Name: Towards AI
Legal Name: Towards AI, Inc.
Description: Towards AI is the world's leading artificial intelligence (AI) and technology publication. Read by thought-leaders and decision-makers around the world.
Phone Number: +1-650-246-9381
Email: pub@towardsai.net
228 Park Avenue SouthNew York,
NY10003United States
Areas Served: Worldwide
Alternate Name: Towards AI, Inc.
Alternate Name: Towards AI Co.
Alternate Name: towards ai
Alternate Name: towardsai
Alternate Name: towards.ai
Alternate Name: tai
Alternate Name: toward ai
Alternate Name: toward.ai
Alternate Name: Towards AI, Inc.
Alternate Name: towardsai.net
Alternate Name: pub.towardsai.net
This article contains essential information about some of the fundamentals of HTML and CSS.
Tags, Head tag, Inserting Stylesheet
Relative Path, Elements, Units
Preserving white space, Span, Opacity
Hypertext Reference, Source, Target
By the next article, you will be able to design a static responsive website and understand any front-end code of the website. These articles contain information based on the function of the elements because so many things are similar in HTML & CSS.
Motivation
Nowadays, web development plays a vital role in our daily lives, and everyone needs a website. Websites are used by the people to display a portfolio, interact with the people, integrate with the ML models, portrait the idea of the project, etc.
My motto is to say that It is not necessary to learn the complete web development unless you want to become a front end web developer. But, Everybody needs websites in daily life. So, It is okay to get the website code from the internet and makes changes as you like on the website, or you can design a website based on the time you have because time is precious and doesn’t waste it by working on the things which you don’t like.
Introduction
HTML stands for HyperText Markup Language. Hypertext refers to the hyperlinks that a page can contain, and Markup Language refers to the style of writing the scripts in the form of tags( ) in which the alignment and content of the webpage are completely based on tags. HTML is a case -insensitive language.
CSS stands for Cascading Stylesheets. It is used to style the webpage and describe the content and layout of the webpage. The main purpose of CSS is to present the website effectively. If several webpages have a similar type of styling, then CSS is helpful to define the styles, and it is linked to all the webpages. The entire CSS is referring to the content and defining the styles for the respective content. CSS is a case -insensitive language except for selector names such as class names and id names.
Bootstrap is an open-source framework that contains HTML, CSS, Javascript for designing responsive web pages based on the size of the screen, especially for mobile phones. The complete external source code is available in Bootstrap for every component of the webpage. It is recommended to use Bootstrap to design a website. Because it saves a lot of time provided you are not a beginner.
Getting Started
Tags
Tag is a basic word that represents the structure of the HTML Document. If the Element contains extra content, then it must have an opening tag at the start and closing tag at the end.
E.g.:
Heading
paragraph
A self-closing tag is a void element that does not strictly need any closing tag. Because it doesn’t have content. It is not mandatory to put ‘/’ character at the end of the tag.
E.g.:
Head tag
The Head tag is a container of Metadata. The content in the Head tag does not display in the Browser. The main purpose of the Head tag is to define the document title, character set, styles, scripts, etc. Metadata is referred by browsers and search engines when you browse about the particular HTML page.
