


NLP News Cypher | 10.11.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 10.11.20
An Ode to Code
Hey, welcome back! We have another great NLP Cypher for this week. And as always, if you enjoy the read, please give it a U+1F44FU+1F44F and share it with your enemies.
Also, we updated the Big Bad NLP Database and Super Duper NLP Repo with 14 news datasets and 5 new notebooks. Would like to thank Tathagata Raha, Don Tuggener, and Yanai Elazar for their awesome contribution. U+1F469U+1F4BB
New: one of the notebooks includes “speech-to-text” inference from Silero U+1F601
FYI: the majority of the BBND update came from the CodeXGLUE benchmark (released last month) with several datasets used for machine learning in code-related tasks (i.e. code completion or code-2-code translation just to name a few). Here’s the whole picture U+1F447:
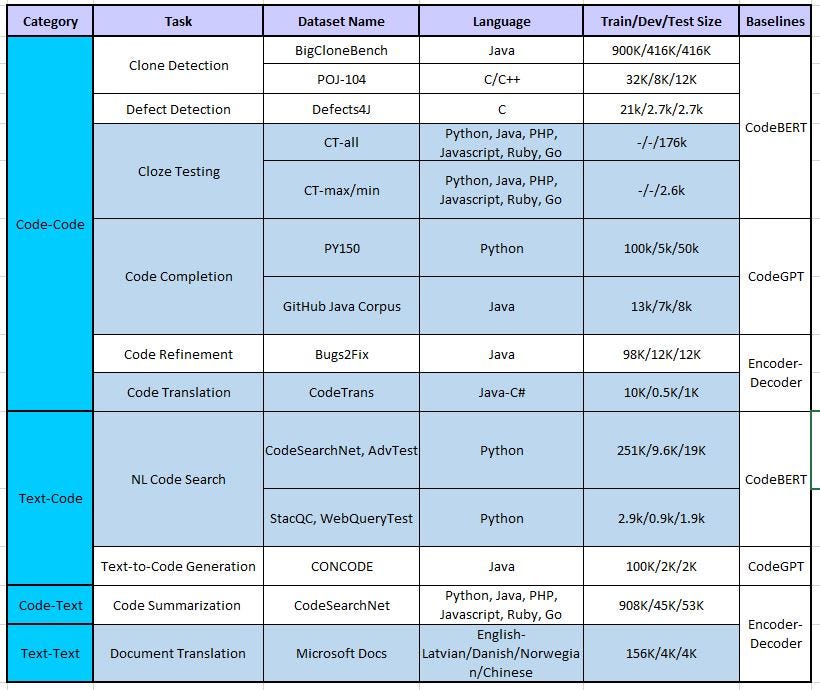
Show me the Code!
Like to eerily stalk preprints on arXiv for code? Now there’s a special button tab on arXiv to gain access to a machine learning paper’s source code (if available)! Winning! U+1F60E
Blog:
New arXivLabs feature provides instant access to code
When a reader activates the Code tool on the arXiv abstract record page, the author's implementation of the code will…
blog.arxiv.org
This Week
Legal BERT
Indic BERT
Intent Detection in the Wild
Wikipedia2Vec
Data Augmentation for Text
State of AI Report 2020
Honorable Papers
Dataset of the Week: eQASC
Legal BERT
Straight out of EMNLP, we now have pre-trained models for the Legal domain called Legal BERT! These models were trained with an eye for application in the legal research, computational law, and legal technology fields. For the training, the model was exposed to12 GB of English legal text derived from legislation, court cases, and contracts. U+1F447
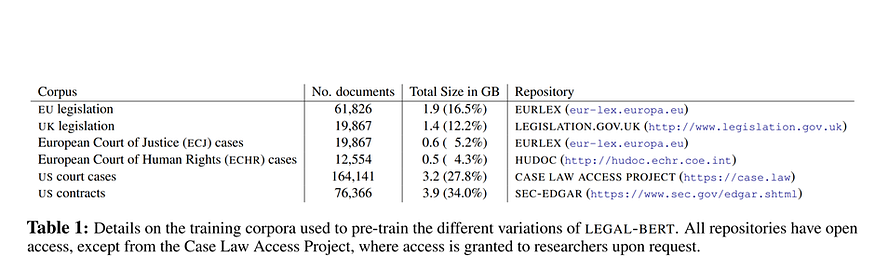
Where were some of the best performance gains?
“Performance gains are stronger in the most challenging end-tasks (i.e., multi-label classification in ECHR-CASES and contract header, and lease details in CONTRACTS-NER)”
*The model was evaluated on text classification and sequence tagging tasks.
Paper: https://arxiv.org/pdf/2010.02559.pdf
Los Modelos:
nlpaueb (AUEB NLP Group)
We're on a journey to solve and democratize artificial intelligence through natural language.
huggingface.co
Indic BERT
If you are interested in Indic languages checkout Indic BERT library built on HF transformers U+1F440. Their multi-lingual ALBERT model has support for 12 languages and was trained on a custom 9 billion token corpus. The library holds a multitude of evaluation tasks:
News Category Classification, Named Entity Recognition, Headline Prediction, Wikipedia Section Title Prediction, Cloze-style Question Answering (WCQA, Cross-lingual Sentence Retrieval (XSR) and many more.
GitHub:
AI4Bharat/indic-bert
Indic bert is a multilingual ALBERT model that exclusively covers 12 major Indian languages. It is pre-trained on our…
github.com
Thank you Tathagata for forwarding their model to us!
