



A Simple Adjustment Improves Out-of-Distribution Detection for Any Classifier
Last Updated on July 25, 2023 by Editorial Team
Author(s): Ulyana Tkachenko
Originally published on Towards AI.
Authors: Ulyana Tkachenko, Jonas Mueller, Curtis G. Northcutt
Anyone who has tried training ML models on real-world datasets (not the perfectly curated data we work with in school) has probably dealt with outliers in data. The problem with most outlier and Out-of-Distribution (OOD) detection algorithms is that they make a big assumption — that a model is equally confident in all classes — most of the time, that big assumption is false. For example, a model trained on ImageNet is typically overconfident (predicted probabilities close to 1) for bananas but underconfident (low predicted probabilities close to 0) for the ten different but very similarly-looking lizard classes in the dataset.
In this article, I’ll show you a novel and simple adjustment to model predicted probabilities that can improve OOD detection with models trained on real-world data. Introduced here for the first time, this unique approach is rooted in theory and runs in just a couple of lines of code.
Background
Identifying outliers in test data that do not stem from the distribution of the training data is critical for deploying reliable machine learning models. While many special (e.g., generative) models have been proposed for this task of Out-of-Distribution (a.k.a. anomaly/novelty) detection¹ ² ³, these are often specific to particular data types and nontrivial to implement. Instead, simpler methods for OOD detection that use an already-trained classifier on data with class labels have become quite popular⁴ ⁶. Methods like KNN distance⁵ ⁷ and Mahalanobis Distance³ ⁴ leverage a trained neural network’s intermediate feature representations to identify OOD examples.
An even simpler approach is to only use the predicted class probabilities output by the trained classifier and quantify their uncertainty as a measure of outlyingness. Two particularly popular OOD methods are Maximum Softmax Probability (MSP)⁶ or Entropy⁴ ⁵. Compared to most other methods, MSP and Entropy need less information from the model and require less computing to identify outliers. Here we introduce a simple improvement to these baseline methods to improve their effectiveness.
Baseline prediction-based OOD detection methods
Consider an image x and classifier model p = h(x) where p is the model’s predicted probability vector that this image belongs to each class k ∈ {1,…,K}. Based on p, one can compute two simple OOD scores for x.
Maximum Softmax Probability (MSP) — quantifies how confident the model is in the most likely class it predicts:

Entropy — quantifies how evenly spread the model’s probabilistic predictions are amongst all K classes:

These scores have been shown to work surprisingly well for detecting OOD images⁶, despite the fact that they do not explicitly estimate epistemic uncertainty⁴.
Simple adjustment to Improve Baseline Methods
The model predicted probabilities p are subject to estimation error. Trained models can have a biased propensity to predict specific classes over others, particularly when the classes in the original dataset are imbalanced. To account for these issues, we adjust the predicted probabilities using class confident thresholds¹⁴, forming new OOD scores based on the MSP/Entropy of the resulting adjusted predictions.
Calculating Class Confident Thresholds
Letting yᵢ denote the class label for the i-th example in our training data and pᵢₖ denote the probability that this example xᵢ belongs to class k according to our model, we compute a confident threshold vector whose k-th element is defined as:
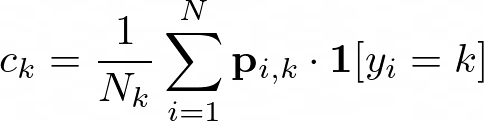
k where Nₖ denotes the number of training examples labeled as class kThe confidence thresholds are the average probability of a class predicted by our model amongst the examples labeled as that class. This vector thus represents our model’s propensity to predict a particular class for examples labeled as that class and has been proven to be a natural threshold for determining the reliability of probabilistic predictions¹⁴.
Adjusting Model Predicted Probabilities for Noise
For any new example x, its predicted probability vector p = h(x) is subsequently adjusted by the class confident threshold as follows:

