



Building an End to End Recommendation Engine using Matrix Factorization with Cloud Deployment using Amazon SageMaker
Last Updated on July 19, 2023 by Editorial Team
Author(s): Anurag Bisht
Originally published on Towards AI.
Cloud Computing, Machine Learning
How many times have you visited any shopping website and purchased anything, have you noticed that the website personalizes as per your purchase history?
You all must have watched YouTube videos. Does the app start suggesting videos in a certain fashion as per the type of content you watch?
What about watching a movie or browsing the internet, does the ads look familiar?
Recommendation engines are one of the most important applications of machine learning, they have changed how businesses interact with their customers. It helps users find related content, explore new items, and improve decision making, but it also helps content producers to learn user behavior and increase user engagement.
This not only helps businesses target their customers with the right kind of products, but it also helps users personalize their user experience based on their interests and consumption.
Types of Recommendation Systems:

- Content-based filtering:
Content-based filtering uses attributes of the items to recommend new items to a user. The recommendation is purely based on the content consumption history of the user. For eg. If a user watches 2 movies and rates a sci/fi movie high and a horror movie as low, the content-based recommendation engine will start recommending more sci/fi movies to that user.
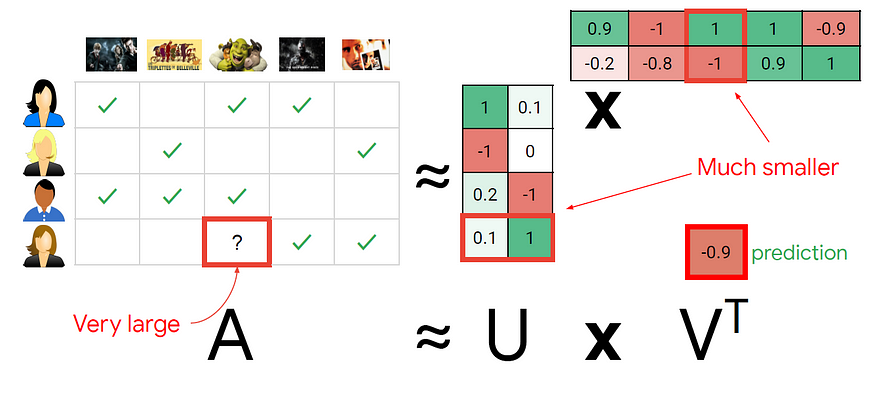
Below is a user-item interaction matrix where the recommendation for the second user will only be based on the items rated by that user.

Cons: Cold start– Suppose a user has not rated enough movies, the recommendation engine would not take the unrated movies into account as it considers only the user history.
Used when: Enough user history is available.
2. Collaborative filtering:
It uses similarities between users and items simultaneously to determine what to recommend. This considers the whole user-item interaction matrix to recommend items to a user. For eg if 2 users show similar purchasing behavior of items, there is a high chance that both will buy similar types of items.
Below is an example where the whole matrix would be considered to recommend items to the second user.

Advantage: It overcomes the cold start problem as long as the similarity is detected between users.
Used when: There are high chances that the user interaction matrix will be sparse (the user may or may not rate most of the items).
Cons: In rare cases where users rarely interact with any item(eg. purchasing any super-luxury item), collaborative filtering might not help much.
3. Knowledge-based filtering:
In this explicit knowledge about the user is used to create a recommendation. For eg. asking some questions in the beginning in the form of a quiz or form.
Advantages: It overcomes the above problems.
Hybrid-based filtering: In a real-world scenario, a combination of all three techniques is used to build a recommendation engine. Hence it’s called hybrid-based filtering.
Today we will cover collaborative filtering for building our recommendation engine. We can follow 2 approaches to build our recommendation engine:
The idea is to factorize the user-interaction matrix into user-factors and item-factors. Using the given user id, the product of both the matrix will result in a prediction rating. Using these top k rating users will get the recommendations of k items. In this blog, we will build our recommendation using matrix factorization.
The model can be represented mathematically using this equation.
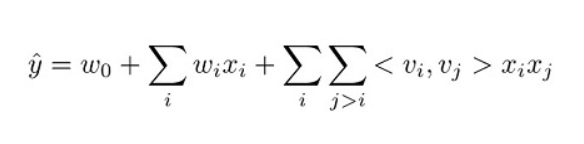
The three terms in this equation correspond respectively to the three components of the model:
- The w0 term represents the global bias.
- The wi linear terms model the strength of the ith variable.
- The <vi,vj> factorization terms model the pairwise interaction between the ith and jth variable.
The model is trained to be reducing the loss metric.
For classification the log loss function has the equation:
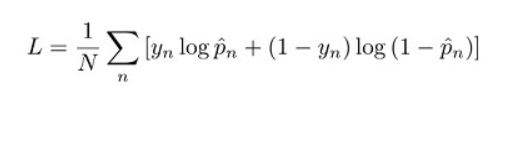
where