Colab of the Week
Google Colaboratory
Edit description
colab.research.google.com
Intent Detection in the Wild
Bottom line: we need more real-world* datasets. In this recent Haptik paper, the authors showed how 4 NLU platforms (RASA, Dialogflow, LUIS, Haptik) and BERT performed when given 3 real-world datasets containing in and out-of-scope queries. (results were mixed given difficulties in generalizing to the test sets of the data)
What kind of datasets?
“Each dataset contains diverse set of intents in a single domain — mattress products retail, fitness supplements retail and online gaming…”
*Real-world here means real user queries as opposed to crowdsourcing.
Find the data here:
hellohaptik/HINT3
This repository contains datasets and code for the paper "HINT3: Raising the bar for Intent Detection in the Wild"…
github.com
Paper: https://arxiv.org/pdf/2009.13833.pdf
Wikipedia2Vec
Have you heard of Wikipedia2Vec, it’s been around for a couple of years now. It contains embeddings of words and concepts that have corresponding pages in Wikipedia. Since Wikipedia is one of the most researched dataset in IR, this may come in handy to you. Their embeddings come in 12 languages and they include an API.
Wikipedia2Vec
Wikipedia2Vec is a tool used for obtaining embeddings (or vector representations) of words and entities (i.e., concepts…
wikipedia2vec.github.io
Applications of Wikipedia2Vec:
- Entity linking: Yamada et al., 2016, Eshel et al., 2017, Chen et al., 2019, Poerner et al., 2020.
- Named entity recognition: Sato et al., 2017, Lara-Clares and Garcia-Serrano, 2019.
- Question answering: Yamada et al., 2017, Poerner et al., 2020.
- Entity typing: Yamada et al., 2018.
- Text classification: Yamada et al., 2018, Yamada and Shindo, 2019.
- Relation classification: Poerner et al., 2020.
- Paraphrase detection: Duong et al., 2018.
- Knowledge graph completion: Shah et al., 2019.
- Fake news detection: Singh et al., 2019.
- Plot analysis of movies: Papalampidi et al., 2019.
- Enhancement of BERT using Wikipedia knowledge: Poerner et al., 2019.
- Novel entity discovery: Zhang et al., 2020.
- Entity retrieval: Gerritse et al., 2020.
Paper: https://arxiv.org/abs/1812.06280
Data Augmentation for Text
NLPaug is a handy library used for data augmentation where you can inject noise in your dataset on the character or word level that improves model performance.
Here’s an example of what I mean:
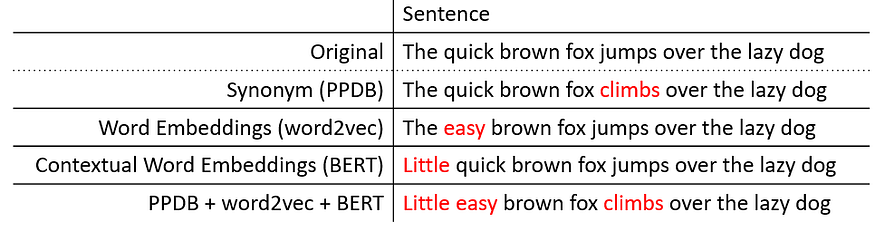
Here are a few of its features:
Character: OCR Augmenter, QWERTY Augmenter and Random Character AugmenterWord: WordNet Augmenter, word2vec Augmenter, GloVe Augmenter, fasttext Augmenter, BERT Augmenter, Random Word CharacterFlow: Sequential Augmenter, Sometimes Augmenter
Blog post on the library:
Data Augmentation library for text
In previous story, you understand different approaches to generate more training data for your NLP task model. In this…
towardsdatascience.com
GitHub:
makcedward/nlpaug
This python library helps you with augmenting nlp for your machine learning projects. Visit this introduction to…
github.com
Secret: There’s an nlpaug colab in the SDNR U+1F446
State of AI Report 2020
The annual of State of AI Report is out and NLP is winning big.
TL;DR on the NLP side of things:
Only 15% of papers publish their code.
Facebook’s PyTorch is fast outpacing Google’s TensorFlow in research papers.
Larger model needs less data than a smaller peer to achieve the same performance.
Biology is experiencing its “AI moment”: Over 21,000 papers in 2020 alone.
Brain drain of academics leaving university for tech companies.
A rise of MLOps in the enterprise.
NLP is used to automate quantification of a company’s Environmental, Social and Governance (ESG) perception using the world’s news.
Model and dataset sharing is driving NLP’s Cambrian explosion.
State of AI Report 2020
The State of AI Report analyses the most interesting developments in AI. We aim to trigger an informed conversation…
www.stateof.ai
Honorable Papers
Paper: https://arxiv.org/pdf/2009.13013.pdf Sparse Open Domain QA
Paper: https://arxiv.org/pdf/2010.03099.pdf Novel Framework for Distillation
Paper: https://arxiv.org/pdf/2010.03604.pdf Semantic Role Labeling Graphs
Dataset of the Week: eQASC
What is it?
Dataset contains 98k 2-hop explanations for questions in the QASC dataset, with annotations indicating if they are valid or invalid explanations.
Sample:

Where is it?
eQASC: Multihop Explanations for QASC Dataset – Allen Institute for AI
This repository addresses the current lack of training data for distinguish valid multihop explanations from invalid…
allenai.org
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

