


Revolutionizing AI with DeepSeekMoE: Fine-grained Expert and Shared Expert isolation 🧞♂️
Author(s): JAIGANESAN
Originally published on Towards AI.
Revolutionizing AI with DeepSeekMoE: Fine-grained Expert and Shared Expert isolation 🧞♂️


Towards AI
Listen
Share

In this article, we’re going to dive into the world of DeepSeek’s MoE architecture and explore how it differs from Mistral MoE. We’ll also discuss the problem it addresses in the typical MoE architecture and how it solves that problem.
If you already have a solid understanding of LLMs and MoE, feel free to skip the below recommendations and continue reading this article 😊.
But If you’re new to this topic, I highly recommend checking out my previous articles on Large Language Models (LLMs) and Mixture of Experts (MoE). I’ve written a series of articles to help you understand these complex concepts.
If you’re not familiar with LLMs and MoE, start with my first article, Large Language Models: In and Out, where I explain the basic architecture of LLMs and how they work. Then, move on to Breaking Down Mistral 7B, which breaks down the Mistral architecture and its components. Finally, read Mixture of Experts and Mistral’s Sparse Mixture of Experts, which delves into the world of MoE and Sparse MoE. It will be a Visual Walkthrough in LLM and Mistral architecture from embedding to prediction.
Large Language Model (LLM)🤖: In and Out
Delving into the Architecture of LLM: Unraveling the Mechanics Behind Large Language Models like GPT, LLAMA, etc.
pub.towardsai.net
Breaking down Mistral 7B ⚡🍨
Exploring Mistral’s Rotary positional Embedding, Sliding Window Attention, KV Cache with rolling buffer, and…
pub.towardsai.net
The architecture of Mistral’s Sparse Mixture of Experts (S〽️⭕E)
Exploring Feed Forward Networks, Gating Mechanism, Mixture of Experts (MoE), and Sparse Mixture of Experts (SMoE).
pub.towardsai.net
In this article, we’ll be exploring the following topics in-depth:
⚡What problems does DeepSeek’s MoE address, and what solutions does it offer?
⚡How does DeepSeek’s expert architecture differ from Mistral’s expert architecture?
⚡Fine-grained expert architecture
⚡Shared expert isolation architecture
Let’s dive in and get started!
1. What problems does DeepSeek’s MoE address, and what solutions does it offer? 🤠
Despite the promising results of the existing Mixture of Experts (MoE) architecture, there are two major limitations that were addressed by DeepSeek researchers. These limitations are knowledge hybridity and knowledge redundancy.
New solutions bring new kinds of problems to solve.
So, what is knowledge hybridity in MoE? In simple terms, it’s the integration and blending of different forms, sources, and types of knowledge. This means combining insights from various fields or domains to solve common problems.
The problem with knowledge hybridity in MoE is that existing architectures often have a limited number of experts (for example, 8, 12, or 16, and Mistral has only 8 experts). As a result, the tokens assigned to a specific expert will likely cover diverse knowledge areas. This means that each designated expert will have to assemble vastly different types of knowledge in its parameters, which can be challenging to utilize simultaneously. In other words, a single expert will have to handle different background knowledge, which can be difficult.
The root of the issue lies in the training data itself, which often contains a mix of knowledge from different backgrounds. This forces each expert to specialize in different tasks, specializing in multiple areas at once. However, this can be inefficient and sometimes even inadequate. For example, solving a single problem might require different background data, but with only a limited number of activated experts, it may not be possible to give good predictions or solve the problem.
Another issue with the existing Mixture of Experts (MoE) systems is knowledge redundancy. This occurs when multiple experts learn the same things and store them in their parameters.
For instance, tokens assigned to different experts may require a common piece of knowledge. As a result, these experts may end up learning the same knowledge and storing it in their parameters, and this is redundancy. This means that the same information is being duplicated across multiple experts, which is Parameter waste and inefficient.
To solve the issues of knowledge hybridity and redundancy, DeepSeek proposes two innovative solutions: Fine-Grained Expert and Shared Expert Isolation. But Before we dive into these methods we should understand what changes DeepSeek Researchers made and proposed in Expert (Feed Forward Architecture) How it differs from typical Expert architecture and how it lays the groundwork for these new solutions.
