



Text Augmentation for detecting spear-phishing emails
Last Updated on October 23, 2020 by Editorial Team
Author(s): Edward Ma
Natural Language Processing
Text Augmentation for Detecting Spear-phishing Emails
Text augmentation techniques for phishing email detection
Information security is very important for any organization. Lost money is a minor problem, the serious one is that the enterprise system. However, fraud email and phishing email occupy a small set of data when comparing to normal email. Augmenting fraud and phishing email is a way to tackle this problem.

Therefore, Regina et al. proposed three different approaches to generate synthetic data for model training. As synthetic data is a kind of “fake” data, some low-quality data may hurt model performance. Validations are needed to keep a high-quality synthetic data. Also, there are some assumptions which are:
- Synthetic data should share the same label as the original text. For example, synthetic data should be change label from positive to negative (for binary classifier).
- Synthetic data should not be redundant. In other words, the augmented text should not be almost identical to the original text.


Word Replacement
Abbreviations Replacement
Abbreviations are very common in daily conversation. It allows the speaker and audience can communicate easier. For example, “F/W” and “FW” means “forward”. However, there are some vague scenarios that we need context to interpret the abbreviations. For instance, “PM” can be interpreted as “Project Manager” and “Prime Minister”.
Although this method is easy to understand and implement, the drawback is that it needs to define the conversion or mapping one by one.

Misspellings Replacement
Although auto-complete helps to correct misspellings, typo still exists in email and social media. For example, “bargin” is a typo of “bargain”. Regina et al. mentioned that misspellings are important because:
- Misspellings can convey a sense of urgency
- Misspellings can fool security technologies based on text analysis.

This method helps to tackle potential unseen text in inference time as the model may be trained with those misspellings tokens.
Synonym Replacement
By replacing similar meaning words, it can become a new training for models. Regina et al. used both WordNet and BERT to find synonyms or near-synonyms. For example, “The quick brown fox jumps over the lazy dog.” and “Little quick brown fox jumps over the lazy dog.” have similar meanings. The second sentence is generated by the BERT model.
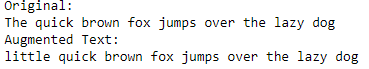
Leveraging WordNet is a typical way to generate synthetic while leveraging BERT to find near-synonyms is a better way to achieve it. Reasons are:
- BERT or contextual word embeddings model can generate near-synonyms words. It introduces more synthetic data and no need to pre-defined a list of synonyms (i.e. WordNet)
- As BERT can be trained for domain-specific knowledge, it can apply to specific domain data.
Take Away
- Generating training data helps to tackle low resource problems. However, bear in mind that you should select appropriate methods to generate synthetic data.
- Some free open source libraries provide an easy way to generate synthetic data. nlpaug is one of the examples that you can generate data by several lines of code.
About Me
I am a Data Scientist in the Bay Area. Focusing on state-of-the-art work in Data Science, Artificial Intelligence, especially in NLP and platform related. Feel free to connect with me on LinkedIn or follow me on Medium or Github.
Extension Reading
- A library of Data Augmentation for NLP (nlpaug)
Reference
- M. Regina, M.Meyer and S. Goutal. Text Data Augmentation: Towards better detection of spear-phishing emails. 2020
Text Augmentation for detecting spear-phishing emails was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

