



Image Similarity With Deep Learning Explained
Last Updated on February 5, 2021 by Editorial Team
Author(s): Romain Futrzynski
Deep Learning
Recently I gave a Meetup talk where I discussed two of my favorite topics: neural networks and images. Since my company is launching a feature for image similarity, I thought I would sum up some ideas from this talk and give my take on a few questions:
Why work with similarity?
How does deep learning help?
Why is cosine similarity so widespread?
How is it different from image classification?
What is image similarity?

Similarity is by definition a vague concept. It works well when two humans communicate, but it isn’t the easiest thing to deal with for a deterministic computer program. Think of the two images above: you could easily make anyone agree that they look similar (person in a leather jacket, contemplative, facing left), although some aspects are clearly different (standing vs. sitting, ocean vs. street background, man vs. woman).
If your goal is to evaluate specific aspects of an image then, by all means, design, and train a model for that task. However, if your criteria for “similarity” are visual but not well defined, or if you lack finely labeled data for training, this is where image similarity with deep learning can give you a boost.
Deep learning opens a path to consistently quantify the similarity between images, enabling the automation of even ill-defined tasks.
What can you do with image similarity?

Arguably the most obvious application is reverse searching. I’m somehow old enough to have known a time when keywords ruled the internet, and good luck finding anything without spelling them exactly right.
Reverse searching lets you start with the content and gives you the associated keywords. Nowadays, of course, search engines are a lot more flexible and you may not be interested in finding the keywords, but you might still start from an example and explore by browsing from like to like.

Deep learning similarity techniques are also behind some of the best methods for landmark recognition, if you need help remembering where your vacation pictures were taken. And when you can recognize landmarks all around the world, you might as well check how well it works for face recognition too.
Finally, if you like to have things well organized, image similarity can be applied to data clustering. This allows you to leverage a combination of explicit information, like the type of clothes, and visual features that are learned implicitly by a deep learning model.
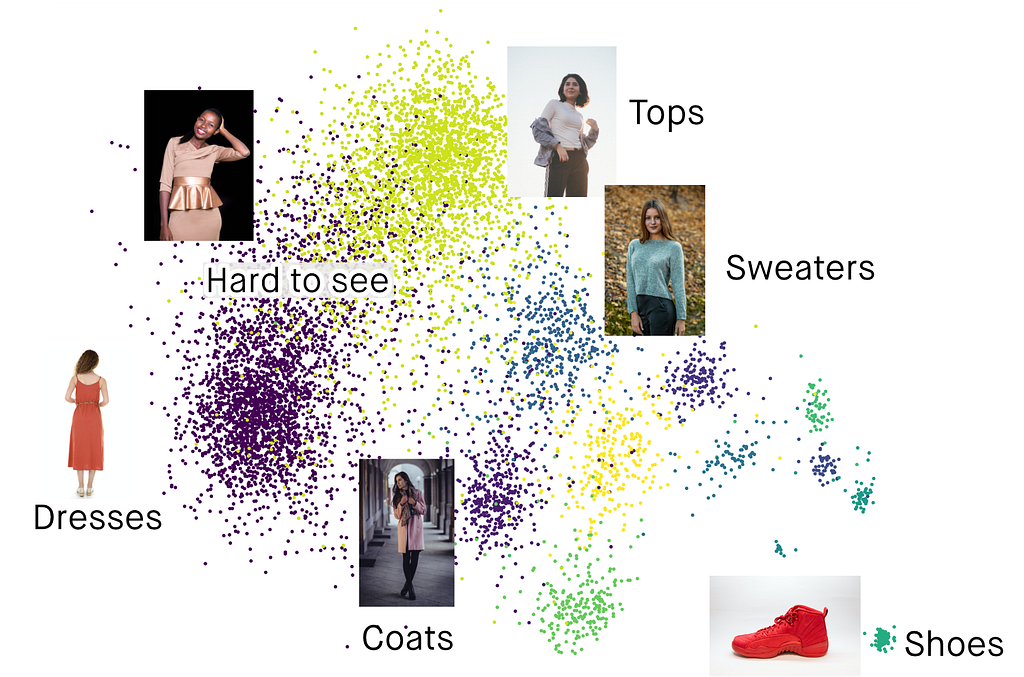
How does image similarity work?
I can’t emphasize enough that similarity is a vague concept. If we want to make any progress without fixing it to a specific definition, we have to think abstractly for a moment.
Let’s say that for any data item, specifically here an image, we want a representation of this data that is easy to compare with other items. If this representation is small in size, searching through thousands of items will be fast (if only by virtue of loading less data from disk). That’s essentially the same idea as creating a hash table of your data, an angle detailed further in Deep Hashing for Similarity Search.
