


Create a Dataset for Object Detection
Last Updated on July 24, 2023 by Editorial Team
Author(s): Pushkar Pushp
Originally published on Towards AI.
Computer Vision
Create a Dataset for Object Detection
Introduction
The first step for most computer vision tasks such as classification, segmentation, or detection is to have custom data for your problem set. There are multiple ways of creating labeled data; one such method is annotations.
The annotation technique manually creates regions in an image and assign a label.
Now to keep things simple, we will be using two tools Pixel Annotation tool and Microsoft VoTT. You can read more about this tool, Pixel and Microsoft VoTT.
Pixel Annotation Tools
Installation for macOS.
git clone https://github.com/abreheret/PixelAnnotationTool
Then update brew using brew update.
Next, you need to install a cross-platform application development framework such as qt.
brew install qt
Pixel Annotation tool uses a watershed algorithm to do image segmentation.
Readers can use this link to read more about the watershed algorithm in detail.
brew install opencv
In Mac curl is already installed, you can check it by using typing curl -V in the terminal.

Something like this will appear, else install curl using brew.
brew install curl
Pixel Annotation tool does not come up with a .dmg file or a Graphic interface, so you need to transform source code to a stand-alone form via build.
cd PixelAnnotationTool
Inside this directory create the build
mkdir build
cd build
Next, inside build use the following command:
cmake .. -DCMAKE_BUILD_TYPE=$CONFIG -DDISABLE_MAINTAINER_CFLAGS=off -DCMAKE_PREFIX_PATH=$(brew --prefix qt) -DQMAKE_PATH=$(brew --prefix qt)/bin
Finally,
cmake --build .
We are all set to run and use the Pixel Annotation tool.
Go to the spotlight and search for the Pixel Annotation tool.

Creating a Dataset.
Go to the File option at the top left and select Open a directory.

On the top right, see all file names.
Select one image, say ‘Sachin.jpg.’
Go to the color panel on the left side and select any color, let me set the sky.
Move your cursor around the person (Sachin).

Then select another color say ‘out of roi’ and move the cursor around the entire region except for a person.
Then click on the watershed option at the bottom left and press Command + S to save the image.
Finally, you will get this mask.

Result
Input

Output

This mask serves as input for any object detection model.
Microsoft Visual Object Tagging Tool (VoTT)
Installation for macOS.
Unlike Pixel Annotation Tools, VoTT comes with Disk Image(dmg) file.
- You can download and install the tool from below link https://github.com/microsoft/VoTT/releases/download/v2.1.0/vott-2.1.0-darwin.dmg.
- Go to the spotlight and search for VoTT and launch.

- Click on New Project
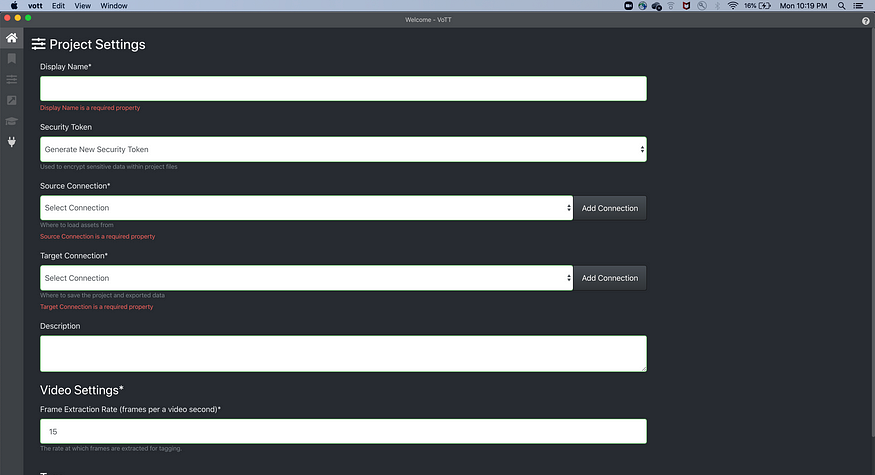
- Fill Display Name, say Cricketers in my case.
- Add Source Connection, click on that a screen will pop up like

- In Provider, select Local File System if your file to annotate is on the Laptop.
- Select the folder where the images are and click on “Save Connection.”
- Once saved, something like below will appear, from source connection drop-down select ‘Cricketers,’ which we have created.
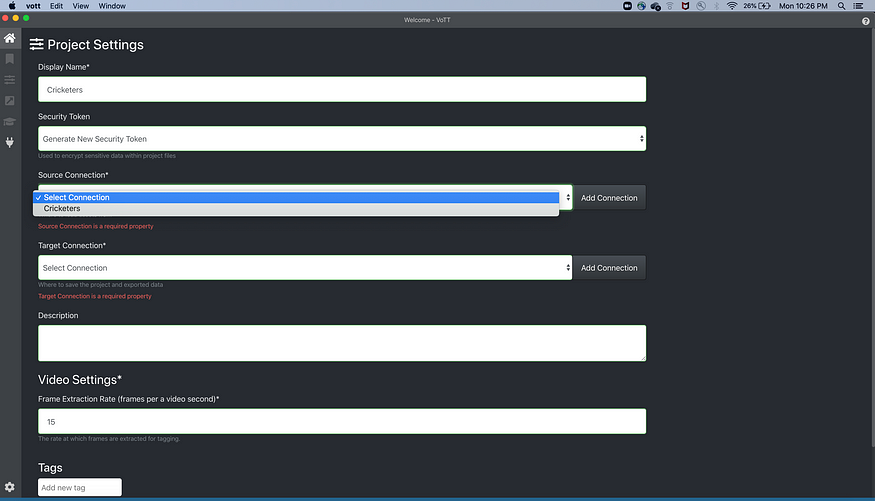
- Next, go to the target connection and add a connection.

