


Inside Zephyr-7B: HuggingFace’s Hyper-Optimized LLM that Continues to Outperform Larger Models
Last Updated on November 11, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
ZEPHYR-7B is one of the new generation large language models(LLMs) that have been incredibly well received by the AI community. Created by Hugging Face, the model is effectively a fine-tuned version of Mistral-7B trained on public datasets but also optimized with knowledge distillation techniques. The model has achieved incredible results, outperforming much larger models across a variety of tasks.
In recent studies, distillation has emerged as a valuable technique for enhancing open AI models across various tasks. Nevertheless, it falls short of achieving the same level of performance as the original teacher models. Users have observed that these models often lack “intent alignment,” meaning they do not consistently behave in a manner that aligns with human preferences. Consequently, they tend to produce responses that do not accurately address user queries.
Quantifying intention alignment has posed challenges, but recent efforts have resulted in the development of benchmarks like MT-Bench and AlpacaEval, specifically designed to assess this aspect. These benchmarks yield scores that closely correlate with human ratings of model outputs and validate the qualitative notion that proprietary models outperform open models trained with human feedback, which in turn perform better than open models trained with distillation. This underscores the significance of collecting meticulous human feedback for alignment, even at a significant scale, as seen in projects like LLAMA2-CHAT.
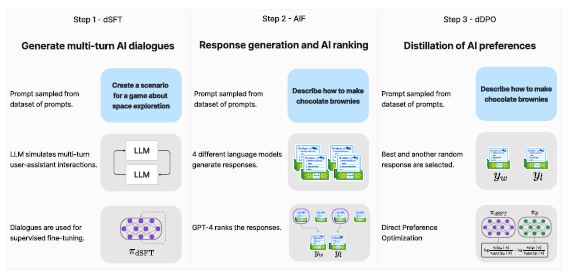
Validating that approach was the key goal behind ZEPHYR-7B, an aligned version of Mistral-7B. The process involves three key steps:
1. Large-scale dataset construction, self-instruct-style, using the UltraChat dataset, followed by distilled supervised fine-tuning (dSFT).
2. Gathering AI feedback (AIF) through an ensemble of chat model completions and subsequent scoring by GPT-4 (UltraFeedback), which is then transformed into preference data.
3. Distilled direct preference optimization (dDPO) applied to the dSFT model using the collected feedback data.
The fine-tuning process behind ZEPHYR-7B has its roots in three fundamental techniques:
1. Distilled Supervised Fine-Tuning (dSFT): initiates with a raw language model, requiring training to generate responses to user prompts. This conventional step typically involves supervised fine-tuning (SFT) on a dataset containing high-quality instructions and responses. However, when a teacher language model is available, the model can generate instructions and responses directly, and this process is termed distilled SFT (dSFT).
2. AI Feedback through Preferences (AIF): leverages human feedback to enhance language models. Traditionally, human feedback is collected through preferences that assess the quality of model responses. In the context of distillation, AI preferences from the teacher model are used to evaluate outputs generated by other models.
3. Distilled Direct Preference Optimization (dDPO): Aims to refine the dSFT model by maximizing the likelihood of ranking preferred responses over less preferred ones. This is achieved through a preference model defined by a reward function that utilizes the student language model. Previous approaches using AI feedback primarily employ reinforcement learning methods like proximal policy optimization (PPO) to optimize model parameters with respect to this reward function. These methods typically involve training the reward function first and then generating updates by sampling from the current policy.
Using ZEPHYR-7B
ZEPHYR-7B is available via the HuggingFace’s transformers library using a very simple interface. Executing ZEPHYR-7B requires only calling the pipeline() function of the library.
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <U+007CsystemU+007C>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <U+007CuserU+007C>
# How many helicopters can a human eat in one sitting?</s>
# <U+007CassistantU+007C>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
The Results
Hugging Face’s primary assessments for ZEPHYR-7B focus on both single-turn and multi-turn chat benchmarks that gauge a model’s capacity to adhere to instructions and provide responses to intricate prompts across diverse domains:
1. MT-Bench: This multi-turn benchmark encompasses 160 questions spanning eight distinct knowledge areas. In MT-Bench, the model faces the challenge of answering an initial question and subsequently providing a follow-up response to a predefined question. The quality of each model’s response is evaluated using a scale from 1 to 10 by GPT-4. The final score is derived from the mean rating over the two turns.
2. AlpacaEval: AlpacaEval, on the other hand, is a single-turn benchmark where models are tasked with generating responses to 805 questions spanning various topics, with a predominant focus on helpfulness. GPT-4 also assesses these model responses. However, the ultimate metric is the pairwise win-rate compared to a baseline model.
In addition to these benchmarks, Hugging Face evaluates ZEPHYR-7B’s performance on the Open LLM Leaderboard. This leaderboard is designed to assess language models across four multiclass classification tasks, including ARC, HellaSwag, MMLU, and Truthful QA. Each task presents unique challenges and requires the model to excel in classification accuracy.
The results were quite impressive:

ZEPHYR-7B represents a major validation that there is a place for small, high-performance LLMs for highly specialized tasks.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

