



3 Steps to Improve Artificial Intelligence in Healthcare
Last Updated on July 22, 2020 by Editorial Team
Author(s): Avishek Choudhury
Artificial Intelligence, Research
Optimal Trust, Data Governance, and AI Standards can solve many problems concerning AI in healthcare.
Accuracy, precision, recall and other measures of AI efficacy are crucial but not sufficient.
Will you use, trust, or make clinical decisions based on a technology that runs on “bad data” and are neither “clinically validated” nor “FDA approved” ?
From virtual assistants to technologies such as Apple Watch and IBM Watson, several applications of artificial intelligence (AI) have been established to augment health care systems, improve patient care, and assist care-providers. The growing involvement of technology giants such as Google, Apple, and IBM in health care technology have further enhanced the need to understand better the influence of AI on the health care industry. Many health care organizations are employing AI technologies to create new value in the industry. On July 7, 2020, North Highland, a leading change and transformation consulting firm, announced a strategic partnership with Digital Reasoning, the global leader in artificial intelligence solutions that understand human communications and behaviors. The strategic collaboration shall assist healthcare providers in diagnosing cancer.
AI has been recognized as one of the primary influencers of the health care industry. Several researchers have invested in showcasing the analytical power of AI and how it can outperform physicians at making diagnoses in specialties such as radiology, dermatology, intensive care, and performing surgical interventions.
Despite all the noteworthy potential of AI, why do healthcare industries across the world hesitate to integrate this incredible technology into their daily clinical routines?
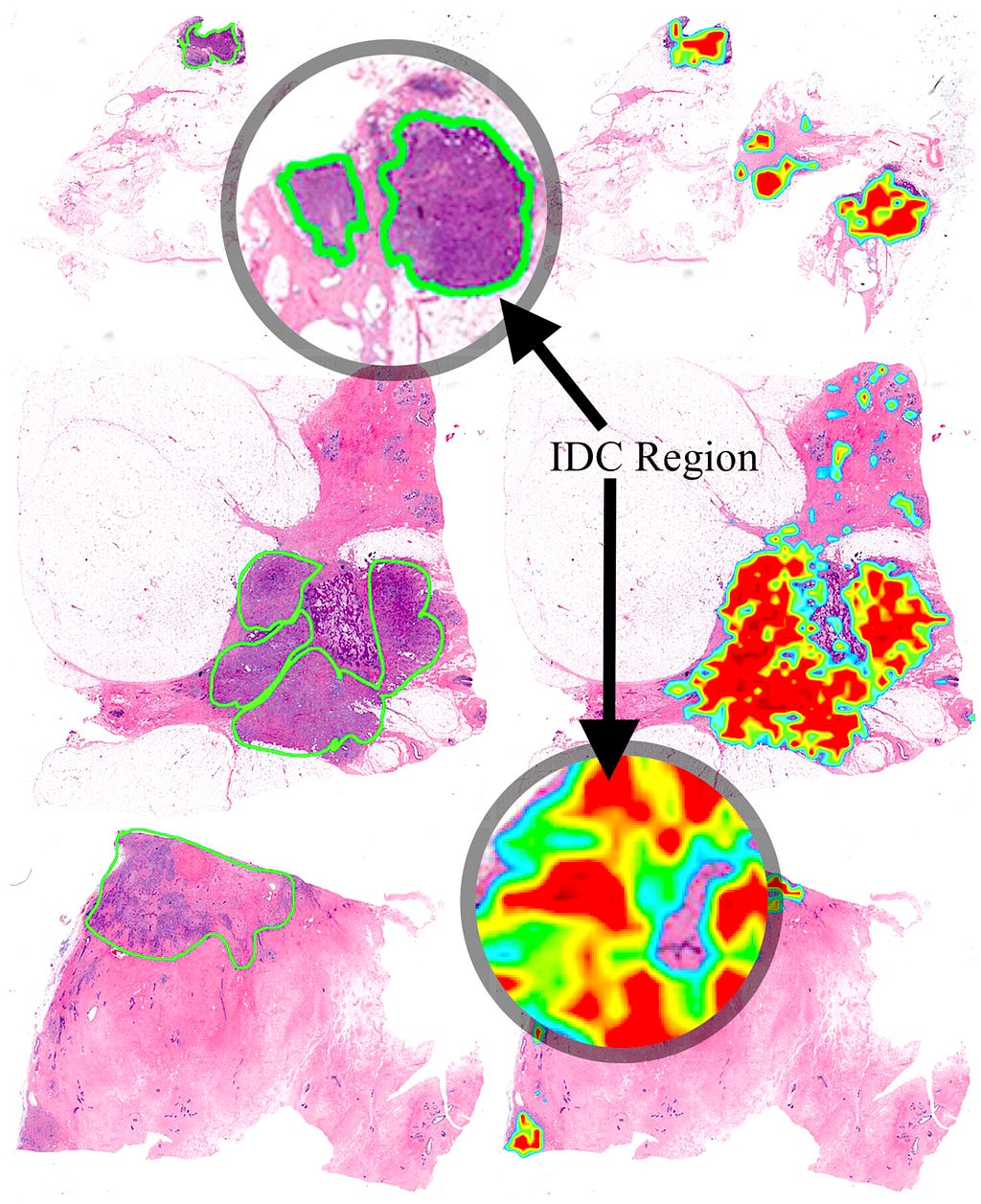
AI systems should be designed and implemented to satisfy health outcomes and policy priorities, including but not limited to:
- Improving quality, safety, efficiency
- Reducing health disparities
- Improving diagnosis outcomes
- Engaging patients and families in their health
- Improving care coordination
- Improving population and public health
- Ensuring security for personal health information
- Minimizing clinicians workload
However, analytical performance alone cannot fulfill all expectations we have from AI.
