



26 Words About Machine Learning, Every AI-Savvy Leader Must Know
Last Updated on May 15, 2020 by Editorial Team
Author(s): Yannique Hecht
Artificial Intelligence
Do you think you can explain these? Put your knowledge to the test!
[This is the 5th part of a series. Make sure you read about Search, Knowledge, Uncertainty, and Optimization before continuing. The next topics are Neural Networks and Language.]

Global search queries for “machine learning” skyrocketed in the past five years.
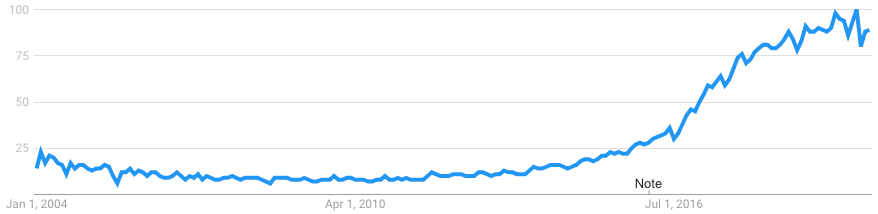
Perhaps, we can explain our curiosity by the lack of a clear uniform definition and perimeter of the term. Currently, the version closest to unanimous acceptance probably sounds like “computers’ ability to learn without being explicitly programmed.”
But there’s more
Our news feeds, business journals, and proclaimed experts bombard us with buzzwords like supervised learning, unsupervised learning, reinforcement learning, and last but most popular these days, deep learning.
How do you distinguish all these fields?
And how can machines learn by themselves?
To help you answer these questions, this article briefly defines and explains the main concepts and terms around the field of learning.
Supervised Learning:
Supervised learning: a machine learning task; learning a function that maps an input to an output based on example input-output pairs
Classification: a supervised learning task; learning a function mapping an input point to a discrete category
Nearest-neighbor classification: an algorithm that, given an input, chooses the class of the nearest data point to that input
K-nearest-neighbor classification: an algorithm that, given an input, selects the most common class out of the k nearest data points to that input
Weight factor: a weight given to a data point to assign it a lighter, or heavier, importance in a group
Perceptron learning rule: a method, given data point (x, y), which updates each weight according to:
w[i] = w[i] + α(actual value - estimate) × x[i]
w[i] = w[i] + α (y — h[w](x)) × x[i]
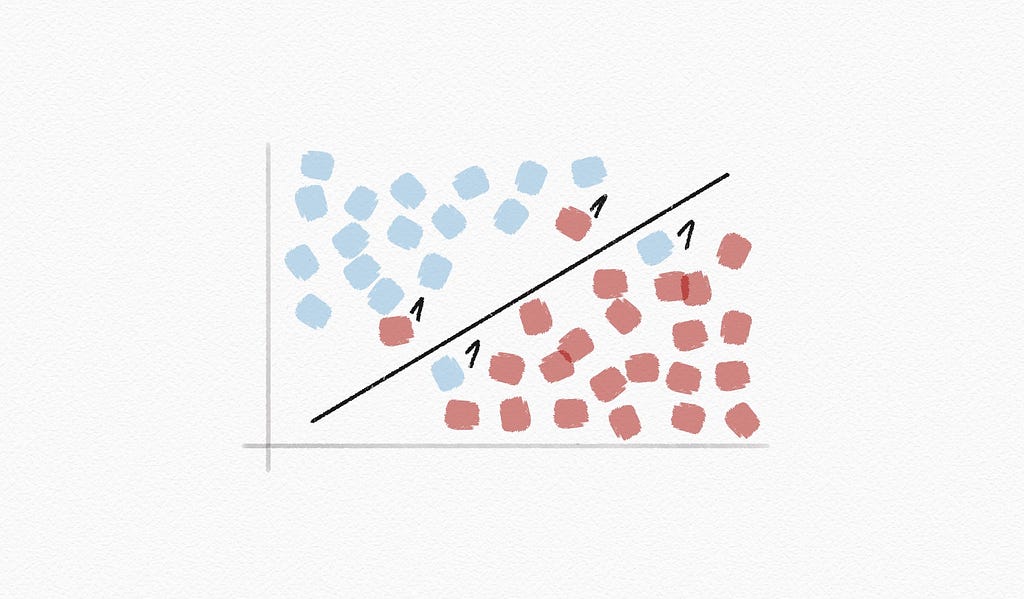
