


Explainable AI: Thinking Like a Machine
Last Updated on March 18, 2024 by Editorial Team
Author(s): Joseph George Lewis
Originally published on Towards AI.
Everyone knows AI is experiencing an explosion of media coverage, research, and public focus. It is also garnering massive popularity in organizations and enterprises, with every corner of every business implementing LLMs, Stable Diffusion, and the next trendy AI product.
Alongside this, there is a second boom in XAI or Explainable AI. Explainable AI is focused on helping us poor, computationally inefficient humans understand how AI “thinks.” With applications in all the same places as plain old AI, XAI has a tangible role in promoting trust and transparency and enhancing user experience in data science and artificial intelligence.
This article builds on the work of the XAI community. First bringing together conflicting literature on what XAI is and some important definitions and distinctions. We will then explore some techniques for building glass-box or explainable models. The third section is focussed on how XAI can be implemented in enterprises and projects. Then the final section provides some notes around trustworthiness and the importance of user experience in AI.
The current state of explainability … explained
Any research on explainability will show that there is little by way of a concrete definition. For that reason we will first examine several other key terms that other use to define explainability, as well as looking at two distinct kinds of explainability.
Some of the common terms thrown around, alongside explainability, are:
- Understandability — A combination of transparency and interpretability.
- Transparency — Split into three key areas being; simulation, a user can simulate a task that a model is performing in their mind, decomposition the user can articulate the steps taken by a model, algorithmic transparency the user can explain how an input results in an output [1].
- Interpretability — Explaining the meaning of a model/model decisions to humans.
Ultimately these definitions end up being almost circular! Despite this, researchers use them to describe explainability, with some describing Explainable AI or XAI as encompassing these three and adding that with comprehensibility [1]. The main challenge with this type of approach is users need to understand, understandability then interpret interpretability and so on. In addition to that, these different ways of saying “I understand what my model is doing” pollute the waters of actual insightful understanding. For example, which of these definitions fit a model like a decision tree which is explainable by design compared to a neural network using SHAP values to explain it’s predictions? Would one be transparent but not understandable or explainable but not interpretable?
This is where alternative definitions that have a strong voice in the community of XAI come in.
This research focuses instead on the difference between black box and glass box methods [2] and uses these to better define interpretability and explainability in particular. Note that for these points the definition for interpretability slightly changes:
- Interpretability — The ability to understand how a decision is being made.
- Explainability — The ability to understand what data is used to make a decision.
Whilst these may sound very similar, they are not. A good example of this comes from [4], where a salience map can be used to show you which part of an image resulted in an image gaining a certain classification (explainability). A model that shows you which parts of an image closely resemble reference images of a certain class and uses that to actually make its decision and explain it (interpretability).
The paper referenced in [4] is explained in an accessible tutorial from Professor Cynthia Rudin, a leading author in interpretability here [5]
In examples like these, it is not overly wrong to think of interpretable models as mimicking human-like processes for decision-making. This makes them inherently easier to understand!
This is perhaps more favorable as it leaves us with two key areas for explaining our work, making models interpretable or explainable:
- Interpretable, glass box methods: These are models built with interpretability in mind. The modeling process is based on making decisions in a way that can be interpreted by humans.
- Explainable, black box methods: These models are built to perform with explainability almost as an afterthought, most commonly using post-hoc explanation methods.
An important distinction to make here is that whilst Deep Neural Networks are considered black box models, researchers advocate for them to instead be built as interpretable models [3]. This is where the distinction comes in using these definitions interpretable models are built with interpretability in mind, explainable models are models that have been explained after the work is done.
This raises an important question. If glass box models are made to be interpreted and black box models are made to perform, surely black box methods are better at performing? This is not uncommon to the literature on the topic either, with the diagram below being a prominent feature of DARPA research into XAI [6]:

There are documented issues with this diagram; of course, it is meant to assist in understanding, over actually representing information, but it is potentially misleading. The idea that good explanations are sacrificed for good accuracy is actively challenged by the community who promote interpretability at a foundational level in building models [2, 3, 4]. Some comparisons of black box and interpretable models are explained below:
- Concept bottleneck models (interpretable) achieve competitive accuracy with standard approaches [7] in predicting severity (ordinal) of knee osteoarthritis in X-ray images (RMSE of 0.67–68 for CNN, 0.52–54 for interpretable AI). Noting that the goal is to minimize RMSE.
- Disentangled GNN outperforms multiple black box competitors in state-of-the art session-based recommendation systems [8].
- Case based reasoning model (0.84 accuracy) outperforms black box methods (0.82 accuracy) in classifying birds using the CUB200 dataset [5]. Noting that the goal is to maximise accuracy.
Interpretable models have the advantage of being very well tailored to a domain and leveraging that to be a real co-pilot in decision-making. Let’s explore an example of how interpretable AI can be a good partner for assisting human decision-making.
