



A Dual Augmented Two-tower Model for Online Large-scale Recommendation
Last Updated on December 11, 2023 by Editorial Team
Author(s): Saankhya Mondal
Originally published on Towards AI.
Recommendation systems are algorithms that are designed to provide personalized suggestions to users. These systems are employed in various domains to help users discover relevant items, such as products (e-commerce like Amazon), other users (social media like X, LinkedIn), content (social media like X, Instagram, Reddit), or information (news apps or social media like X, Reddit or platforms like Medium and Quora), based on their preferences, behavior, or context. Recommendation systems aim to enhance user experience by offering personalized and targeted suggestions, ultimately facilitating decision-making and engagement. Generally, a recommendation system consists of retrieving entities (items, users, info) followed by ranking the retrieved entities.
This post will discuss the “Dual Augmented Two-tower Model for Online Large-scale Recommendation”, a retrieval model architecture proposed by researchers at Meituan, a Chinese e-commerce company. This is an enhanced version of the popular two-tower model used in recommendation systems.
Two-tower Model
Let’s first discuss the two-tower model. The term “two-tower” arises from two separate “towers” in the architecture, one for each entity. The two-tower model is designed to capture and learn embeddings of two different entities separately. These entities could be “user”- “user”, “user”- “item”, or “search query”- “item” based on the use case. The model consists of the two towers with embedding layers, followed by an interaction layer to capture their relationship, and an output layer for generating recommendation scores.
A downside of the original two-tower model is the lack of interaction between the two entities. There’s no interaction between the two entities apart from the final interaction layer, where their respective embeddings are used to compute a similarity metric like cosine-similarity. The paper solves this issue by introducing a novel Adaptive-Mimic Mechanism. The paper also provides a solution to solve the category imbalance issue. In many use cases, such as e-commerce, some categories may have a larger number of items and hence more interaction among the users, and some categories may have a lesser number of items and lesser interaction among the users. The paper introduces a Category Alignment Loss to mitigate the effect of category imbalance on the generated recommendations. The following diagram shows the network architecture.

Problem Statement
Let’s take up the example of “search query”- “item” use-case. We have been given a set of N queries u_i (i = 1, 2, ..., N), a set of Mitems v_j (j = 1, 2, ..., M), and the query-item feedback matrix R. R is a binary matrix, R_ij = 1denoting positive feedback between the corresponding query u_iand item v_jand, R_ij = 0denoting the otherwise. The objective is to retrieve a given number of candidate items from a huge corpus of items based on the query provided by the user.
Dual Augmented Two-tower Model
The Dual Augmented Two-tower (DAT) model has the following components —
- Embedding layer — Similar to the two-tower model, each query or item feature is converted to its embedding representation (usually sparse). These features could be user/item features, context/content features, etc.
- Dual augmented layer — For a certain query and candidate item, their augmented vectors
a_uanda_vare created and concatenated into their respective feature embedding. When trained and learned, we expect the augmented vectors to not only contain information about the current query and item but also contain information about their historical positive interactions. The following image shows an example of concatenated input embeddings.

