



An Introduction to Federated Learning
Last Updated on September 30, 2022 by Editorial Team
Author(s): Chinmay Bhalerao
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Data privacy and security with Federated learning
People in the AI-ML-DL field often asked about privacy concerns of data and data security which is fairly logical because after training models on a wide variety of datasets, what should be the strategy to deal with data and its privacy?
Two significant obstacles still exist for modern AI. One is that data typically exists as isolated islands in different businesses. The other is the improvement of data security and privacy. In the current most hyped learning and training methods, we bring our datasets towards a fixed and centralized model on which insights extraction happens. transferring data from system to system, database to database, is quite challenging, and data leakage and data stealing can be done.
Federated Learning is the emerging model learning method that has a solution for all the above-mentioned problems. Let's see Federated Learning in detail. A very brute force or dictionary meaning of the federated word is “to unite under a central government or organization while keeping some local control” How this meaning is related to actual federated learning, we will see in the next sections of the blog.
What if I can bring my local model towards data and not data towards the model? Let's understand this by a simple example by google.ai federated learning blog. Any mobile app that interacts with users can be used to train a machine learning model, which tries to learn from user interactions. On numerous mobile devices, an ML model will be trained simultaneously. This trained model provides updates, which are then transmitted to a centralized server or model. The inputs provided by the induvial model will be used to update the centralized model. Once more, a centrally updated model will be sent to your devices.
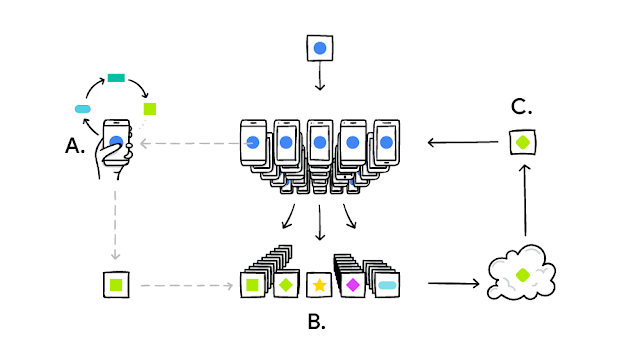
Our device downloads the current model, improves it by learning from data on your phone and then summarizes the changes as a small, focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on your device, and no individual updates are stored in the cloud.
Explaining this, you don’t have centralized data. You have data distributed across different locations and devices, and now you want to train a machine learning model.
According to me, The biggest concern of data privacy and data security is getting channelized here. The data is at the user’s location, and the updated models are sent to the centralized system. The advantage of federated learning is you are not bringing data towards the model, but you are bringing the model toward the data. Training an algorithm at different local edges or servers and using it as a data sample from the population.
Companies can benefit from accurate machine learning models, but typical centralized machine learning systems have limitations, such as not continuously learning on edge devices and aggregating private data on central servers. Federated learning helps to mitigate these issues.
In conventional machine learning, a central ML model is created using all training data that is accessible in a centralized setting. When predictions can be served by a central server, this operates without any problems.
A pleasant user experience may be compromised by the communication delay between a user device and a central server in mobile computing since users expect quick responses. The model might be installed in the end-user device to address this, but since models are trained on entire data sets, ongoing learning becomes difficult.
Federated learning in the healthcare industry:
Large, diverse, and high-quality datasets provide experience for AI algorithms. Such statistics, however, have historically been difficult to find, particularly in the healthcare industry.
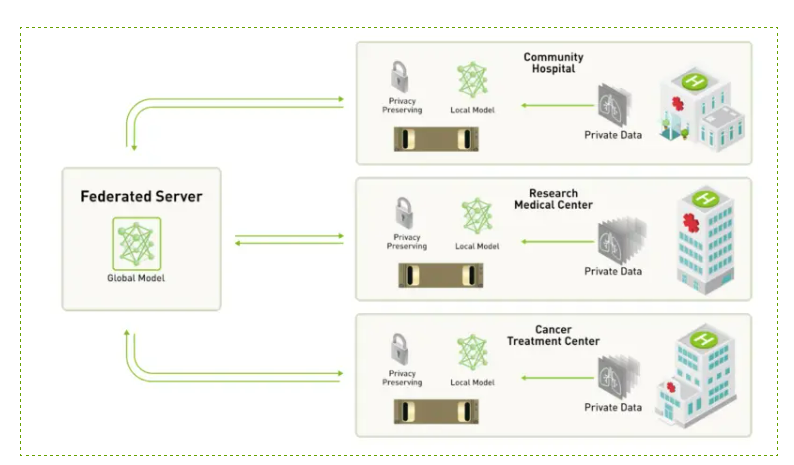
Medical organizations have been forced to rely on their own data sources, which can be skewed by factors like patient demographics, the tools employed, or clinical specialties. Or, to obtain all the necessary data, they had to combine data from other institutions.