Imagine you are a judge in a singing contest, you have two assistant judges one is an explainable AI (EAI) and the other is a interpretable AI (IAI). Both take into account the whole performance. The first performer comes on stage and performs with amazing stage presence. Here is how the AIs score them:
- EAI: 6 out of ten, and it displays a heatmap of where the performers went on stage and the times at which they performed well.
- IAI: 5 out of ten, and it tells you that they kept to the rhythm which earned them 3 points and that they kept to the pitch correctly which earned them 2 points.
Now for the IAI, you have an interpretation of how the decision was made exactly. You know what has been taken into account. So if you think this is fair you can accept or you can consider information that you, as a specialist judge, have. For example, that amazing stage presence should be taken into account, and more points should be awarded! So you could score them a 7 with assistance from IAI on the things it found to be important.
Compare this to the EAI. You know that they took into account where the singer went on stage and which bits of the sound it used to make it’s decision. What you don’t know is did this take into account stage presence? If so, how? If you use your specialist knowledge to add points here, you could be double counting with the EAI! You also wouldn’t be able to give good feedback to the up and coming singer on your stage!
In the above example, we didn’t go into detail on how the models were trained to be EAI and IAI approaches. Of course, that is covered in more detail [5] and will be discussed more below.
So, should I consider explainability or interpretability, or are they one and the same?
This is the question you may now be asking yourself, and it’s a really good one. The honest answer is that you should be considering both. In a perfect world, all models would be interpretable and hence explainable. However, interpretable models lend themselves much more easily to some domains than others.
Interpretable model examples
- Logical models — Models like decision trees, decision lists, and decision sets that provide built-in explanations and share those with users are very well covered in Challenge #1 of this work [2].
- Sparse scoring systems — Examples like the one above build models that learn how to score data effectively and present those as rules to the user, as well as actually performing a classification. It has been shown to have a competitive error with Random Forests, Support Vector Machines, and other models on a range of data sets [9].
- Domain-specific IAI models — A range of different approaches seek to make AI more explainable in one domain at a time. For example, the concept bottleneck model seeks to teach an AI model different concepts and uses those to find predictions for classification/regression problems. For example, it could seek to first teach “Has wings” then “Has beak”, “Has whiskers” and so on to then use these predictions to classify cats or birds [7].
- Disentangled Neural Networks — Networks designed to be inherently explainable for example DisenGNN which uses Graph Neural Network approaches to find factors that link nodes in a network and explain classifications/recommendations [8].
However there are many fields where interpretable AI is not yet possible. This doesn’t mean you cannot find an appropriate approach using some of the domain specific techniques above. In some cases, though explainability may be a better solution, for example, in fields like reinforcement learning and LLMs where IAI models have not yet been able to replicate the accuracy of black box methods [2].
Explainability techniques
- SHAP Values: Implemented to explain local predictions made by a model, they take every feature and calculate how a specific observation resulted in a certain prediction [10].
- Global Surrogate Model: This approach to explainability involves training a glass box model based on predictions made by a black box model. For example, training a linear regression on predictions from a neural network could tell you which features are correlated with certain predictions. This sounds good, but further techniques should be explored, as if your model is non-linear, these importance values/relationships may not be correct.
- Attention maps: Attention maps describe what parts of an image or observation are used by a model to make a prediction. A particularly interesting application of attention maps in generating explanations using similar images is here [11]. This paper almost bridges the gap between explainability and interpretability in it’s comparison to like images.
- Counterfactuals: Counterfactuals seek to explain decisions made by AI by asking “what if?” style questions. These have been shown to increase user engagement with AI [12] and can answer interesting questions as to what a model would do in a certain scenario. However, it does not explain why a model would do what it would, so maybe more useful as a debugging technique for some models.
Risks of Explainability
An important note when we consider explainability over interpretability is that most explainability techniques are ways of explaining what we think AI is doing. This distinction can lead to misleading results.
A good example of where explainable AI can be misleading is the COMPAS model for recidivism (the likeliness of prisoners to re-offend). There are a number of well-documented problems with models like these, but the issues with explainability, in particular, are expertly documented in this video conference [13]. Incorrect assumptions are drawn about how a model works based on explainers when controlled analysis shows this is unlikely to be the case. This is particularly a problem in the COMPAS modeling process due to the sensitivity of the problem and the confounding/proxy variables used.
