



Understanding the Mechanics of Neural Machine Translation
Author(s): Saif Ali Kheraj
Originally published on Towards AI.
As large language models become more prevalent, it is essential that we study and concentrate on attention models, which play an essential role in both Transformer and language models. First, let us get a better understanding of the Sequence to Sequence Encoder Decoder Network. After that, we will proceed to the most important “Attention Model” and examine it in greater detail.
Traditional Sequence to Sequence: Encoder-Decoder Network
Let us see this particular translation and let us see how it is represented in the traditional seq-to-seq model.
Traditional sequence-to-sequence models face difficulties due to their fixed context window. In the classic sequence-to-sequence approach, the encoder’s last hidden state vector is extremely critical. That vector captures the complete input representation, which is then used during the decoding process. Let’s look at each component of the diagram above:

I have not shown you all of the encoder cells in the diagram above, but the general idea is that we are only using the encoder’s last hidden state and passing it to the decoder to process the translation of this English sentence. As shown in the diagram above, the Encoder’s final hidden state is intended to encapsulate all of the information from the English input sequence in a fixed-length vector. This final hidden state can then be processed further to generate an output sequence in the decoding process. The issue, and a major problem, is that it does not scale well. All input sequences must be compressed into a single vector, which results in information loss, particularly for longer sequences. Longer sequences lead to decreased performance.
More advanced architectures, such as the Transformer model (used in BERT, GPT, and so on), do not rely on a single hidden state vector to transfer information between the encoder and the decoder. Instead, they use mechanisms such as attention to allow each component of the decoder to access the entire encoder output, thus addressing the context limitation issue.
In this post, we will go over basic concepts of attention mechanisms, such as alignment scores and attention weights, which are used by decoders to accurately predict the next word by focusing on the right hidden vector of the input sequence in the encoder. We will cover the fundamentals of scaled dot products, teacher forcing, and pre-attention decoders, as well as their connections.
Is using all the hidden states a solution?
One solution to using only the last hidden state is to pass all of the hidden states to the decoder and perform some sort of point-wise addition, but this is another problem because the network still does not know which word in the encoder to focus on more.

Attention is all you need!!
Alignment Scores
The alignment score calculates the similarity between each encoder’s hidden state and each decoder’s hidden state. Let me give you an example. In this example, the source sentence is “Its time for coffee” and the target sentence is “C’est l’heure du café” in French. Let’s call h1 (hidden state) “Its”, h2 “time”, h3 “for”, and h4 “coffee”.
We will calculate alignment scores step by step for each word in the sentence. When translating or predicting a specific word, the decoder examines all of the encoder’s hidden states and attempts to determine which English words are most relevant to produce the first word in French, which is C’est.

The scores in green are essentially normalized alignment scores after applying softmax. This is what the attention is all about. For the decoder to predict the first word “C’est”, it must now decide which English word to focus on more. As we can see in this example, the first word should be more focused on “Its” (probability 0.8). These probabilities are referred to as attention weights. These attention weights are for translating the first word.
Attention weights are denoted as αij, with i representing the decoder (output word) and j representing the encoder (input word). The figure above shows attention weights α1j.
Alignment scores are essentially a scoring system used by the model to determine which words in the input sentence should be prioritized when generating each word in the output sentence. The attention mechanism ensures that the translation is contextually appropriate, even when the sentence structure varies between languages.
Now that you have understood a bit of intuition, let us understand how attention weights are calculated using the attention mechanism.
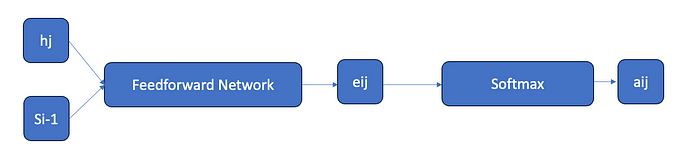
The above is a very simple architecture of the attention mechanism. Each encoder’s hidden state (hj) represents the input words in an English sentence (h1, h2, h3, and h4). Si-1 is the decoder’s hidden state. Both are fed into feedforward neural networks before being processed by softmax for weight normalization. To summarize, the softmax operation converts alignment scores into weights that quantify the importance of each encoder state to the decoder’s current state. αij is the attention weight for the jth input word’s influence on the ith output word, while hj is the jth encoder hidden state. These weights are used to generate a context vector for the decoder.
The context vector for the current output word is computed by multiplying each encoder hidden state (hj) by its corresponding attention weight (αij). ci represents the context vector for the ith word in the output sequence.

