


7 Lessons From Fast.AI Deep Learning Course
Last Updated on November 6, 2023 by Editorial Team
Author(s): Mariya Mansurova
Originally published on Towards AI.
I’ve recently finished the Practical Deep Learning Course from Fast.AI. I’ve passed many ML courses before, so that I can compare. This one is definitely one of the most practical and inspiring. So, I would like to share my main takeaways from it with you.
About the course
The Fast.AI course is led by Jeremy Howard, a founding researcher of Fast.AI. He also used to be #1 on the Kaggle leaderboard. So you definitely can trust his expertise in Machine Learning and Deep Learning.
The course covers the basics of Deep Learning and Neural Networks and also explains Decision Tree algorithms. The current version is from 2022, so I suppose the content has changed since previous reviews on TDS.
This course is designed for people with some programming experience. In most cases, code examples are used instead of formulas. I must confess that it’s easier for me to understand code after writing it for ages, even though I have a master’s degree in Maths.
The other nice feature of this course is a top-down approach. You start with the working ML model. For example, I made my first DL-powered app during the course’s second week. It’s an image classifier which can detect my favourite breeds of dogs. Then, within the following weeks, you dive deeper and understand how it all works.
Let’s move on to my main takeaways from this course.
Lesson #1: Maths you need to know to understand Deep Learning
Let’s start simple. I promise the following takeaways will be less trivial.
I believe it’s important to talk about it because many people are intimidated by Deep Learning. DL is considered rocket science, but it’s based on a few mathematical concepts you could learn in a day.
Neural Network is a combination of linear functions and activations. Here’s a linear function.
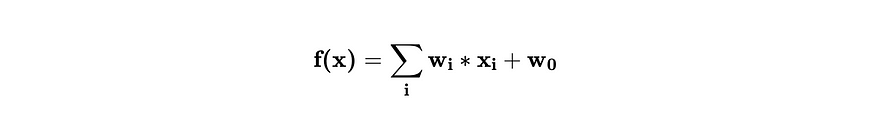
Since a combination of linear functions is also linear, we need activations that will add non-linearity.
The most common activation function is ReLU (Rectified Linear Unit). It may sound scary, but actually, it’s just a function like this.
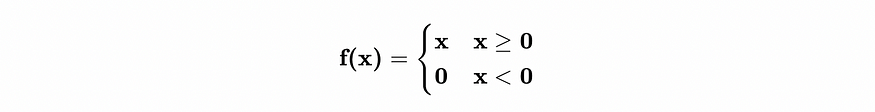
You can think about it as the barrier that signals need to overcome. If a signal is below the threshold (0 in our case), its information won’t pass to the next layer of the Neural Network.

A couple of other mathematical concepts that are used:
- SGD (Stochastic Gradient Descent) — an optimisation approach based on gradient calculation. You can read an article to get a high-level understanding of how it works.
- Matrix multiplication helps to perform calculations faster in batches. There’s an excellent article about it as well.
If you would like to learn it in all detail, see the lesson on Neural net foundations from Fast.AI course.
Lesson #2: How to clean your data
We are used to starting analysis with cleaning data. We’ve all heard the mantra “garbage in — garbage out” many times. Surprisingly, fitting a model first and then using it to clean your data may be more effective.
You can train a simple model and then look at cases with the highest loss to find potential problems. In my previous article, this approach helped me to spot mislabelled images.

Build your first Deep Learning app within an hour
Deploying Image Classification Model using HuggingFace Spaces and Gradio
towardsdatascience.com
Lesson #3: How to choose a Computer Vision model
There are so many pre-trained models nowadays. For example, PyTorch Image Models (timm) has 1 242 models.
import timm
pretrained_models = timm.list_models(pretrained=True)
print(len(pretrained_models))
print(pretrained_models[:5])
1242
['bat_resnext26ts.ch_in1k',
'beit_base_patch16_224.in22k_ft_in22k',
'beit_base_patch16_224.in22k_ft_in22k_in1k',
'beit_base_patch16_384.in22k_ft_in22k_in1k',
'beit_large_patch16_224.in22k_ft_in22k']
As a beginner, you usually feel stuck with many options. Luckily, there’s a handy tool to pick up Deep Learning Architecture.
This graph shows a relation between time on inference (how long it takes to process one image) and accuracy on Imagenet.

