easy and fast to apply (use four user-defined functions and beta, and that’s it).
- There is no need to perform manipulation with underlying data before modeling (if a dataset is not highly imbalanced)
- It may be applied as a part of data exploration or as a part of model stacking.
- We may add it to the most popular machine-learning packages.
- With embedded beta or pos_weight we could tune them as usual hyperparameters.
Shortcuts
- We should adjust beta to get optimal FN to FP trade-off.
- It may not provide meaningful results when a dataset is highly imbalanced (the dataset where the minor class is less than 10% of all samples). Exploratory data analysis is vital to make the model work.
- If we penalize FN, it often leads to considerable FP growth and vice versa. You may need additional resources to compensate for that growth.
I hope this article gives some guidance for writing custom losses with UDFs and OOPs or even adapting the official realization of Tensorflow. Also, you can use these examples as a starting point for your function development.
Stay safe and healthy. Do not allow war.
References
- Discussion of how to implement LightGBM on Stackoverflow -> https://stackoverflow.com/questions/58572495/how-to-implement-custom-logloss-with-identical-behavior-to-binary-objective-in-l/58573112#58573112
- The official CatBoost documentation of a custom loss -> https://catboost.ai/en/docs/concepts/python-usages-examples#user-defined-loss-function
- The official CatBoost documentation of a custom metric -> https://catboost.ai/en/docs/concepts/python-usages-examples#custom-loss-function-eval-metric
- The official TensorFlow documentation of weighted cross entropy with logits -> https://www.tensorflow.org/api_docs/python/tf/nn/weighted_cross_entropy_with_logits
- The excellent article about how to assemble custom loss functions in TensorFlow -> https://medium.com/swlh/custom-loss-and-custom-metrics-using-keras-sequential-model-api-d5bcd3a4ff28
- My GitHub repository with all custom losses mentioned -> https://github.com/kpluzhnikov/binary_classification_custom_loss
Deal With an Imbalanced Dataset With TensorFlow, LightGBM, and CatBoost was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