- Feedforward layers — The concatenated embeddings
z_uandz_vare passed through feedforward layers; the output of each tower is a low-dimension representation of a queryp_uand an itemp_v. L2 normalization is performed, followed by their inner product. The output of the model iss(u, v) = <p_u, p_v>. The obtained output is considered as the score of the given query-item pair. - Adaptive-Mimic Mechanism (AMM) — The augmented vectors,
a_u, anda_vare learned using the mimic losses. The mimic losses aim to use the augmented vectors to fit all positive interactions in the other tower belonging to the corresponding query or item. If labely = 1,a_vapproachesp_uanda_uapproachesp_v. In this case, the loss functions aim to reduce the distance betweena_vandp_uanda_uandp_vrespectively. If the labely = 0, the loss terms are equal to 0. The augmented vectors are used in one tower and the query/item embeddings are generated from the other. That is to say, the augmented vectors summarize the high-level information about what a query or an item possibly matches from the other tower. Since the mimic loss is to updatea_uanda_v, we should freeze the values ofp_uandp_v.
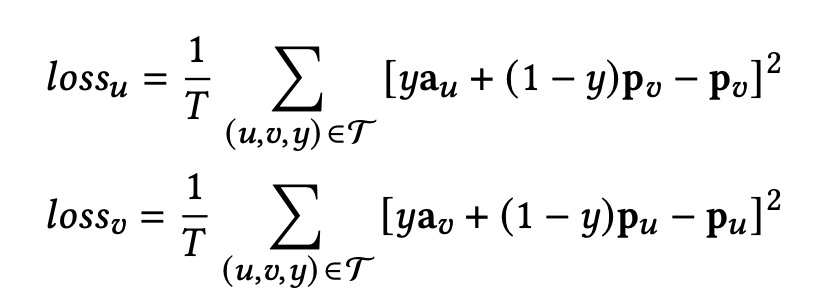
- Category Alignment —According to the authors, the two-tower model performs differently for the different categories. It performs much worse in the categories with a relatively smaller number of items. To tackle the problem, they introduced the Category Alignment Loss (CAL), which transfers the knowledge learned in the categories with a large amount of data to other categories. For each batch, CAL is defined as the sum of the Frobenius norm between the covariance matrix of the majority category item in that batch
C(S^major)and the covariance matrices of the other category items in that batchC(S^i). This loss ensures the covariances (which are second-order statistics) remain consistent across all categories. Note that the item embeddings,p_vare used for computing the covariance matrices.

Model Training
The problem is modelled as a binary classification task — whether the retrieved item is relevant or not. The tuple {u_i, v_j, R_ij=y} is fed to the model during training. A random negative sampling framework is used for creating training batches. During training, one batch of inputs consists of a positive pair of query-item (label y = 1) and S randomly sampled negative pairs of query-items (label y = 0). Cross-entropy loss is used here.

The final loss function is as shown below —

Implementation Details
The embeddings were scaled down to a dimension of 32 using three fully connected feed-forward layers of dimensions 256, 128, and 32. The dimension of augmented vectors was also set to 32. The authors performed their experiments on their own Meituan dataset and the publicly available Amazon Books dataset.

Results and Evaluation
For evaluation, HitRate@K and Mean Reciprocal Rank (MRR) were used. K was set to 50 and 100. Due to the large scale of testing instances, the authors scaled the MRR by a factor of 10.
- HitRate@K — A metric that measures the proportion of instances where the true positive recommendation is found within the top-K recommendations.
- Mean Reciprocal Rank (MRR) — A metric obtained by calculating the average reciprocal rank of the first correct recommendation.
The following table summarizes the results and compares the results of the DAT model with other models such as the matrix factorization model, two-tower model, and YouTubeDNN etc. DAT performed the best showcasing the effectiveness of both AMM and CAL.

The authors tweaked the dimension of the augmented vectors and observed the change in performance. You can observe the results in the following plots.

The above two results were based on offline studies. The authors observed the model’s performance on the following metrices by deploying it to handle real traffic involving 60 million users for one week.
- Click-Through Rate (CTR) — A metric that measures the percentage of users who clicked on an item, indicating the effectiveness of engaging content.
- Gross Merchandise Value (GMV) — A metric that represents the total value of goods or services sold through a platform.
Here the original two-tower model was considered the baseline. Both models retrieved 100 candidate items. Retrieval of the candidates is performed using approximate nearest neighbor search. The retrieved items were fed to the same ranking algorithm for fair comparison. The DAT model outperformed the baseline by a large margin, with an overall average improvement of 4.17% and 3.46% in terms of CTR and GMV, respectively.

To conclude, the Dual Augmented Two-tower model aims to facilitate cross-tower deep interactions and produce better representations for imbalanced category data, thereby improving retrieval metrices like HitRate@K and MRR and ranking metrices like CTR and GMV.
I hope you find the article insightful. Here’s the link to the original paper — A Dual Augmented Two-tower Model for Online Large-scale Recommendation (dlp-kdd.github.io).
Thank you for reading!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