Here cࠡ is the largest value in the confident threshold vector (to ensure nonnegative probabilities) and Z is the normalizing constant (to ensure the probabilities sum to one over the classes):

cࠡ and normalizing constant ZIt is important to note that while confident thresholds vector c is always calculated using the train-predicted probabilities and labels. Any model output predicted probabilities (i.e., for additional test data) could be adjusted using these thresholds.
Computing adjusted OOD scores
Improved OOD scores for x are achieved simply by plugging in the adjusted predicted probabilities p̃ in the place of p into either of the respective MSP/Entropy formulas. This adjusted OOD detection procedure thus remains extremely simple and is easy to implement in practical deployments.
Benchmarking Performance
Following standard OOD benchmarking procedures, existing image classification datasets are grouped in pairs where: one dataset is used to train a Swin Transformer⁸ classifier and considered in-distribution training data, while examples from the second dataset are mixed in with the testing data of the first dataset (at a 50–50 ratio) as out-of-distribution images. Each OOD scoring method is applied to all images in the test set (without knowledge of their source or their labels) to produce a ranking of these images, which we evaluate using the AUROC for how well these scores detect OOD examples.

We consider 2 different OOD detection problems based on popular image classification datasets: CIFAR-10⁵ vs. CIFAR-100⁵ and MNIST⁶ vs. FASHION-MNIST⁷. Our first benchmark relies on the original versions of these datasets, where classes naturally occur in equal proportions.
We also run a second benchmark in which we introduce class imbalance in each training set. Here we create new imbalanced training sets for CIFAR-10, MNIST, and FASHION-MNIST, where in each training set: 6 classes each contain 2% of the total examples and 4 classes each contain 22% of the examples. We also create an imbalanced training set for CIFAR-100 in which 90 classes each have 0.63% of the examples, and 10 classes each have 4.25% of the examples. This allows us to evaluate how well our OOD scores perform in settings where the classes occur in unequal proportions in the labeled training data, as is often the case in real-world applications.
Improved Baseline Method Results
Tables 1 and 2 list the AUROC performance achieved by both adjusted and original (non-adjusted) OOD scoring methods for each benchmark setting. For many in-distribution / OOD dataset pairs, there is a clear improvement that results from our proposed adjustment.


With only a minor adjustment to the predicted probabilities output by a trained classifier, the performance of both Entropy and MSP-based out-of-distribution detection scores is increased.
Code to run this OOD method on any dataset has been made available here.
References
[1] Yang, J., Zhou, K., Li, Y., and Liu, Z. Generalized out-of-distribution detection: A survey. arXiv:2110.11334. 2021.
[2] Ran, X., Xu, M., Mei, L., Xu Q., and Liu Q. Detecting out-of-distribution samples via variational auto-encoder with reliable uncertainty estimation. Neural Networks. 2022.
[3] Cao, S., and Zhang, Z. Deep Hybrid Models for Out-of-Distribution Detection. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Kirsch, A., Mukhoti, J., van Amersfoort, J., Torr, P. H. S., and Gal, Y. On pitfalls in OOD detection: Entropy considered harmful. ICML Workshop on Uncertainty and Robustness in Deep Learning. 2021.
[5] Kuan, J., and Mueller, J. Back to the Basics: Revisiting Out-of-Distribution Detection Baselines. ICML Workshop on Principles of Distribution Shift. 2022
[6] Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations, 2017.
[7] Angiulli, F. and Pizzuti, C. Fast outlier detection in high dimensional spaces. In European conference on principles of data mining and knowledge discovery, 2002.
[8] Lee, K., Lee, K., Lee, H., and Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31, 2018.
[9] Fort, S., Ren, J., and Lakshminarayanan, B. Exploring the limits of out-of-distribution detection. Advances in Neural Information Processing Systems, 34, 2021.
[10] Krizhevsky, A. Learning multiple layers of features from tiny images. 2009.
[11] Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012
[12] Xiao, H., Rasul, K., and Vollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
[13] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
[14] Northcutt C, Jiang L, Chuang I. Confident learning: Estimating uncertainty in dataset labels. Journal of Artificial Intelligence Research. 2021.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