ŷn: model prediction
yn: target value
For the regression task, the square loss function:

You can read more about factorization machines using this whitepaper.
2. Neural Collaborative Filtering (NCF):
Before we jump into what neural collaborative filtering is we should understand 2 terms:
Explicit feedback: It is explicitly provided to the system by the user, for example like or dislike or rating to a video. This data may or may not be present based on user interaction.
Implicit feedback: This data is collected implicitly through the user’s usage pattern, eg watch time, click, views of a video. It is more readily available.
NCF goes one step beyond the traditional matrix factorization technique by using implicit feedback from the user-item interaction. For this NCF utilizes a multi-layer perceptron to introduce non-linearity in the solution.
Prerequisites:
For building our model, we need an AWS account and access to AWS SageMaker services. The dataset will be an opensource dataset. We will use AWS services like S3 to store the model artifacts and use AWS sagemaker hosting services to deploy our model end to end.
Note: Although you might be using AWS free tier services, AWS Sagemaker service may incur you charges if not under free trial to use Sagemaker services. So keep a watch on how long you use SageMaker services to avoid any surprises related to billing.
We will start with a bucket creation to store the model artifacts. For this, we will use the Amazon S3 service.
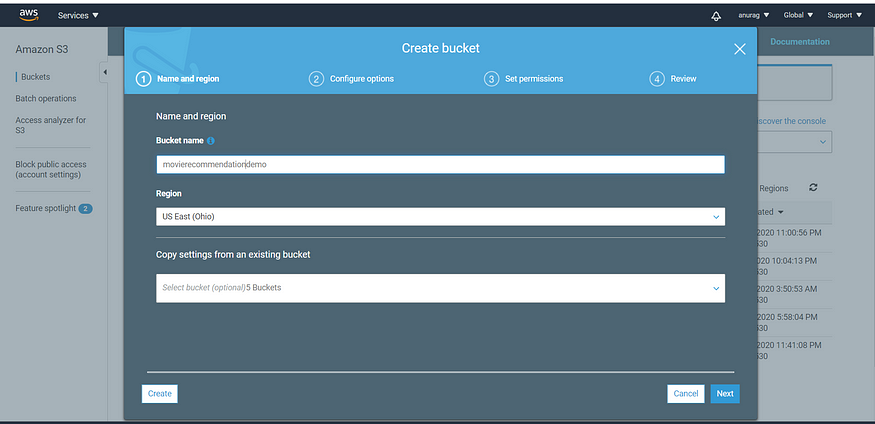
Make sure you keep block all public access checked.
Once the bucket is created, go to Amazon SageMaker service to create a notebook instance.
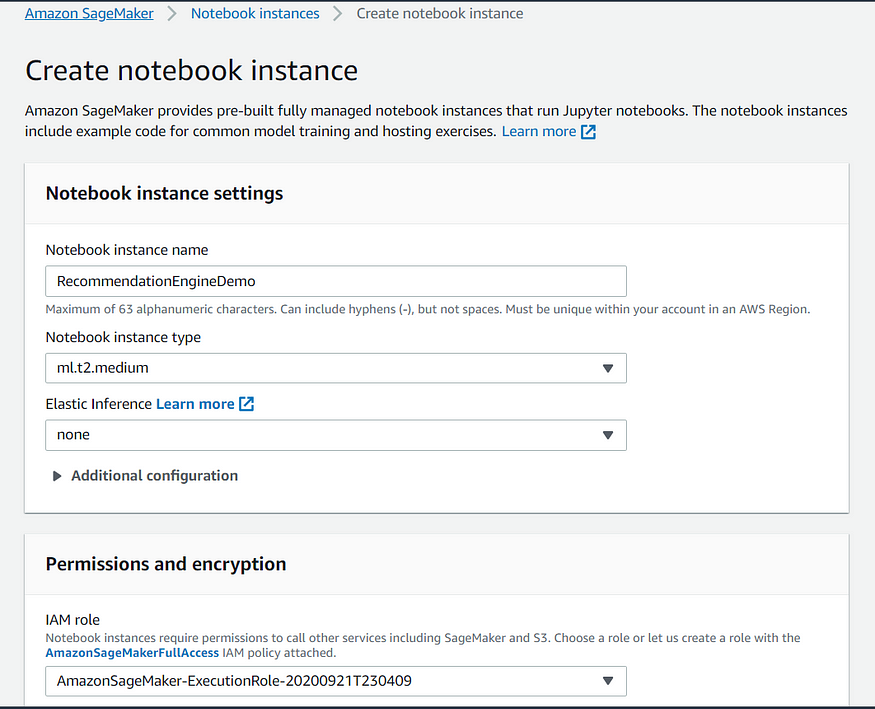
Once the instance is ready you can open jupyterlab.