2. How does DeepSeek’s expert architecture differ from Mistral’s expert architecture? 🔎
DeepSeek didn’t use any magic to solve the problems of knowledge hybridity and redundancy. Instead, they simply changed their perspective on the expert architecture. To understand how? let’s take a closer look at the Mistral expert architecture.
Note: To illustrate the Fine-grained expert and shared expert isolation I have compared it with Mistral MoE architecture.
class FeedForward(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.w1 = nn.Linear(args.dim, args.hidden_dim, bias=False)
self.w2 = nn.Linear(args.hidden_dim, args.dim, bias=False)
self.w3 = nn.Linear(args.dim, args.hidden_dim, bias=False)
def forward(self, x) -> torch.Tensor:
return self.w2(nn.functional.silu(self.w1(x)) * self.w3(x))
# SwiGLU = nn.functional.silu(self.w1(x)) * self.w3(x)
# self.w3(x) = Acts as Gating Mechanism
# Swish Activation(Beta=1) = nn.functional.silu(self.w1(x))
# By doing this we Introduce Non-linearity in element wise and Preserve the high magnitude of the vector.
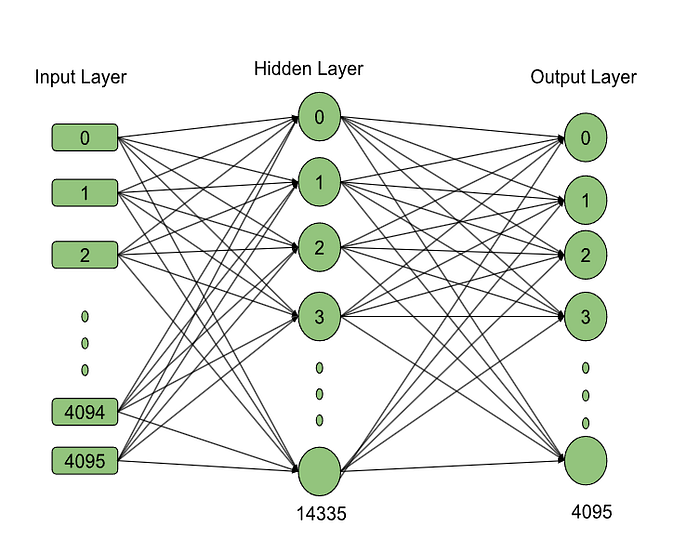
The expert code in Mistral is the SwiGLU FFN architecture, with a hidden layer size of 14,336. If we break down the architecture, as shown in Image 1 and the code snippet above, we can calculate the number of parameters in each expert.
Expert’s Parameter Count : (No.of hidden Layer operation x Hidden layer weight matrix + Output layer weight matrix )
= 2 x (14336 x 4096)+ (4096 x 14336)
= 117440512 + 58720256 = 17,61,60,768 ~ 17.6 Crore Parameter.
If we calculate the Parameters in One decoder’s MoE layer = No. of .experts X parameters in One expert = 8 x 17,61,60,768 = 1,40,92,86,144 ~ 1.4 billion Parameters in MoE layer.
Here’s the interesting part: what if we split each expert into two, with the same number of parameters? This would give each expert around 8.8 crore parameters. To do this, we simply divide the hidden layer size by 2, creating two experts with the same number of parameters.
I will explain it with Parameter count after the splitting expert:
Expert’s (Fine-grained expert 😉 )Parameter Count : (No.of hidden layer operation x Hidden layer weight matrix + Output layer weight matrix )
= 2 x (7168 x 4096)+ (4096 x 7168)
= 8,80,80,384 ~ 8.8 Crore Parameters.