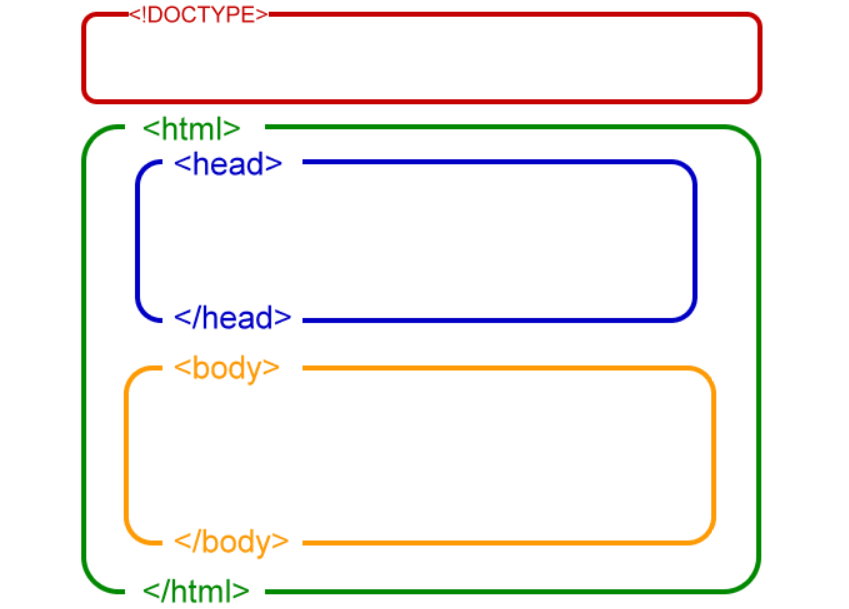
Basic Structure of HTML Page
Inserting Stylesheet
There are three ways to insert a CSS file into the HTML file:
External CSS
Internal CSS
Inline styles
Using external CSS stylesheets:
In this, an external CSS file is linked to the HTML document with the help of a link tag inside the head tag. It is always recommended to use external stylesheet linking. We can make changes in the CSS file easily without disturbing the primary HTML file. This leads to faster loading of the website.
Using internal CSS stylesheets:
The name itself defines writing the CSS code inside the HTML page. The content of CSS is written in a style tag that is inside the body tag. There is no extra sheet required for styling the webpage. This can also be called Embedded styling.
Using inline styles:
The style attribute is used inside the HTML element. All the CSS properties can be included in the style attribute in a serial format. The style attribute assigns the corresponding CSS properties to the HTML element. The priority of the Style attribute is very high compared to internal and external styles.
The path of a certain file corresponding to the current position of the file is called the Relative path. Many people mess up to link one page to another page. But, It is easy if we understand the levels.
../ is to go back to a level(lower level)
[Folder_name]/ is to go into the specified folder(upper level)
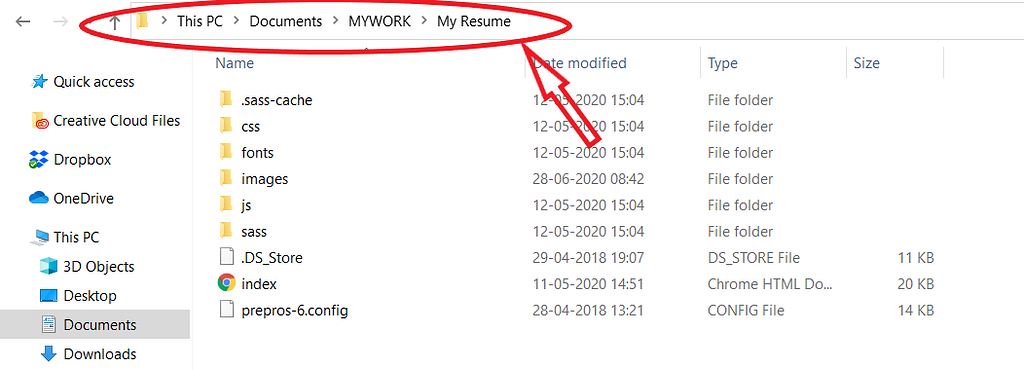
Follow red ellipses for easy understanding.
