



Cloud Computing
Last Updated on December 24, 2021 by Editorial Team
Author(s): Ömer Özgür
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
How To Automate Data Processing With AWS Batch
While solving a problem in the field of machine learning, we can experiment by changing parameters such as models, augmentation methods, data. An important task for a data scientist is to automate repetitive tasks.
Automating the time-consuming steps during these experiments will make our lives easier and the development process faster.
Demo Architecture
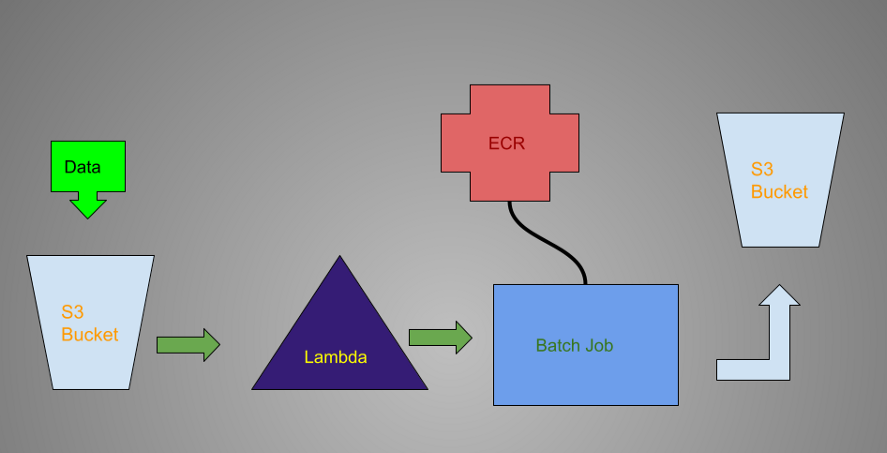
In this demo, we will do a simple experiment. When a CSV is uploaded to the S3 bucket, we will see how it can trigger Lambda function, become processed by AWS Batch, and written to another S3. You can edit the python code according to your needs. In the example these steps will be followed:
- Pushing our docker to ECR
- Creating Batch Job
- Creating Lambda Function
Lambda vs Batch
Basically, the purpose of Lambda and Batch is to work in a serverless way to fulfill the given task. Batch and Lambda are basically different in run times, if your process takes less than 15 minutes you should use Lambda.
You can also use GPU in Batch. Lambda only works with the CPU.
Let’s Get Started
Note: Your Lambda function, S3 bucket, and Batch should be in the same region
You can use your computer or create an Ec2 instance that has docker installed. Docker creation codes in Linux but you can find the windows version on AWS.
First of all, we need to install awscli and set up the credentials.
sudo apt install awscli -y
aws configure
After configuration, we can go to Elastic Container Registry and create a new repository.
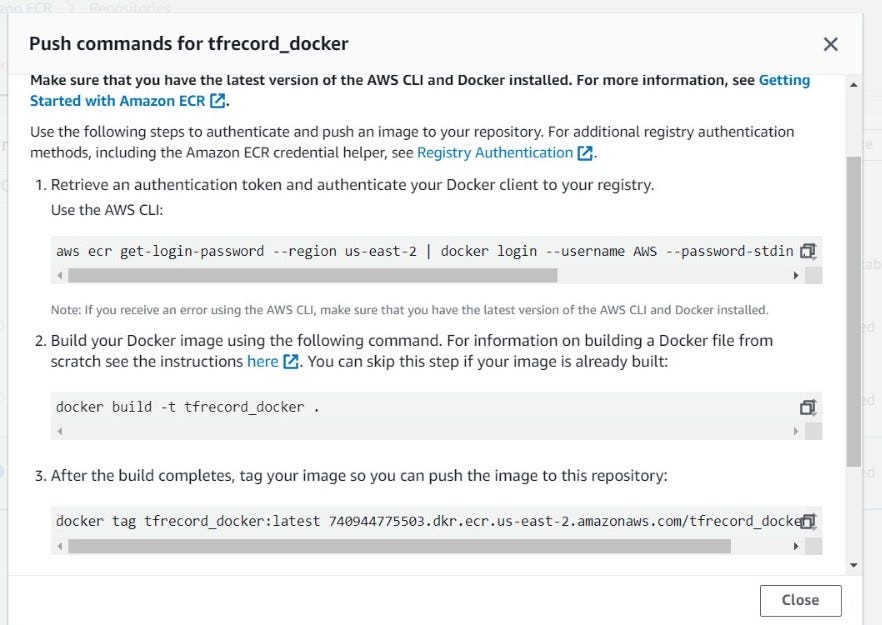
The commands here will be specific to you. First, let’s authenticate the Docker client.
aws ecr get-login-password --region us-east-2 | docker login --username AWS --password-stdin your_acct_id.dkr.ecr.us-east-2.amazonaws.com
We need 3 files, Docker file, requirements.txt, main.py. My all files in under pyproject folder.
cd pyproject
Our Docker File:
FROM python:3.6
WORKDIR /script
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY main.py .