However, unlike a typical hash function, the compressed representations should be comparable to directly indicate the degree of similarity between their corresponding items. Since we haven’t defined what we mean by similar anyway, let’s start with the idea that the data representation should preserve information. This can be guaranteed if there is a way to reconstruct the data from its representation.
So what we’re looking for is a way to compress the data in a meaningful way.
This is where deep neural networks come in handy. In particular, the autoencoder structure checks a lot of useful boxes:
- Preserves information by reconstructing the input
- Can handle various types of data
- Fixed-size compressed representation
- More or less continuous function of input
- Trainable for noise robustness
- Fine-tunable for specific meaning of “similar”
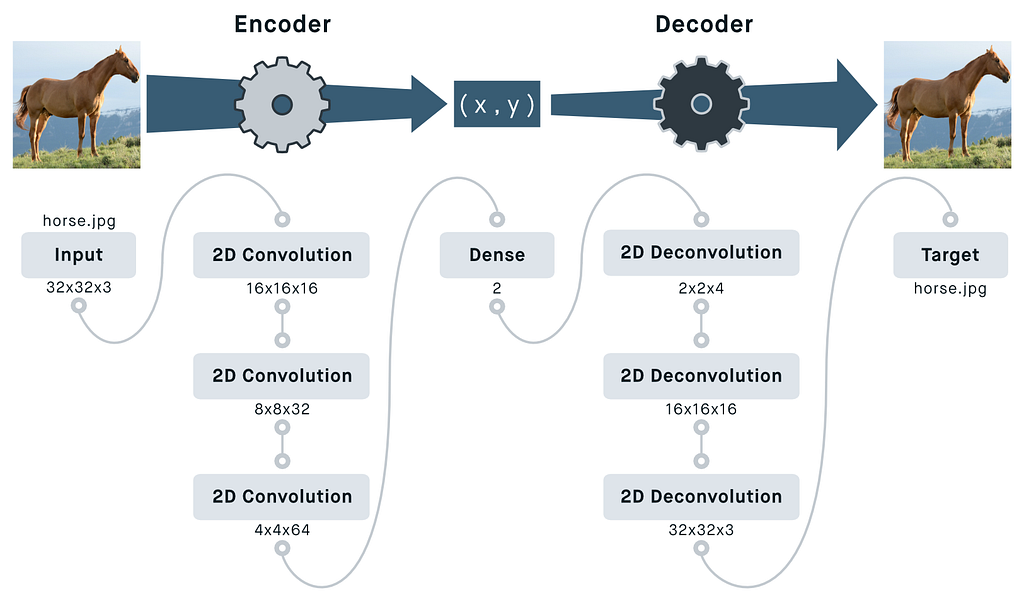
The fact that autoencoders are (more or less) continuous functions of their input, and that they can be trained for noise robustness, is very good news for similarity applications. It means that inputs that look the same should have nearly identical compressed representations.
However, it could be argued that if the decoder is allowed to be arbitrarily complex, it could possibly behave more like a hash function. This would make it difficult to compare the compressed embeddings directly.
That’s why in practice, the base architecture of similarity models resembles classifier networks more than autoencoders. Arguably this preserves much less information, but it allows to make comparisons with the cosine similarity. Not to mention that classifier networks are much more widespread and easier to train than autoencoders.
Why use cosine similarity?
When it comes to similarity, “cosine similarity” is on everyone’s lips as it’s the operation that is almost always used to measure how close two items are. So when you read that two images are 90% similar, it most likely means that the cosine similarity of their compressed representation is equal to 0.90, or equivalently that they are 25 degrees apart.
Bringing in trigonometry might seem unnecessary when dealing with deep neural networks, but it comes rather naturally from the way networks calculate. To understand why, let’s have a look at a simple classifier network.