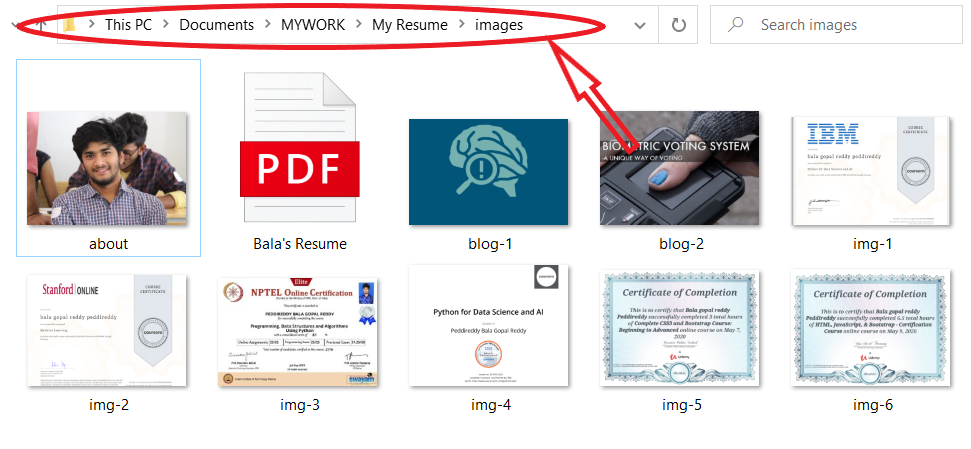
In the above picture, all the elements are at the same level. To get an image that is in the images folder into an HTML file(index.html), You should move one level up. Use the command:
images/about.jpg
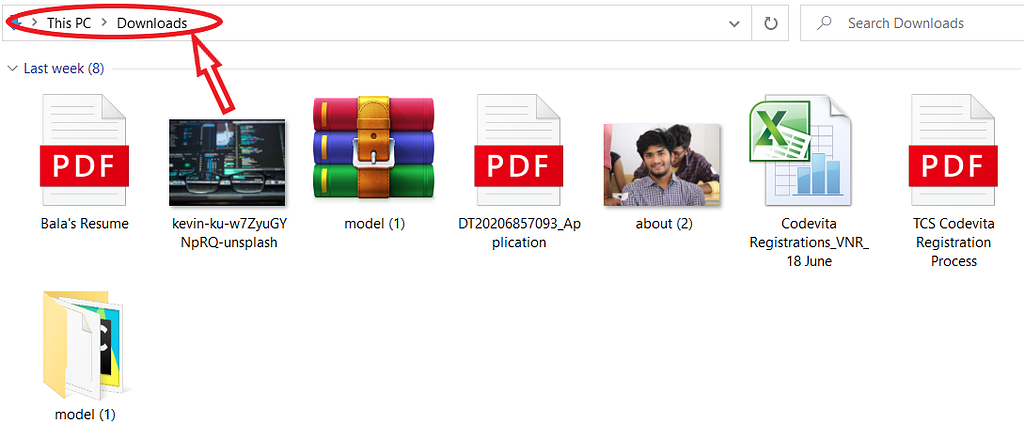
If the image is in the Downloads folder, which you need to get it into the same HTML file(index.html).
Go three levels back till you reach This PC Folder and go into the Downloads folder where you find the about (2) image. Use the command:
../../../Downloads/about (2).jpg
Elements
A tag with its content is called Element. Ex:
tag,
tag etc. Some of the elements do not have content such as , ,
syntax of the HTML element is
content
There are two types of HTML elements:
Block-level Element:
A block-level element always starts with a sperate line that occupies a block area with a complete width of the webpage and required height according to the content and ends with a line break.
Inline Element:
An inline element does not take separate space. The content in the inline Element is continued along with the flow and takes the necessary width without breaking the line.
Units (px,em,%)
Length is used in almost all the CSS properties such as Width, Height, Margin, Border, Padding, etc.
px- pixel (1px = 1/96th of 1inch)
cm-centimeter (1cm = 96px/2.54)
mm-millimeter (1mm = 1/10th of 1cm)
em- Size of the relative element to the font-size of the element
%- Percentage of relative element to the parent element in length
Px, cm, and mm are absolute or static length units — because those sizes do not depend on the size of the viewport. Em & % are dynamic or relative length units because those sizes depend on the size of the viewport.
Preserving white space
This is a technique that preserves the spaces(more than one space), tabs, line breaks, etc. It can be achieved by using a pre tag(
) that is a block of preformatted text, which displays the content as it is including the white spacing.
But, In a paragraph tag(
), it only displays the characters and a single space character without considering the white space in between the content.
Non-breaking space ( ) is an entity in HTML that does not break into a new line, and the webpage treats it as a single space. It can be used to achieve multiple numbers of spaces in the paragraph tag.