ENTRYPOINT [ "python", "main.py"]
Our requirements.txt. You can add the libraries needed.
tensorflow==2.4.3
numpy
pandas
boto3
s3fs
Pillow==8.0.1
Our basic main.py, we can configure AWS credentials for reading writing from s3. And it uses command-line arguments to get the path of the file.
import io
import os
import pandas as pd
import boto3
import s3fs
import sys
os.environ['AWS_ACCESS_KEY_ID'] = 'xxxxxxxxxxxxxxxxxxxxxx'
os.environ['AWS_SECRET_ACCESS_KEY'] = 'xxxxxxxxxxxxxxxxxxxxxxxxx'
os.environ['AWS_REGION'] = 'us-east-2'
os.environ['S3_ENDPOINT'] = 'https://s3-us-east-2.amazonaws.com'
os.environ['S3_VERIFY_SSL'] = '0'
if __name__ == "__main__":
csv_path = sys.argv[3]
df = pd.read_csv(csv_path)
df = df[df["Age"]>20]
df.to_csv("s3://auto_proc/processed.csv",index=False)
If our files okay we can run to build and push our docker to ECR:
docker build -t pyproject .
docker tag pyproject:latest 7409775503.dkr.ecr.us-east-2.amazonaws.com/pyproject:latest
docker push 7409475503.dkr.ecr.us-east-2.amazonaws.com/pyproject:latest
Creating Batch Job
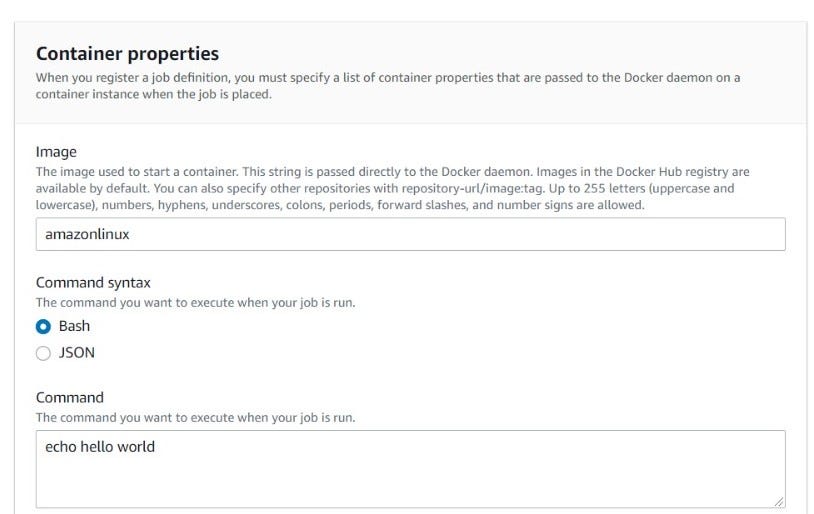
The most important part when creating a Batch Job is to enter the Image URI, which we created ECR before, in the Image section. We will use the jobQueue and jobDefinition information that we entered during the Batch creation process to trigger the Lambda.
In serverless architecture, we are not dependent on a single machine. When the task is assigned, the Docker we created runs on a machine with the desired features and then leaves that machine.
Creating Lambda Function And S3 Trigger
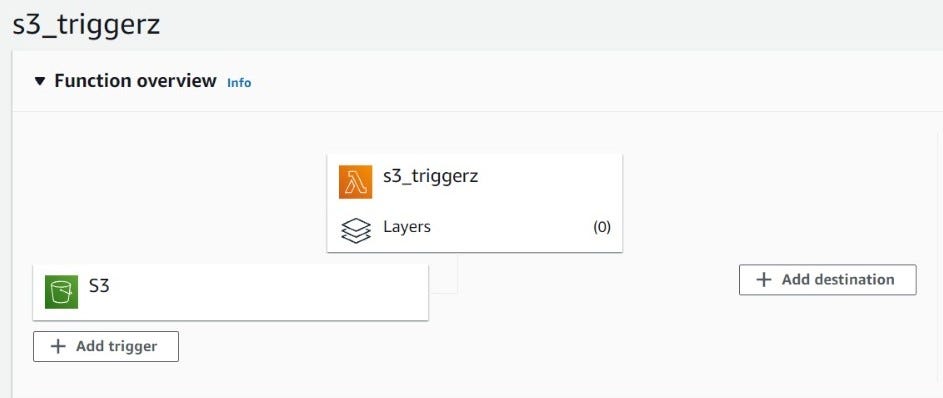
In the architectural plan, the csv file is loaded to s3 and triggers the Lambda. Triggered Lambda sends the job to Batch with the uploaded file name. The lambda code :
import json
import urllib.parse
import boto3
s3 = boto3.client('s3')
client = boto3.client('batch', 'us-east-2')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3'] ['object']['key'], encoding='utf-8')
response = s3.get_object(Bucket=bucket, Key=key)
full_path = "s3://{change here}/" +key.split("/")[1]
print(full_path)
csv_job = client.submit_job(
jobName='example_job',
jobQueue='{change here}',
jobDefinition='{change here}',
containerOverrides={
'command': ["python","main.py",full_path]})
We can see the submitted jobs in Batch. We can run multiple Docker images by choosing more CPUs in the computing environment.

Conclusion
Data pipelines are an indispensable part of machine learning. AWS Lambda and Batch are useful for this type of need. Automate, make life easier!
Cloud Computing was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