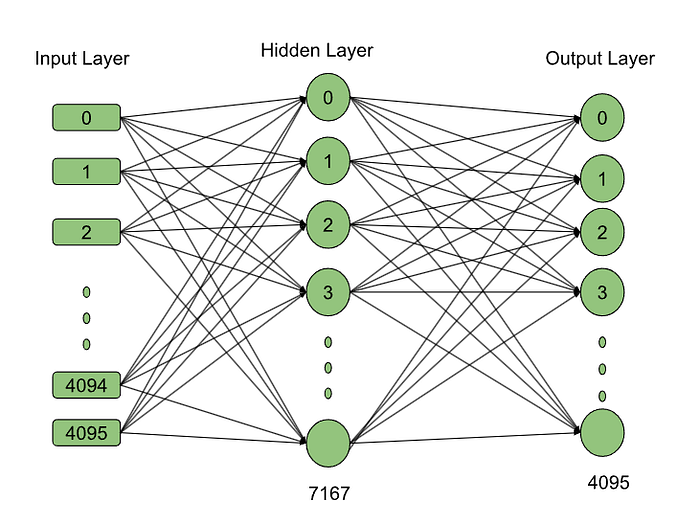
What we did is the Existing MoE’s Expert’s hidden size is 14336, after division, the hidden layer size of experts is 7168. DeepSeekMoE calls these new experts fine-grained experts. By splitting the existing experts, they’ve changed the game. But how does this solve the problems of knowledge hybridity and redundancy? We’ll explore that next.
3. Fine-Grained Expert Segmentation 🦸♂️🦸♂️🦸♂️🦸♂️…🦸♂️
As shown in the illustration, researchers have divided an expert into multiple, finer-grained experts without changing the number of parameters. This is done by splitting the intermediate hidden dimension of the feed-forward network (FFN).
The beauty of this approach is that it doesn’t increase the computational load but allows more experts to be activated. This, in turn, enables a more flexible and adaptable combination of activated experts. As a result of this, diverse knowledge can be broken down more precisely into different experts, and at the same time, each expert retains a higher level of specialization. Combining More Activated experts gives more flexibility and more accurate responses.
For Example, some tokens play important roles in different knowledge backgrounds. So Multiple experts will specialize in their specialization when the expert has access to the token. Otherwise limited number of experts have to cover the knowledge about tokens, which have different knowledge backgrounds.
The Tokens “If, while, function” can be used in Code, Reasoning, common knowledge, and even mathematics. Because code, Reasoning and mathematics are closely connected.

As shown in Image 3, we know the Mistral architecture uses 8(N) experts, whereas this new approach uses 16 (2N) experts, doubling the number of experts. However, the number of parameters remains the same.
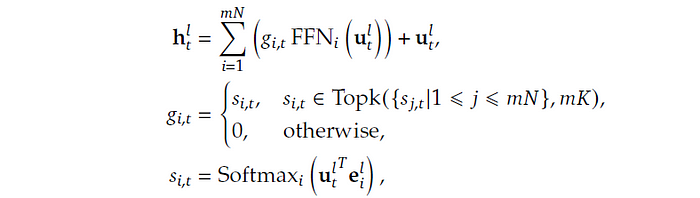
Let’s take a closer look at the mathematical representation of fine-grained expert segmentation, as shown in Image 4. Here, u_t represents the input tensor. For example, if we have 9 input tokens, each with a model dimension of 4096, our input tensor would be represented as u_t (9, 4096).
The variable m plays a crucial role in this equation. It determines how many fine-grained experts we can split one expert into. In other words, mN represents the total number of fine-grained experts, while mK represents the top mk experts that are selected for each token.
The token-to-expert affinity is denoted by s_i,t, and g_i,t is sparse, meaning that only mK out of mN values are non-zero. Finally, h_t represents the output of the hidden state.
In the Mistral architecture, the top 2 experts are selected for each token, whereas in this new approach, the top 4 experts are chosen. This difference is significant because existing architectures can only utilize the knowledge of a token through the top 2 experts, limiting their ability to solve a particular problem or generate a sequence, otherwise, the selected experts have to specialize more about the token which may cost accuracy. In contrast, with more fine-grained experts, this new approach enables a more accurate and targeted knowledge acquisition.
In Existing Mixture of Experts (MoE) architectures, each token is routed to the top 2 experts out of a total of 8 experts. This means there are only 20 possible combinations of experts that a token can be routed to.
In contrast, Fine-Grained MoE architectures have a significant advantage when it comes to combination flexibility. With 16 experts and each token being routed to 4 experts, there are 1820 possible combinations. This increased flexibility leads to more accurate results, as the model can explore a wider range of expert combinations to find the best fit for each token.