According to BrainTorrent: A Peer-to-Peer Environment for Decentralized Federated Learning paper, A frequent difficulty in training deep neural networks on medical imaging is gaining access to enough labeled data. As data annotation is costly and time-consuming, it is challenging for a single medical center to obtain sufficient sample quantities to create its own customized models. To avoid this, data from all centers might be gathered and used to train a centralized framework that is accessible to anyone. However, this tactic is frequently used. due to the private nature of medical data, it's impractical. Federated learning (FL) has recently been developed to enable the cooperative learning of a shared prediction model across centers without the requirement for data exchange. In FL, users train models locally on site-specific datasets for a few epochs before sharing their model weights with a centralized server, which manages the entire training procedure. It’s vital that the privacy of patients is not jeopardized by model sharing.
Federated learning in IoT :
The Internet of Things (IoT) is developing, opening up new options for real-time data collection and machine learning model deployment. However, a single IoT device might not have the computational power to develop and implement a full learning model. In addition to raising concerns about data security and privacy, sending continuous real-time data to a central server with powerful computational capabilities incurs large transmission costs. According to the paper, a promising approach to training machine learning models on edge servers and devices with constrained resources is federated learning, a distributed machine learning framework.
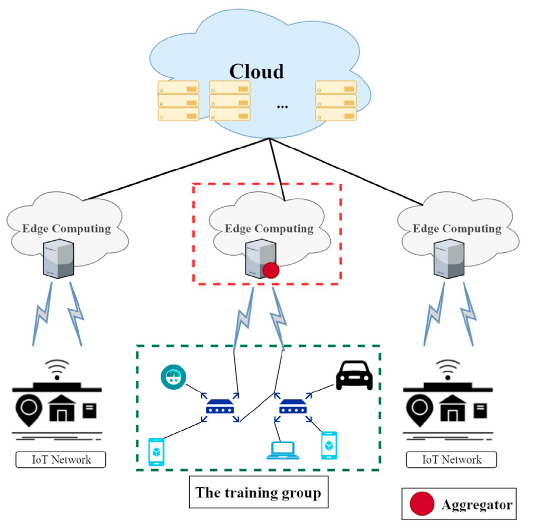
powered IoT system [source link]
However, the majority of studies in existence assume an impractically synchronous parameter update method with uniform IoT nodes connected via stable communication links. We create an asynchronous federated learning strategy in this paper to increase training effectiveness for different IoT devices under varying networks. To effectively complete learning tasks, we build a lightweight node selection algorithm and an asynchronous federated learning model. In order to participate in the global learning aggregate, the proposed approach iteratively chooses heterogeneous IoT nodes while taking into account their local processing capacity and communication state. This paper concluded how data collection and processing from IoT devices give state-of-art results.
It appears like federated Learning has a lot of potential. Not only does it protect sensitive user data, but it also aggregates data from many users, searches for common patterns, and strengthens the model over time. It develops itself based on user data, safeguards it, and then reemerges as a wiser individual who is once more prepared to put itself to the test with its own users! Testing and training got smarter! Federated Learning ushered in a new era of secured AI, whether it be in training, testing, or information privacy. The design and implementation of federated learning still present many difficulties because it is still in its initial form. Designing a data pipeline and defining the Federated Learning problem are two effective ways to address this obstacle.
Open-Source Software for Federated Learning
· FATE
· Substra
· PySyft
· OpenFL
Effectiveness of federated learning
Data security: Keeping the training set on the devices will ensure data security and eliminate the requirement for a data pool for the model.
Data diversity: Other problems, like network unavailability in edge devices, may prohibit businesses from merging datasets from numerous sources. Federated learning makes it simpler to access a variety of data, even when certain data sources can only communicate occasionally.
Real-time continuous learning: Models are continuously updated utilizing client data without the need to aggregate data.
Hardware effectiveness: This strategy uses less sophisticated hardware since federated learning models do not need a single complex central server to analyze data.
References :
- Stefano Savazzi, Monica Nicoli and Vittorio Rampa, Federated Learning with Cooperating Devices: A Consensus Approach for Massive IoT Networks(2019),arXiv:1912.13163v1 [eess.SP] 27 Dec 2019
- ViraajiMothukuriaReza,M.PariziaSeyedamin, Pouriyehb, Yan Huanga, AliDehghantanhac, Gautam Srivastava, A survey on security and privacy of federated learning(2021), Future Generation Computer Systems, volume 115
- Rithesh Sreenivasan, What is Federated Learning (Youtube video)
- IstvánHegedűs, Gábor Danner and Márk Jelasity, Decentralized learning works: An empirical comparison of gossip learning and federated learning(2021), Journal of Parallel and Distributed Computing(Volume 148)
- Wenqi Li, Fausto Milletar, Daguang Xu, Nicola Rieke, Jonny Hancox, Wentao Zhu, Maximilian Baust, Yan Cheng , S´ebastien Ourselin , M. Jorge Cardoso and Andrew Feng, Privacy-preserving Federated Brain Tumour Segmentation(Oct2019),Biomedical Engineering and Imaging Sciences, King’s College London, UK
- Brendan McMahan and Daniel Ramage, Research Scientists, Federated Learning: Collaborative Machine Learning without Centralized Training Data(2017), Google AI Blog
- NICOLA RIEKE, What Is Federated Learning?(2019), Nvidia blog
- Alpharis(2022),Apheris federated learning
If you find this insightful
If you found this article insightful, follow me on Linkedin and medium. you can also subscribe to get notified when I publish articles. Thanks for your support!
An Introduction to Federated Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