Following are the 3 steps that can improve acceptance and quality of Artificial Intelligence in Health Care

Step 1. Ensure optimal trust in artificial intelligence
Trust in AI Technology is a significant factor that requires immediate attention. In the evolving (dynamic) relationship between users and AI, trust is the one mechanism that shapes clinicians’ use and adoption of AI. The same is true for patients. Patients’ trust in AI depends on their prior experience with health care technologies and technical knowledge about AI. The media also plays an important role in steering peoples’ trust in AI.
“Trust is a psychological mechanism to deal with the uncertainty between what is known and unknown.”
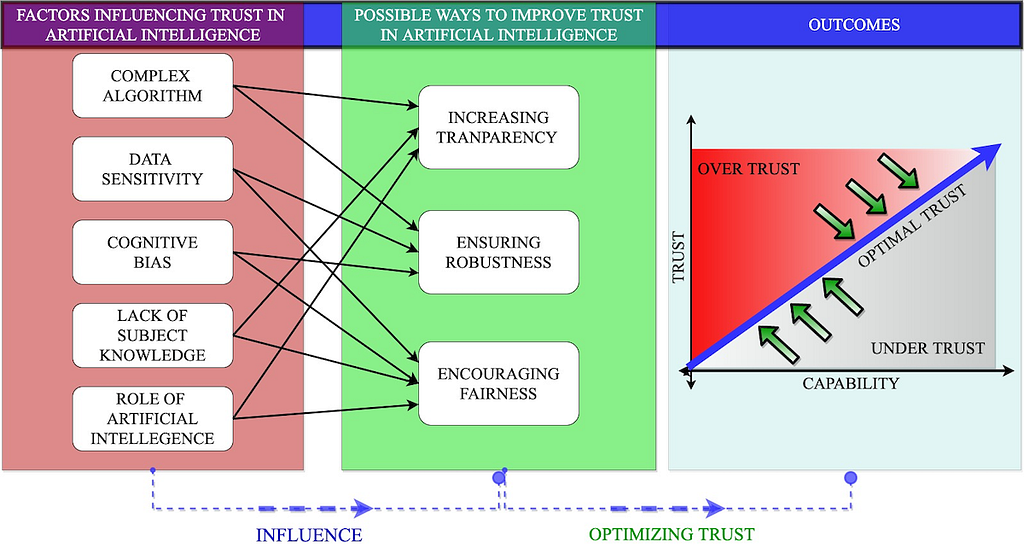
Currently, a lack of trust in artificial intelligence is one of the significant drawbacks in the adoption of this technology in health care. Artificial intelligence in health care influences trusts between users and AI systems and between different users (care-givers and care-recipients). The dynamic behavior of trust makes it arduous to comprehend. Like any other technology, trust in AI can be influenced by human factors not limited to user experiences, user biases, and perception towards the technology.