- Download the dataset from the public repository using the following commands:
!wget http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -o ml-100k.zip

2. Inspect the dataset:
The next task is to inspect the downloaded dataset.
%cd ml-100k
!shuf ua.base -o ua.base.shuffled
!head -10 ua.base.shuffled!head -10 ua.test

3. Build training and testing dataset:
In this step, we will import necessary libraries and create a training and testing datasets.
import sagemaker
import sagemaker.amazon.common as smac
from sagemaker import get_execution_role
from sagemaker.predictor import json_deserializerimport boto3, csv, io, json
import numpy as np
from scipy.sparse import lil_matrixnbUsers=943
nbMovies=1682
nbFeatures=nbUsers+nbMoviesnbRatingsTrain=90570
nbRatingsTest=9430# For each user, build a list of rated movies.
# We'd need this to add random negative samples.
moviesByUser = {}
for userId in range(nbUsers):
moviesByUser[str(userId)]=[]
with open('ua.base.shuffled','r') as f:
samples=csv.reader(f,delimiter='\t')
for userId,movieId,rating,timestamp in samples:
moviesByUser[str(int(userId)-1)].append(int(movieId)-1)def loadDataset(filename, lines, columns):
# Features are one-hot encoded in a sparse matrix
X = lil_matrix((lines, columns)).astype('float32')
# Labels are stored in a vector
Y = []
line=0
with open(filename,'r') as f:
samples=csv.reader(f,delimiter='\t')
for userId,movieId,rating,timestamp in samples:
X[line,int(userId)-1] = 1
X[line,int(nbUsers)+int(movieId)-1] = 1
if int(rating) >= 4:
Y.append(1)
else:
Y.append(0)
line=line+1
Y=np.array(Y).astype('float32')
return X,YX_train, Y_train = loadDataset('ua.base.shuffled', nbRatingsTrain, nbFeatures)
X_test, Y_test = loadDataset('ua.test',nbRatingsTest,nbFeatures)print(X_train.shape)
print(Y_train.shape)
assert X_train.shape == (nbRatingsTrain, nbFeatures)
assert Y_train.shape == (nbRatingsTrain, )
zero_labels = np.count_nonzero(Y_train)
print("Training labels: %d zeros, %d ones" % (zero_labels, nbRatingsTrain-zero_labels))print(X_test.shape)
print(Y_test.shape)
assert X_test.shape == (nbRatingsTest, nbFeatures)
assert Y_test.shape == (nbRatingsTest, )
zero_labels = np.count_nonzero(Y_test)
print("Test labels: %d zeros, %d ones" % (zero_labels, nbRatingsTest-zero_labels))
Once the training and testing dataset is ready, we will move on to the next step.