As you might expect, there’s a trade-off between speed and accuracy, so you should decide which is more important. It highly depends on your task. Do you need your model to be faster or more accurate?
It’s better to start with a small model and iterate. The rule of thumb is to create the first model on the first day. So, you could use simple models like Resnet18 or Resnet34 to be able to try different augmentation techniques or external datasets. Since you’re working with a simple model, iterations will be fast. You can move on to slower model architectures when you find the best version.
Advice from Jeremy Howard: “Trying the complex architectures is the very last thing I do”.
Lesson #4: How to train large models on Kaggle
Lots of beginners use Kaggle notebooks for ML. Kaggle GPUs have limited memory, so you may run out of memory, especially when using large models.
There’s a helpful trick that can solve this problem. It’s called Gradient Accumulation. With Gradient Accumulation, we don’t update weights after each batch but sum gradients for K batches. Then, we update the model weight with this accumulated gradient for total batch equal to K * batch_size , so for each iteration we have a K times smaller batch size.
Gradient Accumulation is absolutely mathematically identical unless batch normalisation is used in the model architecture. For example, convnext doesn’t use batch normalisation, so there’s no difference.
With such an approach, we are using significantly less memory. It means there’s no need to buy giant GPUs — you can fit your model even on your laptop.
You can find the full example on Kaggle.
Lesson #5: What ML algorithms to use
Nowadays, there are a lot of different ML techniques. For example, scikit-learn documentation has at least a dozen approaches to Supervised ML.
Jeremy Howard suggested focusing on just a couple of essential techniques:
- If you have structured data, you should start with ensembles of decision trees (Random Forest or Gradient Boosting algorithms).
- The best solution for unstructured data (like natural texts, audio, video or images) is a multilayer neural network.
Neural Networks are also applicable for structured data, but Decision trees are often easier to use:
- You can train a Decision Tree ensemble much faster.
- They have fewer parameters to tune.
- You don’t need a special GPU to train them.
- More than that, Decision Trees are often easier to interpret and understand why you get such a result for each object, for example, which features are the strongest predictors and which ones we can safely ignore.
If we compare Decision Tree ensembles, Random Forest is easier to use (because it’s almost impossible to overfit). However, Gradient Boosting usually gives you a bit better results.
Lesson #6: Handy Python functions
Even though I’ve been using Python and Pandas for almost ten years, I also found a couple of helpful Pandas life hacks.
The well-known Titanic dataset was used to show the power of Pandas. Let’s have a look at it.
The first example shows us how to convert a column to a string, get the first letter and convert using a dictionary. Note that if a value isn’t mentioned in the dictionary, then NaN will be returned.
# my usual approach
decks_dict = {'A': 'ABC', 'B': 'ABC', 'C': 'ABC',
'D': 'DE', 'E': 'DE', 'F': 'FG', 'G': 'FG'}
df['Deck'] = df.Cabin.map(
lambda x: decks_dict.get(str(x)[0])
)
# version from the course
df['Deck'] = df.Cabin.str[0].map(dict(A="ABC", B="ABC", C="ABC",
D="DE", E="DE", F="FG", G="FG"))
The next example shows how to calculate frequency using the transform function. This version is more concise compared to the merge I usually use.
# my usual approach
df = df.merge(
df.groupby('Ticket', as_index = False).PassengerId.count()\
.rename(columns = {'PassengerId': 'TicketFreq'})
)
# version from the course
df['TicketFreq'] = df.groupby('Ticket')['Ticket'].transform('count')
The last example is the most complex one on how to parse titles.
# my usual approach
df['Title'] = df.Name.map(lambda x: x.split(', ')[1].split('.')[0])
df['Title'] = df.Title.map(
lambda x: x if x in ('Mr', 'Miss', 'Mrs', 'Master') else None
)
# version from the course
df['Title'] = df.Name.str.split(', ', expand=True)[1]\
.str.split('.', expand=True)[0]
df['Title'] = df.Title.map(dict(Mr="Mr",Miss="Miss",Mrs="Mrs",Master="Master"))
It’s worth looking at the first part df to understand how it works. You can execute code:df.Name.str.split(‘, ‘, expand=True) and see a data frame where names are split by commas across two columns.