A path forward for XAI
Now that we have an understanding of where XAI is now, I go on to propose a way forward for XAI in future. Despite the confusion and clashes in some of the literature, we can identify two key problems:
- AI is being implemented in organizations globally with models that cannot be accurately explained or understood by all users
- Some AI models and techniques are not yet built as “glass-boxes” so we have to make our explanations based on guesses
For this reason, a sensible solution could be a decision tree for humans! Let’s look at what that might be:
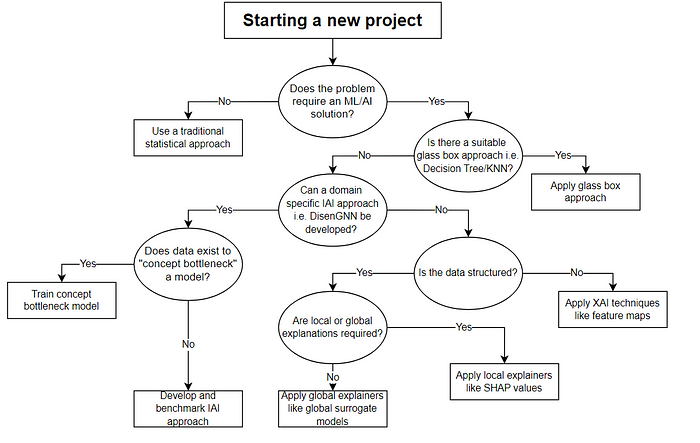
The above diagram goes some way in simplifying the XAI space for organizations and those starting out in their projects. First of all, we need to ask as the AI hype builds does this problem require an AI solution? Can a traditional statistical approach, automation approach or anything else be employed first?
Next we ask ourselves is there a simpler or inherently interpretable model that can be built? If so, let’s use it! If not, let’s see if we can develop our approach to be interpretable first. Seeking interpretability could send us down a path of developing our own domain specific IAI model like DisenGNN, or training our own concept bottleneck model if we have data to do so. It is important at this stage that we consider performance as well so we benchmark against the black box approaches.
Finally, if we cannot develop or employ IAI, we review explainability. Unstructured data may come in the form of heat maps. For structured data, we could use SHAP values for local and surrogate models for global explanations. Notice that wherever we end up, we are still building some form of user understanding with our models. That is because XAI approaches are perfect for introducing AI solutions to users in a trustworthy and transparent way.
A final note on trustworthiness
The technique used to explain a model or to make a model interpretable are ultimately paths toward the same end goal. The methods, benefits and challenges to building XAI are covered above, but before closing, it is important to note the role of trustworthiness. More specifically, how users trust models.
This is covered expertly in this talk from Q. Vera Liao [14], which focuses on AI user experience (UX). A key message from this video seminar is that users tend to trust models more if explanations are provided. Therefore, in the case of bad/unsure models, users actually end up trusting them more if an explanation is provided. This lends even more responsibility to those building XAI models and shows that even when AI is explainable, it can still be wrong and can still have real risks attached to over-reliance on AI decisions.
The importance of work like this exploring user experience of AI models and, more specifically, XAI models cannot be understated. Data scientists, analysts, and academics letting models loose in the real world have a duty to not only explain what their model does but also to explain that to those it affects. Human-centric and UX focused approaches, like those explored here [14], are crucial in building an inclusive approach to XAI in organizations and for the world community.
Thank you for reading this piece. I hope it has brought your attention to some of the key areas of XAI research — whether that’s the interpretable model space for glass box models, the explainability techniques for black box models or the trustworthiness we can foster by learning more about AI UX.
References
[1] Arietta et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion. https://doi.org/10.1016/j.inffus.2019.12.012
[2] Rudin et al. 2021. Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges. arXiv. 2103.11251.pdf (arxiv.org)
[3] Rudin. 2019. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. arXiv. 1811.10154.pdf (arxiv.org)
[4] Chen et al. 2019. This looks like that: Deep learning for Interpretable Image Recognition. NeurIPS Proceedings. 2103.11251.pdf (arxiv.org)
[5] Rudin. 2022. Stop Explaining Black Box Machine Learning Models – Cynthia Rudin. Caltech. (9) Stop Explaining Black Box Machine Learning Models — Cynthia Rudin — YouTube
[6] Defense Advanced Research Projects Agency (DARPA). 2019. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. https://doi.org/10.1609/aimag.v40i2.2850
[7] Koh et al. 2020. Concept Bottleneck Models. arXiv. [2007.04612] Concept Bottleneck Models (arxiv.org)
[8] Li et al. 2020. Disentangled Graph Neural Networks for Session-based Recommendation. arXiv. 2201.03482.pdf (arxiv.org)
[9] Ustun, Traca & Rudin. 2013. Supersparse Linear Integer Models for Predictive Scoring Systems. Association for the Advancement of Artificial Intelligence. Supersparse Linear Integer Models for Predictive Scoring Systems — AAAI
[10] datacamp. 2023. An Introduction to SHAP Values and Machine Learning Interpretability. An Introduction to SHAP Values and Machine Learning Interpretability U+007C DataCamp
[11] Achtibat et al. 2023. From attribution maps to human-understandable explanations through Concept Relevance Propagation. Nature. https://doi.org/10.1038/s42256-023-00711-8
[12] Saeed & Omlin. 2023. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowledge-Based Systems. https://doi.org/10.1016/j.knosys.2023.110273
[13] Rudin. 2021. Nobel Conference — Rudin. Nobel Conference. (9) Nobel Conference — Rudin — YouTube
[14] Liao. 2023. Stanford Seminar — Human-Centered Explainable AI: From Algorithms to User Experiences. Stanford Online. (9) Stanford Seminar — Human-Centered Explainable AI: From Algorithms to User Experiences — YouTube
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")