4. Convert the samples to protobuf format and store in s3:
In this step, we will convert the dataset to protobuf format as Sagemaker accepts this format for a training job for the factorization machine and save it to s3.
bucket = 'movierecommendationdemo'
prefix = 'sagemaker/fm-movielens'train_key = 'train.protobuf'
train_prefix = '{}/{}'.format(prefix, 'train3')test_key = 'test.protobuf'
test_prefix = '{}/{}'.format(prefix, 'test3')output_prefix = 's3://{}/{}/output'.format(bucket, prefix)def writeDatasetToProtobuf(X, Y, bucket, prefix, key):
buf = io.BytesIO()
smac.write_spmatrix_to_sparse_tensor(buf, X, Y)
buf.seek(0)
obj = '{}/{}'.format(prefix, key)
boto3.resource('s3').Bucket(bucket).Object(obj).upload_fileobj(buf)
return 's3://{}/{}'.format(bucket,obj)
train_data = writeDatasetToProtobuf(X_train, Y_train, bucket, train_prefix, train_key)
test_data = writeDatasetToProtobuf(X_test, Y_test, bucket, test_prefix, test_key)
print(train_data)
print(test_data)
print('Output: {}'.format(output_prefix))
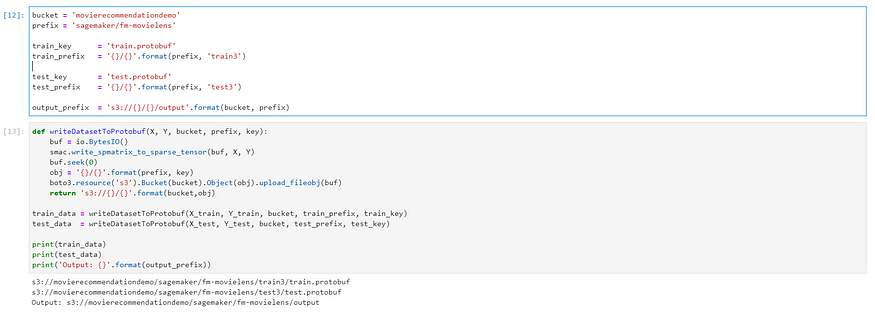
Once the artifacts are saved you can see them in the s3 bucket.