This advantage in combination with flexibility is a key benefit of Fine-Grained MoE architectures, allowing them to give better results than existing MoE models.
4. Shared Expert Isolation 🦈
The Share Expert Isolation approach involves, activating a certain number of fine-grained experts for all tokens. This means that all tokens are passed through these experts, which are designed to capture and consolidate common knowledge across various concepts.
For example, when training data have a wide range of concepts and knowledge backgrounds, such as history, politics, mathematics, coding, reasoning, literature, and more, a common thread runs through them all — they are all written in English. The shared expert learns to write good content with proper grammar and flow in English, enabling it to generate a coherent sequence of content.
Meanwhile, other experts are activated based on the token, contributing their specialized knowledge in areas like math, reasoning, or coding. The combination of the shared expert and these fine-grained experts ultimately produces a well-structured sequence.

By compressing common knowledge into shared experts, the redundancy among other experts is significantly reduced. Previously, each expert had to learn how to construct English words in a sequence, meaning they have the same parameters.
Now, this task is handled by the shared expert, freeing up the other experts to focus on their specific areas of specialization. As a result, fine-grained experts can specialize more intensely in their respective areas.
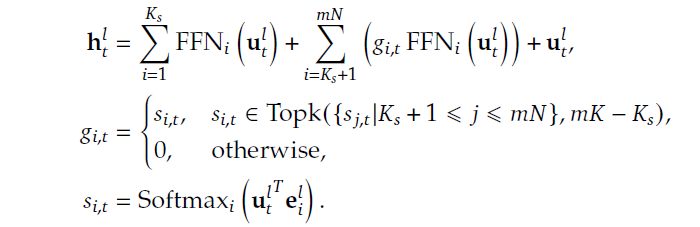
Let’s compare the mathematical representations of Fine-Grained MoE (Image 4) and Shared Expert Isolation (Image 6).
One key difference between the two is the introduction of K_s, which represents the number of shared experts in Image 6. This is in contrast to Image 4, which doesn’t have shared experts.
Another important difference is the token-to-expert affinity, denoted by s_i,t. In Image 4, this affinity is calculated based on the number of fine-grained experts (mN, mK). However, in Image 6, the affinity is calculated based on the number of shared isolation experts (mN, mk-K_s). This means that the way tokens are assigned to experts changes depending on the number of shared experts.
These architectural innovations in DeepSeekMoE create opportunities to train a highly parameter-efficient MoE language model, where each expert is highly specialized and can contribute its unique expertise to generate accurate and informative responses.
In conclusion, we’ve seen the evolution of the typical feed-forward network over time in this series of articles. From its Feed Forward Networks, it transformed into a Mixture of Experts, then into a sparse MoE, followed by fine-grained MoE, and finally, into Shared MoE. Each new approach has paved the way for other innovative solutions to tackle real-world problems in AI.
On a philosophical note 📝, I’d like to touch upon human nature 🤷♂️🤷♀️. Our inherent desire for more 🏃🏽, our wanting more attitude, drives innovation. Humans have an innate tendency to identify problems and strive to solve them, much like what’s happening in the AI world. As time progresses, we can expect researchers to uncover more problems and develop solutions to address them. This relentless pursuit of improvement is what propels us forward, and it’s exciting to think about what the future holds for AI.
Thanks for reading this article 🤩. If you found my article useful 👍, give it a clap👏😉! Feel free to follow for more insights.
Let’s keep the conversation going! Feel free to connect with me on LinkedIn www.linkedin.com/in/jaiganesan-n/ 🌏❤️
and join me on this exciting journey of exploring AI innovations and their potential to shape our world.
References:
[1] Damai Dai, Chengqi Deng, Chenggang Zhao, R.X. Xu, Huazuo Gao, DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models(2024), Research paper (arxiv)
[2] DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(2024), Research paper(arxiv)
[3] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot. Mixtral of Experts (2024). Research paper (Arxiv).
[4] William Fedus, Jeff Dean, Barret Zoph. A Review of Sparse Expert models in deep learning (2022). Research paper (Arxiv).
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Attention is all you Need (2017). Research Paper (Arxiv)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