Span
The span tag is an inline element that is used to highlight it’s content from others.
Opacity
The opacity describes the transparency of the Element in the range of 0 to 1(invisible to completely visible). By decreasing the value of opacity, the Element is whitened. It is mostly used in the hovering effect of the elements.
opacity levels (invisible -> visible)
Hypertext Reference ( href)
Hypertext reference is an attribute. The name itself says that it refers to the Hypertext. The purpose of href attribute is to provide links from one page to another page. Always an anchor tag < a > contains this attribute. It has two parts. which are,
Anchor text:- The visible text that represents the link and also it is clickable.
URL:- The invisible part which directs you to the other location.
The href attribute refers to different types of URLs.
Absolute URL:- Complete link of the File
Relative URL:- The file’s position based on the current HTML file which you are typing
Section of the webpage:- It refers to other sections on the same webpage using selectors.
Other functions:- It refers to a Telephone number, Mail ID, etc.
Source ( src )
The source is an attribute and also a self-closing tag that defines the path of an external resource such as image, video, audio, iframe, etc. The value of this attribute is an URL that can be the relative or absolute path of the resource.
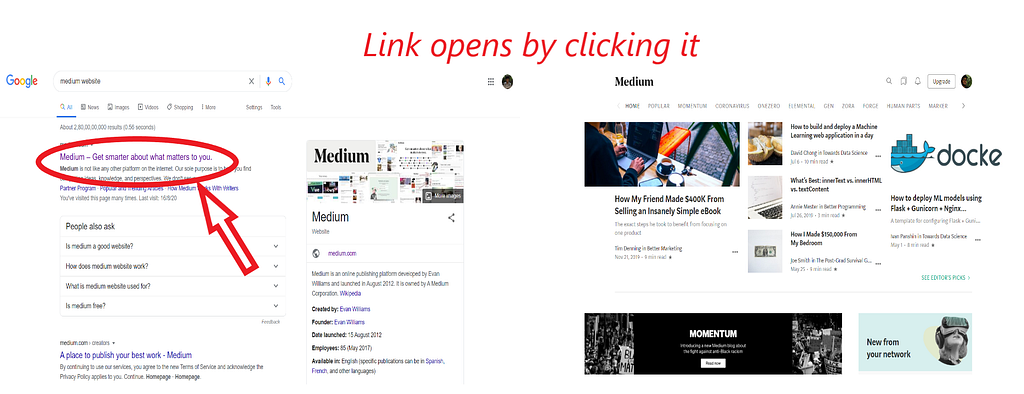
Target
Target is an attribute that determines the location of the external resource to open after clicking the link. The external resource opens based on the value of the target attribute. Those are,
_blank:- opens the linked resource in a new window (or) tab.
_self:- opens the linked resource in the same frame ( default ).
_parent:- opens the linked resource in the parent frame.
_top:- opens the linked resource in the full body of the window.
In the next article, I will write about the remaining basics of CSS and the fundamentals of Bootstrap.
I hope you enjoy the article and correct me if anything is wrong in the article! 🤝🤝🤝
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Towards AI Team
Established in Pittsburgh, Pennsylvania, US — Towards AI Co. is the world’s leading AI and technology publication focused on diversity, equity, and inclusion. We aim to publish unbiased AI and technology-related articles and be an impartial source of information. Read by thought-leaders and decision-makers around the world. We have thousands of contributing writers from university professors, researchers, graduate students, industry experts, and enthusiasts. We receive millions of visits per year, have several thousands of followers across social media, and thousands of subscribers. All of our articles are from their respective authors and may not reflect the views of Towards AI Co., its editors, or its other writers. | Information for authors → https://contribute.towardsai.net | Terms → https://towardsai.net/terms/ | Privacy → https://towardsai.net/privacy/ | Members → https://members.towardsai.net/ | Shop → https://ws.towardsai.net/shop | Is your company interested in working with Towards AI? → https://sponsors.towardsai.net





















")