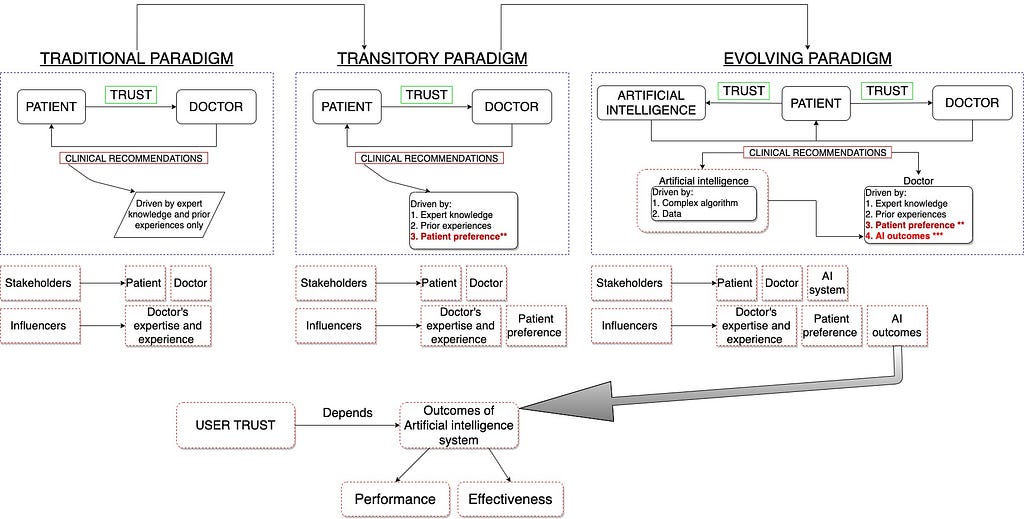
Users’ trust in artificial intelligence can also vary with its immediate, mid-term and long term performance (outcome/impact).
For example, A clinician’s trust in the AI system might increase after observing a 99% accuracy rate for lesion detection. However, the same clinician might stop trusting the system on realizing that the system only works on patients with specific skin color.
Will Trust in artificial intelligence solve all the problems?
Recent study in JMIR [1] have highlighted the importance of optimal trust and the risks associated with maximum trust. The study claims that maximizing the user’s trust does not necessarily yield the best decisions from a human-AI collaboration. When trust is at maximum, the user accepts or believes all the recommendations and outcomes generated by the AI system.
Unnecessarily high trust in AI may have catastrophic consequences, especially in life-critical applications.
Whereas, in optimal trust, both humans and AI have some level of skepticism regarding the other’s decisions which encourages them to scrutinize each others functioning and recommendations. However, quantification of trust is challenging. Although there exists human factor’s techniques to measure (estimate) trust using validated questions, it fails to capture the dynamic behavior of trust over time.

Step 2. Develop and strengthen Data Governance
A review accepted in JAMIA Open [2] shows the need for data governance which has also been acknowledged by The Royal Society of Great Britain. The goal of data governance encompasses the aspects of legal and ethical norms of conduct along with the conventions and practices that govern the collection, storage, use, and transfer of data.
Machine Learning algorithms highly depend on data. Their properties, such as reliability, interpretability, and responsibility, rely on the quality of data they are trained on. Most of the research in the field of machine learning and health care often use data from online databases (that store complete and standardized data for research purposes) and observational studies. Data obtained from such sources are prone to biases. Models trained on such data might not work as efficiently in a clinical environment where data are unstructured, incomplete, and noisy. Electronic Health Records, one of the primary sources of data in hospitals, are also prone to bias due to the under or over-representation of specific patient populations. Besides, different research institutions record patient data differently.
“Machine Learning models trained at one institution when implemented to analyze data at another institution might result in errors”
Electronic Health Records contains varying data structures (often not compatible with other systems), creating a significant challenge to model deployment. Recently, the Department of Health and Human Services, led by the Office of the National Coordinator for Health Information Technology (ONC), released the draft 2020–2025 Federal Health IT Strategic Plan with the motive to augment Health IT infrastructure and update Electronic Healthcare Records’ meaningful use criteria to include interoperability standards.
The dependence of machine learning on historical data is another factor that can potentially impede its effectiveness in health care. Historical data retrieved from medical practices contains health care disparities in the provision of systematically worse care for vulnerable groups than for others. In the United States, historical health care data reflect a payment system that rewards the use of potentially unnecessary care and services and may be missing data about uninsured patients. Unlike static datasets, patient health evolve with time and using historical data might prevents AI models to learn from the evolving health status of patients. Since health care data are protected by HIPPA regulations, training a model on population data is not feasible (at this moment). Therefore, avoiding the risk of biased data is challenging (inevitable).

One practical solution to this can be developing an AI model for local use. In other words, training AI models for a specific patient group (Pulmonary embolism and Deep vein thrombosis) for a specific purpose (binary classification to identify pulmonary embolism and deep vein thrombosis) in a specific geographic location. Such models can be trained on a dataset that is a good representation of all patient types in a given locality. Although this process will embed bias (effective for specific patient types and will not work on new patient types) into the AI model, it can be implemented by small specialized outpatient clinics (hematologist) with a manageable number of clients (regular patients with chronic ailments).