Then, we select column 1 and do a similar split based on the dot. The second line just replaces all cases not equal to Mr , Mrs , Miss or Master with NaNs.
Frankly speaking, I would continue using my usual approach for the last case because IMHO it’s easier to comprehend.
Lesson #7: ML tricks
There are a lot of tricks and helpful techniques or tools mentioned in this course. Here are the ones I found helpful.
Multi-target model
Surprisingly, adding another target to the Neural Network may help you increase your model’s quality.
Jeremy showed an example of a multi-target model for the Paddy Disease Classification competition. The goal of this competition is to predict rice disease by photo. We can predict not only disease but also rice variety, which may help the model learn valuable features. Features useful to predict rice variety may also be helpful for disease detection.
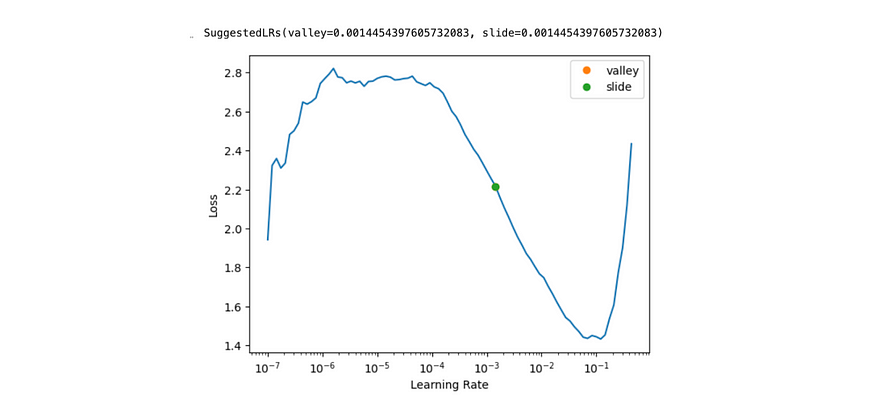
Finding an optimal learning rate
The learning rate defines the step size for each iteration of SGD (Stochastic Gradient Descent). If your learning rate is too small, your model will fit very slowly. If it’s too high, your model may never converge to optimum. That’s why it’s so important to pick the correct learning rate.
Fast.AI provides a tool to help you do it with one line of code learn.lr_find(suggest_funcs=(valley, slide)) .
Test Time Augmentation
Augmentations are changes to the images (for example, contrast improvements, rotations, or crops). Augmentations are often used during training to give a bit different images each epoch. But we can use augmentations at the inference stage as well. This technique is called Test Time Augmentation.

It works pretty straightforward. We generate several versions for each image using augmentations and get predictions for each of them. Then, we calculate the aggregated result using maximum or average. The idea is similar to Bagging.
Enriching dates
You can get more information from your dataset if you have dates in your dataset. For example, instead of just 2023–09–01, you can look at separate features: month, day of the week, year, etc.
Fast.AI has a function add_datepart for it, so you don’t need to implement it yourself.
Unanswered question: Why sigmoid?
During the course, I had only one theoretical question that was not thoroughly covered. As in many other ML courses, there’s no explanation for why we use the sigmoid function and not the other one to convert the output of the linear model to probability. Luckily, there’s a long read where you can find all the answers.
To sum it up, the Fast.AI course has a lot of hidden gems that can give you some food for thought even if you have experience in data science. So, I definitely could advise you to listen to it.
Thank you a lot for reading this article. I hope it was insightful to you. If you have any follow-up questions or comments, please leave them in the comments section.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