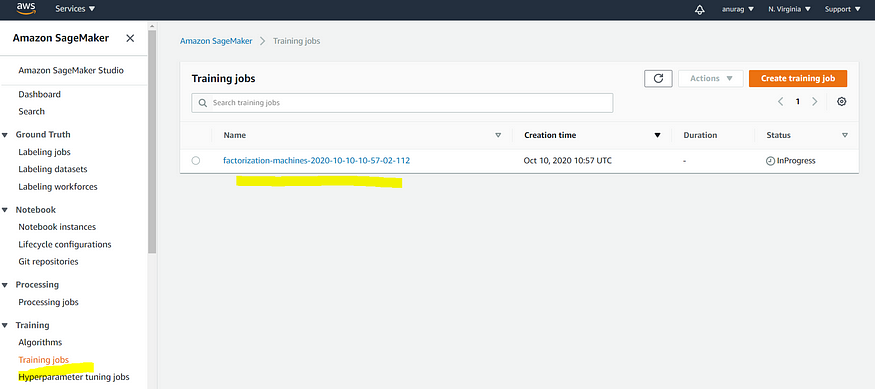
5. Run the training job:
The next step is to create a training job and run it using predefined hyperparameters.
The following code will trigger the training job.
containers = {'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/factorization-machines:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/factorization-machines:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/factorization-machines:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/factorization-machines:latest'}fm = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
get_execution_role(),
train_instance_count=1,
train_instance_type='ml.c4.xlarge',
output_path=output_prefix,
sagemaker_session=sagemaker.Session())fm.set_hyperparameters(feature_dim=nbFeatures,
predictor_type='binary_classifier',
mini_batch_size=1000,
num_factors=64,
epochs=100)fm.fit({'train': train_data, 'test': test_data})
Once the training job starts, the user can track it from the dashboard under the training job section.
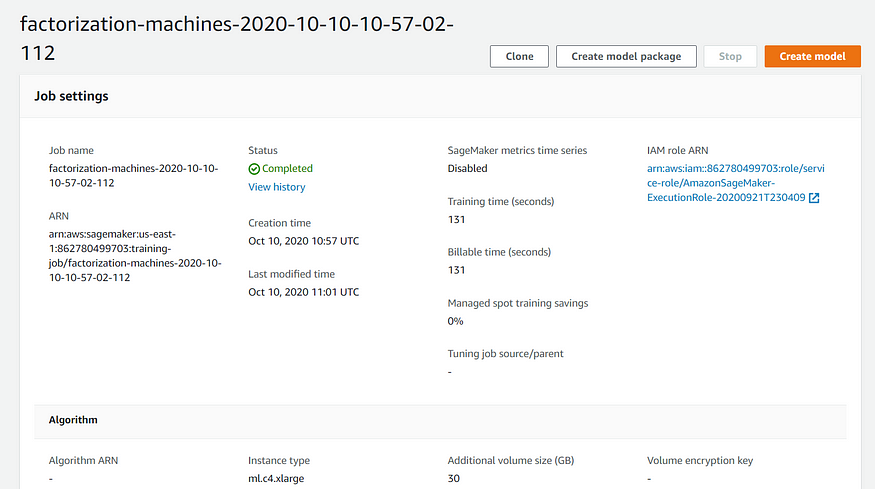
Once the training job is completed you can start using the trained model. Also, you can tune the hyperparameters using hyperparameter jobs. You can refer back to my post where I showed how to use hyperparameter tuning jobs
6. Deploy the baseline model:
Now we can deploy our model by invoking the API programmatically or deploying it using the sagemaker dashboard.
fm_predictor = fm.deploy(instance_type='ml.c4.xlarge', initial_instance_count=1)def fm_serializer(data):
js = {'instances': []}
for row in data:
js['instances'].append({'features': row.tolist()})
#print js
return json.dumps(js)fm_predictor.content_type = 'application/json'
fm_predictor.serializer = fm_serializer
fm_predictor.deserializer = json_deserializer

Once the endpoint is created, you can run the predictions to get recommendations on the movie for the set of users.
result = fm_predictor.predict(X_test[1000:1010].toarray())
print(result)
print (Y_test[1000:1010])
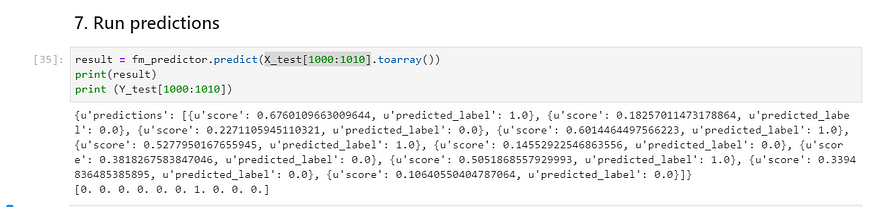
Here predicted label (0 or 1) represents whether the user should watch movies or not with confidence scores.
7. Clean up activities:
To avoid any incurring charges, it is a good practice to delete endpoints, artifacts in the s3 bucket.
sagemaker.Session().delete_endpoint(fm_predictor.endpoint)
You also need to delete any endpoint configuration along with endpoints.
Delete any created models.
Note: Stop any running notebook instances (delete if necessary after termination)

You can also delete any artifacts in the S3 bucket.
You can find the full jupyter notebook here.
Hope you enjoyed this post, let me know about your thoughts if you have any queries or suggestions, would love to hear more from you. If you are enjoying the AI journey, stay tuned its going to be fun in future posts.
You can follow me for tutorials on AI/machine learning, data analytics, and BI. You can connect with me on LinkedIn.
References:
- Amazon Web Services Training
- Google Cloud Training
- Algorithm whitepaper
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