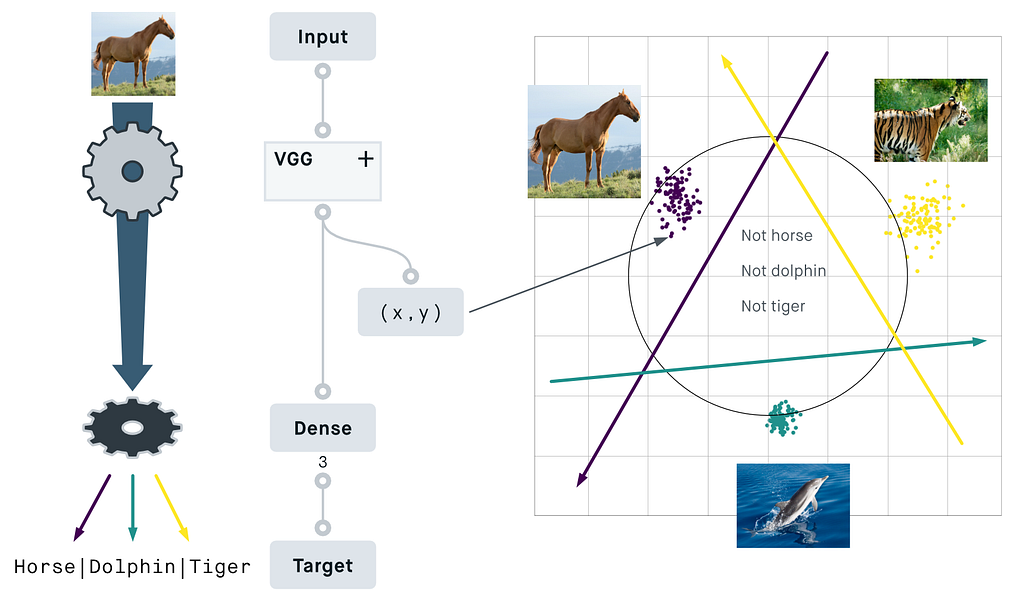
Here’s a classifier that I trained on 3 classes from animals with attributes 2. The encoder does the heavy part of image processing and compresses the input into coordinates in an N-dimensional space (here N=2).
The “decoder”, however, is reduced to a single layer and can merely act as a classifier, as opposed to reconstructing the entire input image. To decide if a point coming from the encoder belongs to a given category, it can only do a very simple thing: draw a line (or plane) in the N-dimensional space. If a point is on the right side of this line, it belongs to the category. If the point is on the wrong side, it doesn’t belong to the category from this line.
Both the encoder that calculates the coordinates and the classifier that draws the lines are trained together so that every image from a known category can be correctly classified. As we increase the number of known categories (especially if the categories are mutually exclusive), we can see that the points created by the encoder organize themselves in clusters spread around a circle.
As a result, the angle between two points becomes a natural way to compare them. The cosine similarity, which maps an angle between 0° and ±180° to a nice value between 1 and -1, offers an intuitive measure of similarity.
How is image similarity different from classification?
It’s true that image similarity is closely related to image classification, if only because it uses the same classifier networks as processing workhorse. However, there are a couple of points that make image similarity its own thing.
Image similarity considers many dimensions
In an image classification problem, we are only concerned with figuring out whether or not an image belongs to one (or possibly several) discrete categories, which means that a lot of information is discarded from the final output.
By using the representation of the data before the final classification layer, more aspects of the data can be used.
In the example below, I give a twist on the good old MNIST dataset. I trained a network to recognize handwritten digits, and surely enough the points get clustered according to their category — the digit between 0 and 9. However, I also defined 2 more dimensions that the network had to learn:
- The parity: whether a digit is even or odd
- The magnitude of the digit
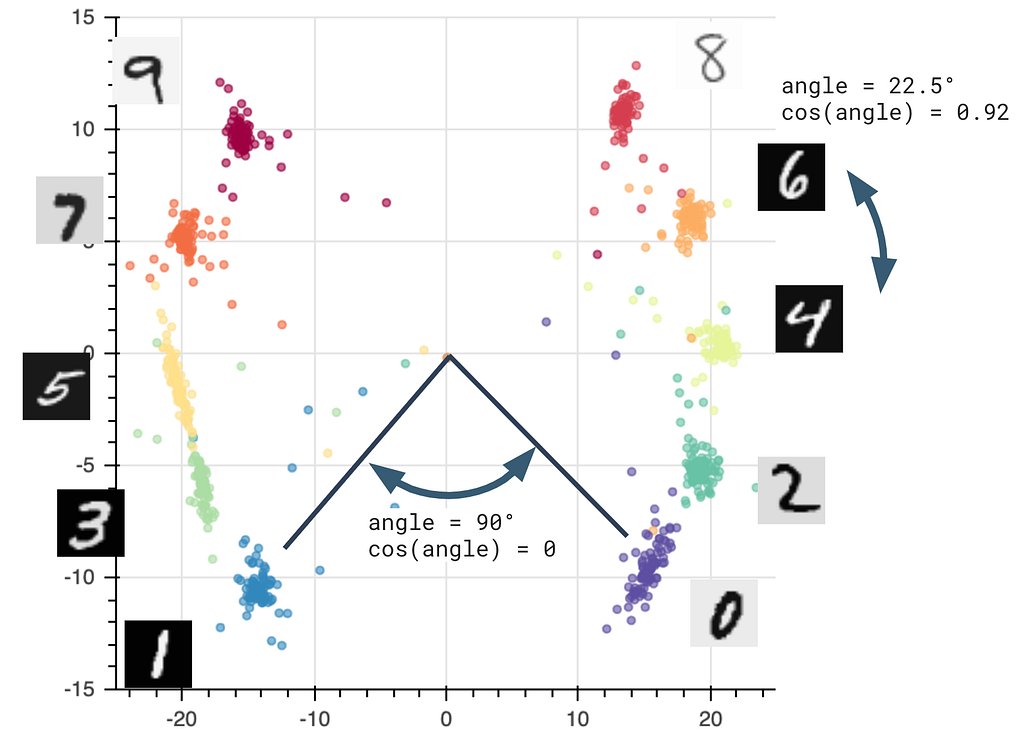
The cosine similarity between two images combines all these dimensions and returns a single value that is minimal for the same digit, slightly bigger for consecutive digits of same parity, and largest for digits of different parity.
