



The Limits of Deep Learning
Last Updated on August 1, 2020 by Editorial Team
Author(s): Frederik Bussler
Deep Learning
Big compute needs limit performance, calling for more efficiency.
GPT-3, the latest state-of-the-art in Deep Learning, achieved incredible results in a range of language tasks without additional training. The main difference between this model and its predecessor was in terms of size.
GPT-3 was trained on hundreds of billions of words — nearly the whole Internet — yielding a wildly compute-heavy, 175 billion parameter model.
OpenAI’s authors note that we can’t scale models forever:
“A more fundamental limitation of the general approach described in this paper — scaling up any LM-like model, whether autoregressive or bidirectional — is that it may eventually run into (or could already be running into) the limits of the pretraining objective.”
This is the law of diminishing returns in action.
Diminishing Returns
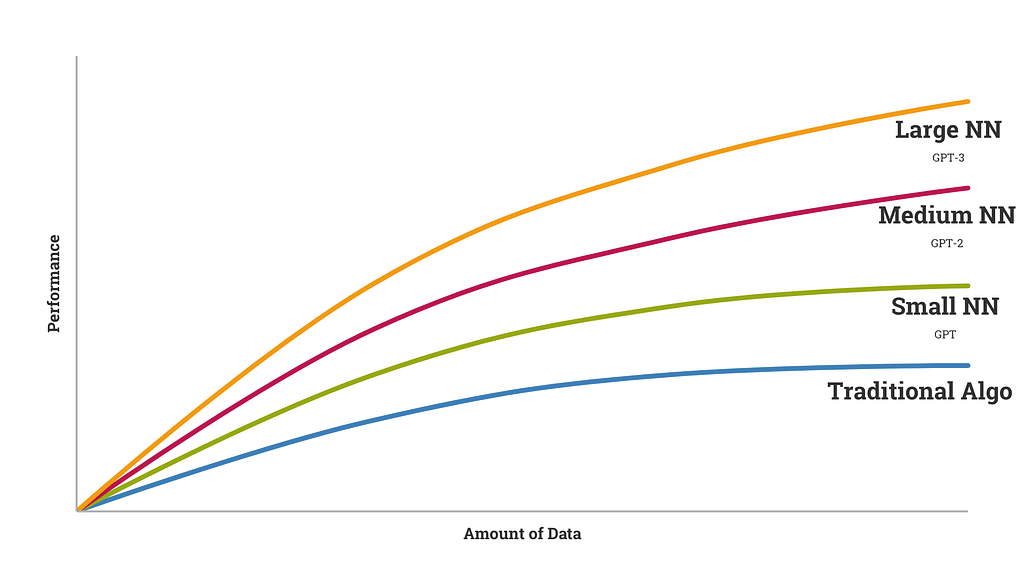
If you train a deep learning model from scratch with small data (not starting with ResNet or ImageNet, or some other transfer learning base), you’ll achieve lesser performance. If you train with more data, you’ll achieve more performance. GPT-3 showed that training on an enormous dataset, with a supercomputer, achieves state-of-the-art results.
Each successive GPT model improved on the last largely by scaling the training data.