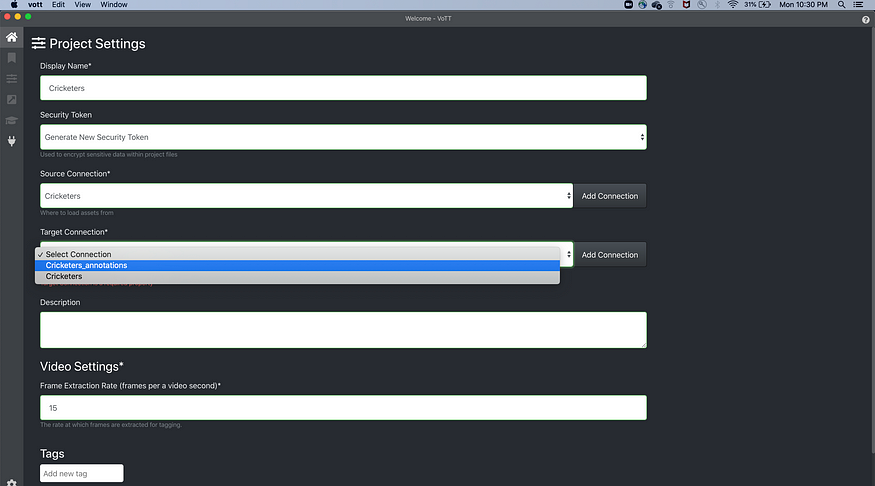
Same as source, for target select Cricketers_annotations.
- At the bottom, there will be Tags.
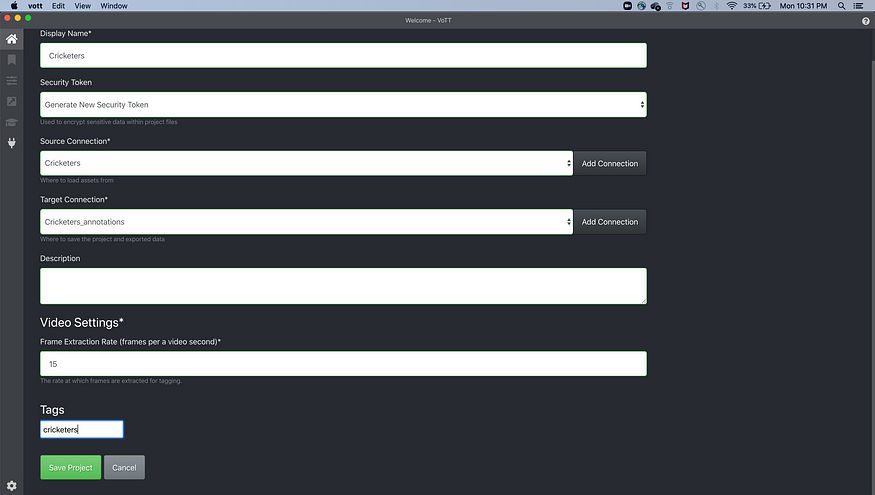
Enter the label you want, cricketers in our case.
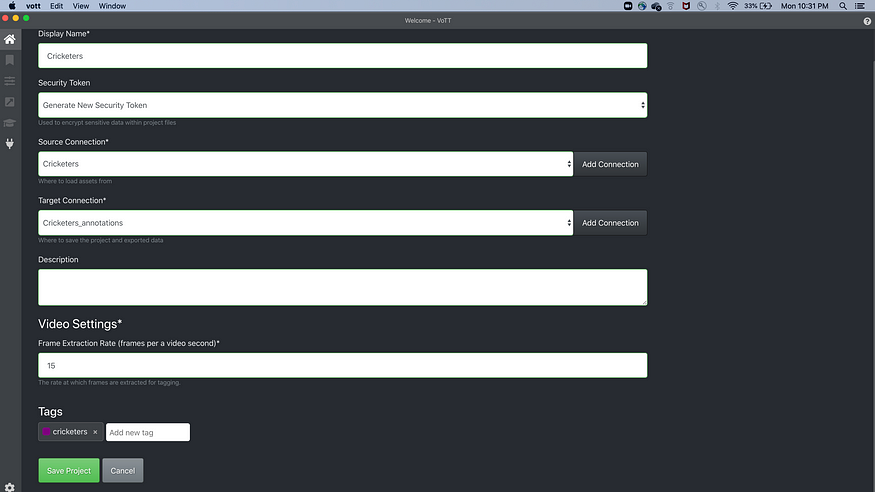
- Save Project
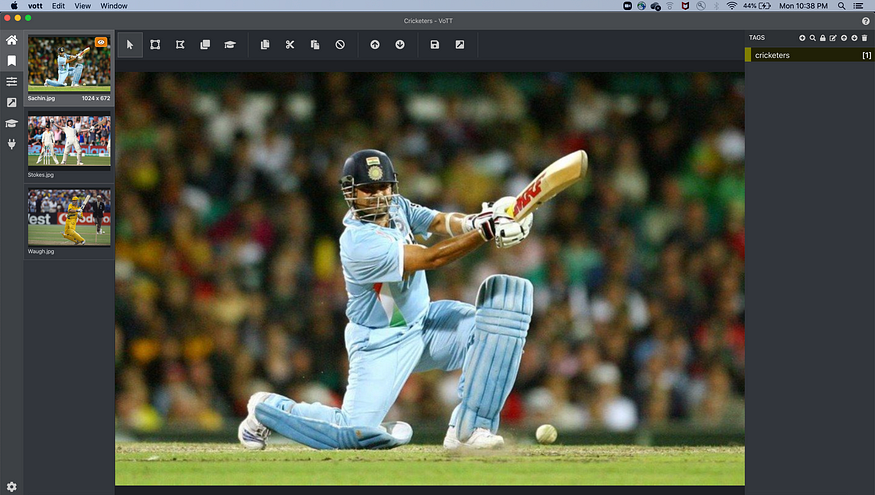
A screen similar to this will appear.
- In the left panel, you will see an arrow mark (fourth row ), click on that below screen will appear.