Now that we have the context vector, let’s call the first step c1 and the initial decoder hidden state s0. We will combine these two using a concatenation function, followed by tanh or another non-linear activation function. This combination provides a rich signal for the formation of the first word in the target language.
What is our learning here?
When translating a sentence from English to French using machine translation, the model does not always translate each word in the correct order. Some words in French may correspond to words that appeared earlier or later in an English sentence. Attention allows the model to concentrate on the relevant English words.
Challenges of this Model

The above one is difficult to implement, so we introduce a new Pre Attention Decoder and then apply attention, but first, let us look at how the scaled dot product works. We will first understand the fundamentals of Keys, Query, and Value, as well as Teacher Forcing in Seq to Seq Learning.
Scaled Dot Product
This is the core component of transformers, and we are simplifying the alignment scores section by using simple matrix multiplication.

In this stage, we start with two matrices: Q (Query) and K (Key). Let’s say we have an English sentence as our source and a French sentence as our target. Assume we have an English sentence with 13 words and a French sentence with 14 words.
The Source and Target matrices have dimensions of 13*dₖ and 14*dₖ, respectively. K and Q contain 13 and 14 English words, respectively, represented by dₖ vectors. Let’s say dₖ = 300.
Let us understand this using a very simple example and also see matrix operations here:
Keys: We first generate embeddings of English sentences with 13 words → 300 dimensions → 13 x 300
Queries: We then generate embeddings of target French sentence → 14 x 300
Take dot product: 14 x 300. 300 x 13 = 14 x 13 alignment matrix
The dot product calculates the similarity between the query and each key.
The scores are then reduced by dividing by the square root of the key size. This scaling helps to stabilize the gradients during training by preventing the dot products from growing too large.
Softmax
What we need to know is how much weight or attention should be placed on English words for each French word.
When implementing, it is crucial to apply the softmax across columns (axis=1) so that all rows add up to one. This will allow us to determine how much emphasis should be given to English words for each French word.
Weights of 14 x 13

Then we multiply these weights by Value (English embedding 13×300) to get a matrix (14 x 300).
This 300-dimensional representation of each context vector in the output matrix emphasizes the most important parts of each French word while also including information from the English sentence. The model would use the combined context to provide translations for every French word.
So it's just 2 matrix multiplication and a SoftMax. Now let’s move on to the next crucial section: Teacher forcing.
Teacher Forcing and Training
Before joining all the pieces together, let us understand the concept of teacher forcing.
Standard Training
In the standard training, the model uses its own predictions to generate the next token in the output or target sequence. If the model predicts an incorrect token at any step, it may use that incorrect token to predict the next one, potentially compounding errors.
Teacher Forcing:
In teacher forcing, the true previous token from the training data is provided as input and used to generate the next token rather than the model’s predictions. Because the correct token is always used as the input for the subsequent prediction, any errors made by the model are immediately corrected in the next step. Using this method makes it easier to learn correct sequences because it ensures that the model is always conditioned on the correct sequence of tokens up to a specific point.
Neural Machine Translation Model
Let us now combine all the pieces together

So, as we’ve already discussed, Figure 6 has some issues, and implementing such a thing is difficult. So, before applying the Attention Mechanism, we introduce the Pre Attention Decoder.
Now that we have understood important concepts. Let us join all the pieces together.
Encoder: As shown in the diagram, we start with an input sequence (which can be an English sentence) that will be essentially passed through an embedding layer, followed by an LSTM (Long Short-Term Memory) layer. The encoder generates a sequence of hidden states based on the input. What I’m explaining here is the encoder’s internal workings. Encoder returns Key and Value.
Pre-attention Decoder: The pre-attention decoder takes the target sequence, shifts it right (to align the prediction during training), and then passes it through an embedding layer and an LSTM. This part creates the decoder’s initial hidden state and generates queries for the attention mechanism.
Attention Mechanism: It uses the queries from the pre-attention decoder and keys and values from the encoder to compute attention weights. These weights produce context vectors, which capture relevant information from the input for each decoding step.
Decoder: The context vectors are then used by another LSTM layer in the decoder to help generate the next token in the sequence. We will have a dense layer followed by a softmax operation to produce a probability distribution over the possible tokens for each position in the output sequence.
Output: The decoder predicts the next token in the target sequence based on the log probabilities and continues this process iteratively to generate the entire translated sequence.
Please keep in mind that the diagram does not include internal work.
Conclusion:
Let’s summarize everything. In traditional seq to seq learning, the encoder takes a sequence as input and compresses it into a fixed-size “context vector”, which is then used by the decoder to generate an output sequence. Order can also be mixed up in different languages. In French, for example, adjectives appear later. To address this, the attention mechanism was implemented. It enables the decoder to focus on different aspects of the encoder’s output while generating the sequence, resulting in improved performance, particularly for longer sequences. The intuition is that every hidden state in the encoder influences every input to the decoder via attention weights. What we saw above is a very basic version of attention, but it is critical before progressing to more complex levels of architecture.
Reference
[1] https://arxiv.org/pdf/1409.0473.pdf
[2] https://arxiv.org/abs/1706.03762v7
[3] https://pianalytix.com/implementation-of-neural-machine-translation-using-attentions/
[4] https://www.deeplearning.ai/resources/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