However, it’s uncertain that scaling it up again — say, 10X the data and 10X the compute — would bring anything more than modest gains on accuracy. The paper “Computational Limits in Deep Learning” lays out these problems — Deep Learning is unsustainable, as-is:
“Progress along current lines is rapidly becoming economically, technically, and environmentally unsustainable.”
This example perfectly illustrates diminishing returns:
“Even in the more-optimistic model, it is estimated to take an additional 10⁵× more computing to get to an error rate of 5% for ImageNet.”
François Chollet, the author of the wildly popular Keras library, notes that we’ve been approaching DL’s limits:
“For most problems where deep learning has enabled transformationally better solutions (vision, speech), we’ve entered diminishing returns territory in 2016–2017.”
Deep Learning: Diminishing Returns? – Semiwiki
In fact, while GPT-3 is wildly bigger than GPT-2, it still has serious shortcomings, as per the paper’s authors:
“Despite the strong quantitative and qualitative improvements of GPT-3, particularly compared to its direct predecessor GPT-2, it still has notable weaknesses,” including “little better than chance” performance on adversarial NLI.
Natural Language Inference has proven to be a major challenge for Deep Learning, so much so that training on an incredibly large corpus couldn’t solve it.
“Black Box” AI — Poor Explainability
Another limitation of Deep Learning is its poor explainability. With enormous models like GPT-3 — recall that it has 175 billion parameters — explainability is near-impossible. We can only really guess as to why the model makes a certain decision, but with no real clarity.
For instance, if GPT-3 tells us that it prefers Minecraft over Fortnite, we could intuit that this is because the word “Minecraft” shows up more in its training data.
This problem is separate to Deep Learning’s poor efficiency, and the best solution, if you’re looking for explainability, is to simply use more explainable models.
For instance, some AutoML tools like Apteo gain insights from your data by selecting among models including decision trees and random forest, which have greater explainability than a deep neural network.
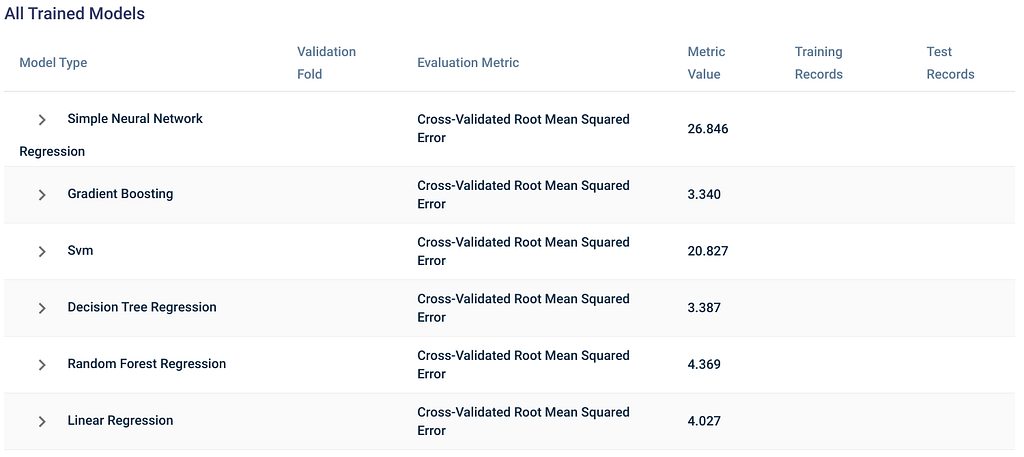
Ultimately, you need to weigh the relative importance of explainability in your use-case.
Achieving Greater Deep Learning Efficiency
The past few years have seen breakthrough after breakthrough in AI due to far greater compute and data, but we’re exploiting those opportunities to their limits.
The conversation needs to shift towards algorithmic and hardware efficiency, which would also increase sustainability.
Quantum Computing
In the last decade, computational improvements for DL included mostly GPU and TPU implementations, as well as FPGA and other ASICs. Quantum computing is perhaps the best alternative, as “it offers a potential for sustained exponential increases in computing power.”
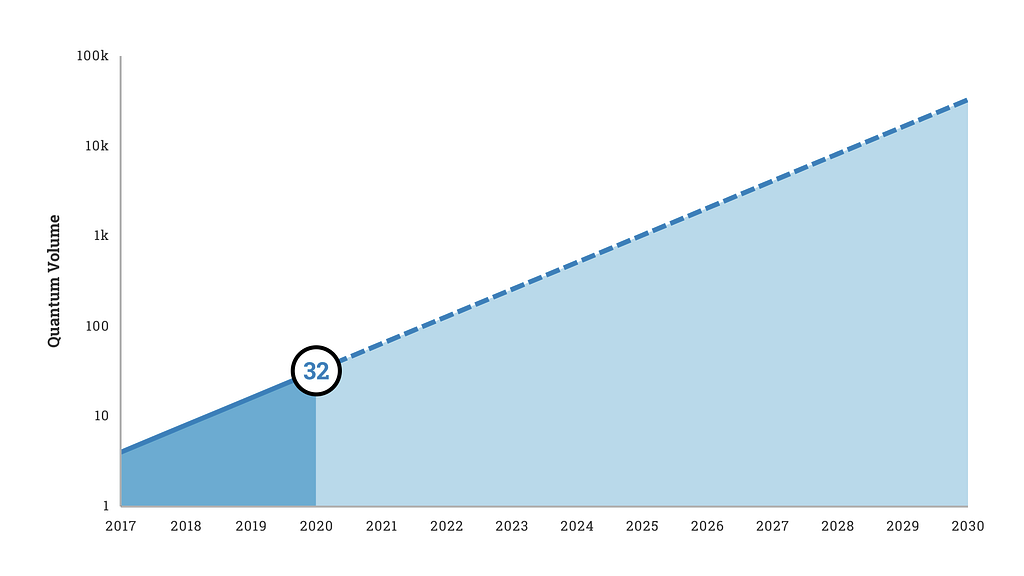
Current cutting-edge quantum computers, like IBM’s Raleigh, have a Quantum Volume of around 32, though Honeywell claims to have recently created a 64 Quantum Volume computer. IBM hopes to double its Quantum Volume every year.
Reducing Computational Complexity
GPT-3 is an incredibly complex model, with 175 billion parameters. One can reduce computational complexity by compressing connections in a neural network, such as by “pruning” away weights, quantizing the network, or using low-rank compression.
Results from these methods so far leave much to be desired, but this is one potential area of exploration.
High-Performance Small Deep Learning
Finally, one can use optimization to find more efficient network architectures, as well as meta-learning and transfer learning. However, methods like meta-learning can negatively impact accuracy.
Conclusion
Deep Learning has been a source of incredible AI breakthroughs in recent years, given ever-increasing data and compute, but Moore’s Law can’t go on forever. We’re already witnessing diminishing returns in scale models. Potential solutions include greater algorithmic and hardware efficiency, particularly in regard to quantum computing.
The Limits of Deep Learning was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



")
Recent Posts






")