Support vector machine: (or SVM) a popular supervised machine learning algorithm that analyzes and sorts data into two categories for classification and regression analysis

Maximum margin separator: a boundary that maximizes the distance between any of the data points
Regression: a supervised learning task; learning a function mapping an input point to a continuous value, thus being able to predict real numbered outputs
Evaluating Hypotheses:
Loss function: a function that expresses how poorly our hypothesis performs
0–1 loss function: a simple indicator function providing information about the accuracy of predictions; returning 0 when the target and output are equal, or else it returns 1:
L(actual, predicted) =
0 if actual = predicted,
1 otherwise
L1 loss function: a loss function used to minimize error, by summing up all absolute differences between the true and predicted values:
L(actual, predicted) = | actual - predicted |

L2 loss function: a loss function used to reduce error, by summing up all squared differences between the true value and predicted values, thus penalizing single high variations:
L(actual, predicted) = (actual — predicted)^2
Overfitting: a model that fits too closely to a particular data set and therefore may fail to generalize to future data
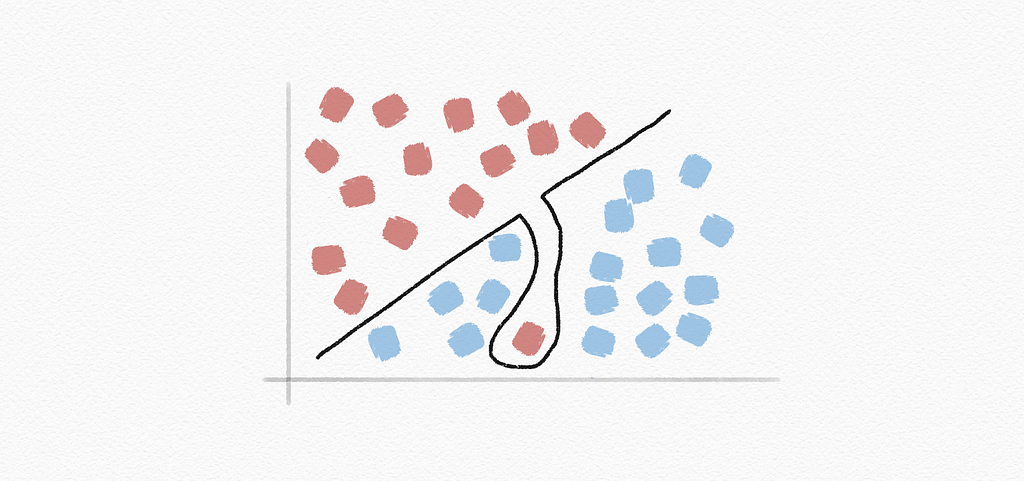
Regularization: penalizing hypotheses that are more complex to favor simpler, more general hypotheses
cost(h) = loss(h) + λcomplexity(h)
Holdout cross-validation: splitting data into a training set and a test set, such that learning happens on the training set and on the test set
K-fold cross-validation: splitting data into k sets, and experimenting k times, using each set as a test set once, and using remaining data as a training set
Reinforcement Learning:
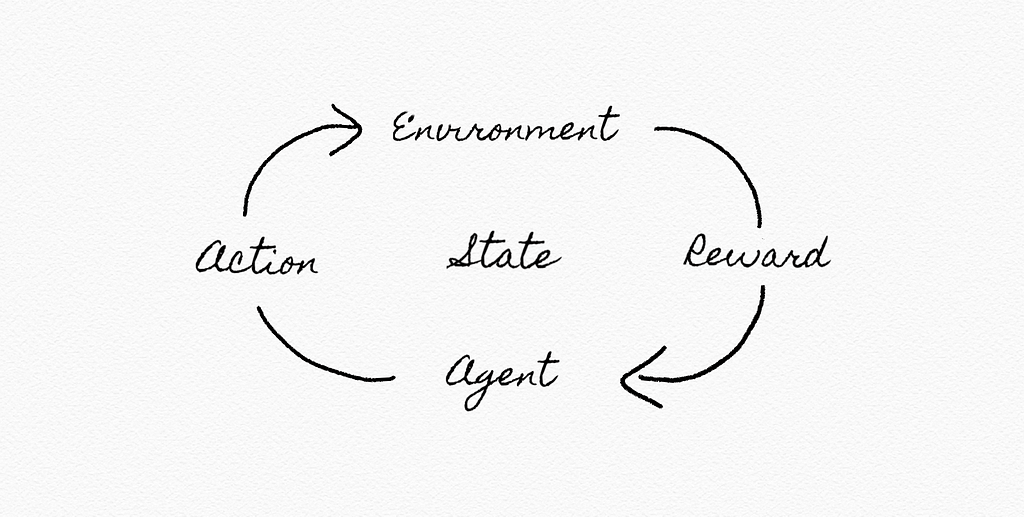
Reinforcement learning: given a set of rewards or punishments, learn what actions to take in the future
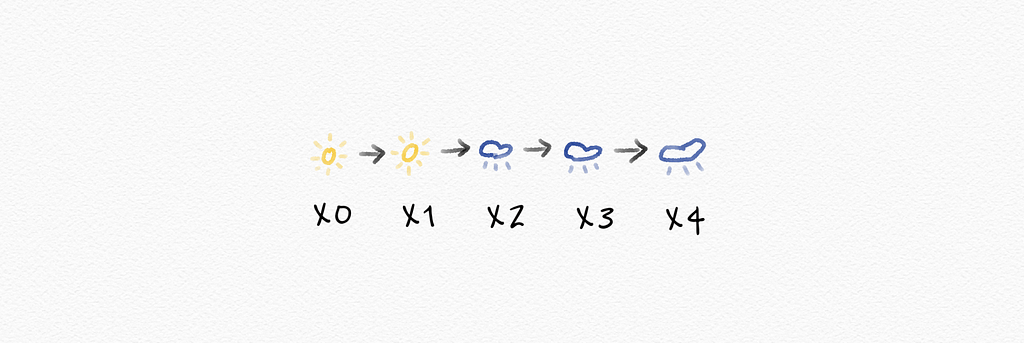
Markov chain: a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event
Markov decision process: a model for decision-making, representing states, actions, and rewards