Dimensions can be learned implicitly
If you trained a classifier network to recognize dolphins, tigers, and horses, these animals are the training domain and you shouldn’t count on classifying anything else. According to the image below, the network I trained previously would classify most images of zebras as being a tiger, which is simply wrong.
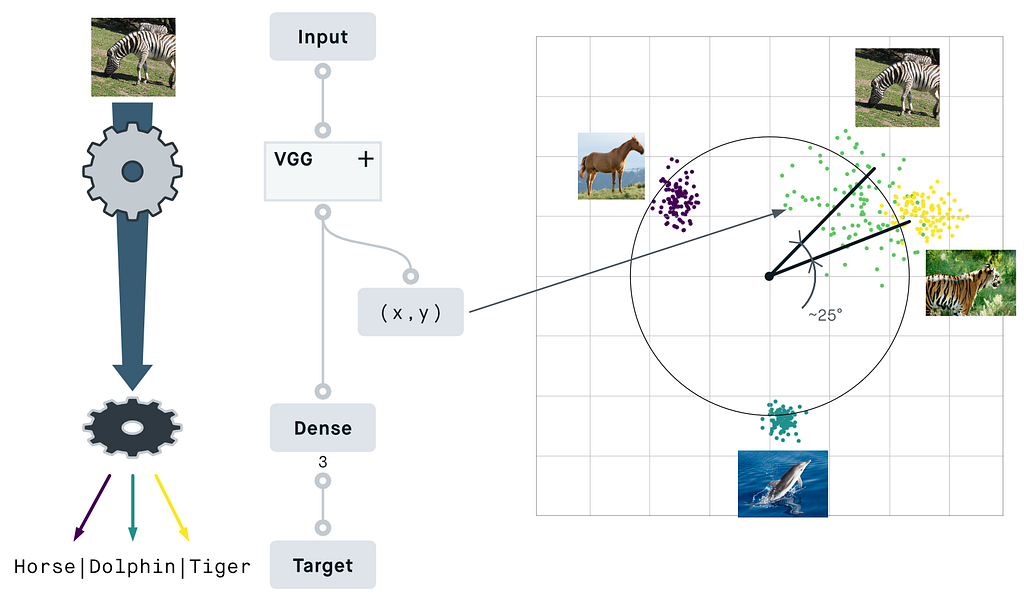
The cosine similarity combines many dimensions that are learned implicitly (presumably here, the striped pattern and the presence of legs or grass) into a fluid numeric value. As a result, you get from the same network that zebras look like something between horses and tigers, even though you didn’t train explicitly to recognize the class of zebras.
This particular network might find zebras a bit more similar to tigers than you would, but thankfully the network does so using deterministic operations that can be tuned.
Image similarity can be trained differently
If you’re willing to let the network learn implicit dimensions entirely on its own, you might not even need any labeled categories to train on.
Using labels only indicating if two images are similar or not, networks can be trained thanks to contrastive losses. This works if you know the similarity relationships between every pair of images in a dataset, or only between some of the pairs.
Such loss functions are rather different from the loss functions traditionally used to train classification networks. Indeed, their purpose is not to push an input image towards a fixed category but towards another image known to be similar.
Going further
Tutorials:
Meetup talk: Image similarity with deep learning — digital meetup with Solita & Romain Futrzynski/Peltarion
Literature:
- A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen et al., 2020
- Self-Supervised Similarity Learning for Digital Pathology, Jacob Gildenblat, Eldad Klaiman, 2020
- Supporting large-scale image recognition with out-of-domain samples, Christof Henkel, Philipp Singer, 2020
- Deep Face Recognition: A Survey, Mei Wang, Weihong Deng, 2020
- Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination, Zhirong Wu et al., 2018
Image Similarity With Deep Learning Explained was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts




")