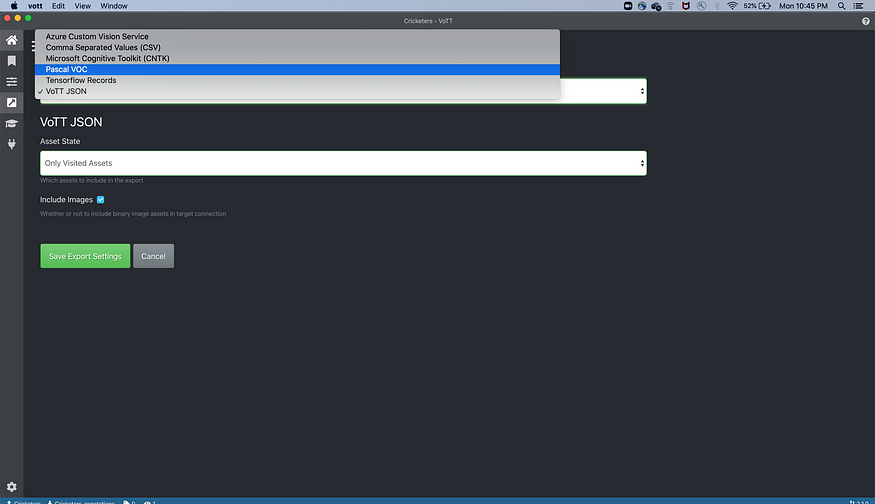
From the Provider drop-down menu, select Pascal VOC and enter “Save Export Settings.”
Create a box around the player and select tag from right, then save it from the save option at the top.

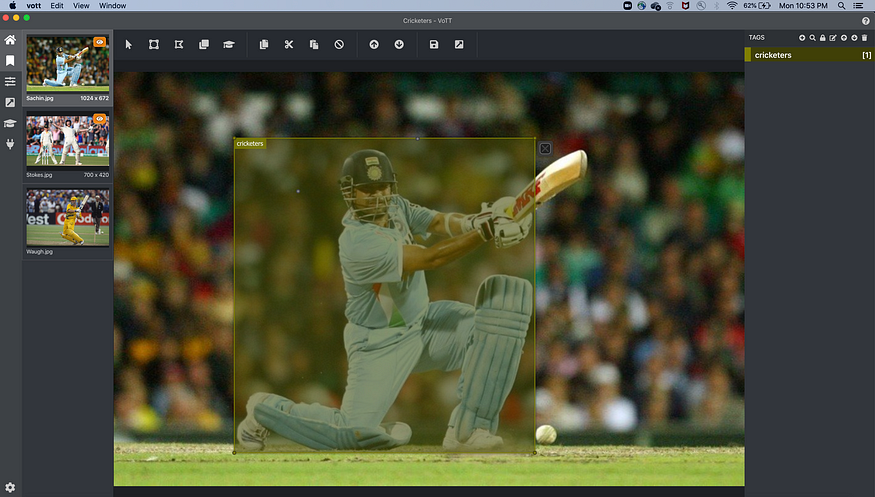
- Repeat this process for all images in the folder. Once done, we need to export the output.

- At the top of the image, there is an Export project option.

Once exported, go to that folder.
In this blog, we learned how to create a dataset for object detection and segmentation. Next, I will walk through the conversion of this mask into polygon co-ordinates, annotations.
A directory Cricketers-PascalVOC-export creates at the target location provided earlier.
Enjoy!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