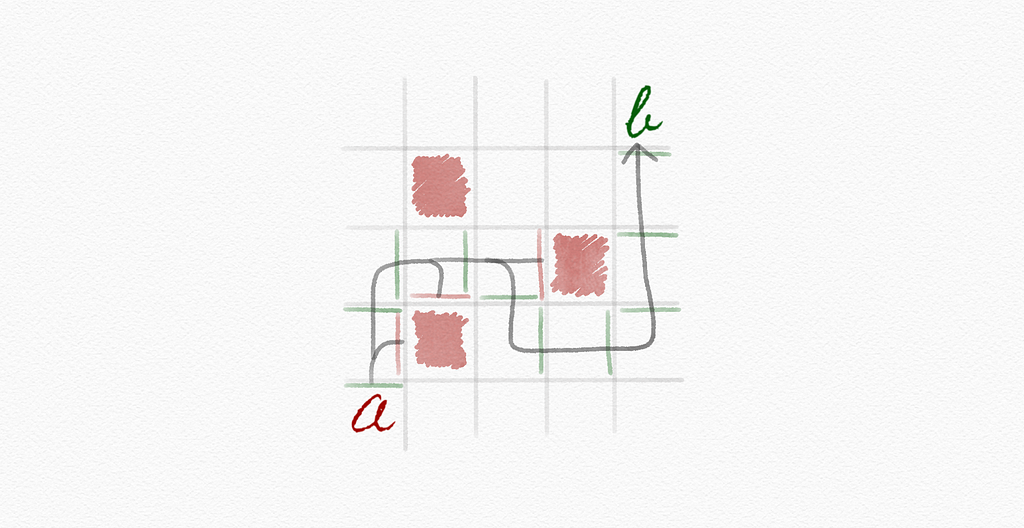
Q-learning: a method for learning a function; an estimate of the value of performing action a in state s
Q(s, a)
Greedy decision-making: when in state s, choose action a with max. Q(s, a)
ε-greedy: (or epsilon-greedy) a simple machine learning algorithm that takes randomness into account when deciding between explorative and exploitative options:
1-ε (exploitative, choose estimated best move)
ε (explorative, choose a random move)
[If you’re curious about the exploration vs. exploitation debate, check out this article by Ziad SALLOUM.]
Function approximation: approximating Q(s, a), often by a function combining various features, rather than storing one value for every state-action pair
Unsupervised Learning:
Unsupervised learning: given input data without any additional feedback and learn patterns
Clustering: organizing a set of objects into groups in such a way that similar objects tend to be in the same group
K-means clustering: an algorithm for clustering data based on repeatedly assigning points to clusters and updating those clusters’ centers
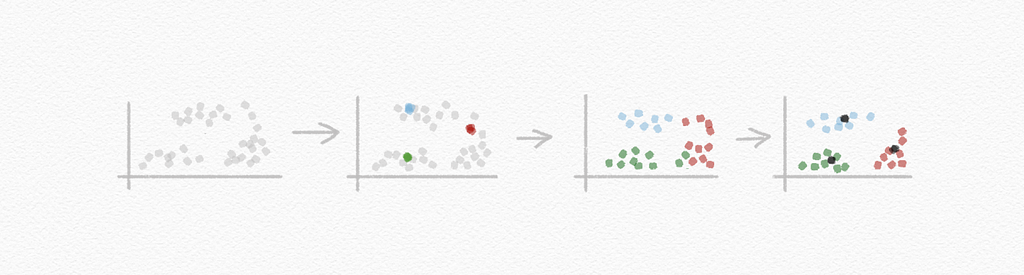
Now, equipped to continue your journey to becoming a fully-fledged AI-savvy leader, you should be able to explain key terms and concepts around machine learning. A field that is here to stay, and expected to be one of the main sources of value creation during this decade.
A breakthrough in Machine Learning would be worth ten Microsofts.
– Bill Gates
Explore similar related topics, including Search, Knowledge, Uncertainty, Optimization, Neural Networks, and Language.
Like What You Read? Eager to Learn More?
Follow me on Medium or LinkedIn.
About the author:
Yannique Hecht works in the fields of combining strategy, customer insights, data, and innovation. While his career has been in the aviation, travel, finance, and technology industry, he is passionate about management. Yannique specializes in developing strategies for commercializing AI & machine learning products.
26 Words About Machine Learning, Every AI-Savvy Leader Must Know was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