How much data is sufficient to train an algorithm? — has been unanswered in the field of machine learning. The concern regarding sample size encompasses the number of data points (observations — rows in the data table) and the number of predictors (health factors — columns in a data table). There are methods in data science that can handle data dimensionality problems, and feature selection techniques often improve AI performance. However, the elimination of features (predictors) deter clinical explainability of the dataset. Although algorithmic performance, particularly in deep learning, improves with the addition of information, plateaus exist wherein new information adds little to model performance (depending on the activation function). Some model’s accuracy can be hindered with increasing information (data) usually because the additional variables tailor (overfit) the models for a too-specific set of information (context). Such a model might perform poorly on new data, a problem long recognized as prediction bias or overfitting or minimal-optimal problem. Therefore, we must understand (a) the rate at which an algorithm’s performance increases with increasing data, and (b) the maximum accuracy achievable by the model without overfitting.

Step 3. Develop AI Standards
Although artificial intelligence has potential to assist clinicians in making better diagnoses, its analytical performance does not necessarily indicate clinical efficacy. With the deployment of AI in health care, several risks and challenges can emerge at an individual level (eg, awareness, education, trust), macro-level (eg, regulation and policies, risk of injuries due to AI errors), and technical level (eg, usability, performance, data privacy and security).
System error in a widely used AI might lead to mass patient injuries compared to a limited number of patient injuries due to a provider’s error.
Owing to the wide range of effectiveness of AI, it is crucial to understand actual influence (negative or positive) of artificial intelligence which can only be realized when it is integrated into clinical settings or interpreted and used by care providers.
Did the trained AI-model’s recommendation improved patient health outcome?
Most of the AI models featured in different studies and research are not executable in the real clinical setting. This is due to two primary reasons:
- The AI models reported in research literature do not re-engineer themselves based on data and work environment. Moreover, external influences not limited to political and economic factors along with medical practice norms, and commercial interests steer the way care is delivered.
- Most healthcare organizations worldwide do not have the required data infrastructure to collect and train AI algorithms, nor do the clinicians have sufficient training to use and interpret complex AI systems
Most clinical AI models are complex, and their integration and intervention mandate consensus among various components, not limited to the healthcare system itself, the governing protocol, the users, and the work environment. Therefore, a standardized approach is necessary. A review in JMIR Medical Informatics [3] and a perspective paper in the British Journal of Healthcare Management [4] advocates for the need of AI-standardization.
Relying on AI outcomes that have not been evaluated against a standard benchmark that meets clinical requirements can be misleading.
A study [5] conducted in 2008 developed and validated an advanced version of the QRISK cardiovascular disease risk algorithm (QRISK2). The study reported improved performance of QRISK2 when compared to its earlier version. However, QRISK2 was not compared against any clinical gold standard. Eight years later, in 2016, The Medicines & Healthcare Products Regulatory Agency identified an error in the QRISK 2 calculator; QRISK2 underestimated or overestimated the potential risk of cardiovascular disease. The regulatory agency reported that a third of general practitioner surgeries in England might have been affected due to the error in QRISK2.
Much work has been done in standardizing artificial intelligence research and development. On February 11, 2019, the President (of the United States) issued an Executive Order (EO 13859) directing Federal agencies to develop a plan to ensure AI/ML standards [6]. A few months later, on June 17, 2019, China’s Ministry of strategy. As of February 2020, there is also extensive information about Russian AI policy Generation of Artificial Intelligence: Develop Responsible Artificial Intelligence. In October 2019, the Office of the President of the Russian Federation released a national AI available that is published in OECD AI Policy Observatory.

Conclusion
The effectiveness of human-AI collaboration is a function of trust. A holistic approach recognizing health care as a dynamic socio-technical system in which is necessary to understand trust relationships in human-AI collaboration. The efforts taken so far in AI/ML standardization are focused on developing a common (national) standard for all AI applications and ML algorithms. Since many of the issues around machine learning algorithms, particularly within healthcare, are context-specific, healthcare requires standards (governance) that are tailored towards its goal. Future studies should work toward establishing a gold standard against which AI performance can be measured.
References
[1] O. Asan, E. Bayrak and A. Choudhury, Artificial Intelligence and Human Trust in Healthcare: Focus on Clinicians (2020), JMIR
[2] A. Choudhury, E. Renjilian and O. Asan, Use of machine learning in geriatric clinical care for chronic diseases: a systematic literature review (2020), JAMIA Open [In Press]
[3] A. Choudhury and O. Asan, Role of artificial intelligence in patient safety outcomes: Systematic literature review (2020), JMIR Medical Informatics [In Press]
[4] A. Choudhury, A framework for safeguarding artificial intelligence systems within healthcare (2019), British Journal of Healthcare Management
[5] J. Hippisley-Cox, C. Coupland, Y. Vinogradova, et al., Predicting cardiovascular risk in England and Wales: prospective derivation and validation of QRISK2 (2008), BMJ
[6] Executive Order 13859, Maintaining American Leadership in Artificial Intelligence (2019), Federal Register
3 Steps to Improve Artificial Intelligence in Healthcare was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

