



REALM: Retrieval-Augmented Language Model Pre-Training
Last Updated on August 17, 2020 by Editorial Team
Author(s): Edward Ma
Natural Language Processing
An Introduction to Retrieval-Augmented Language Model Pre-Training
Since 2018, the transformer-based language model has been proven to achieve good performance in lots of NLP downstream tasks such as Open-domain Question Answer (Open-QA). To achieve better results, models intend to increase model parameters (e.g. more heads, larger dimensions) in order to stored world knowledge in the neural network.
Guu et al. (2020) from Google Research released the state-of-the-art model (Retrieval-Augmented Language Model Pre-Training, aks REALM) which leverages knowledge retriever augmented data from other large corpora such as Wikipedia. Given an extra signal, it helped the model to deliver a better result. In this storied, we will go through how does this model achieves the start-of-the-art result.
REALM Overview
The overall idea is leveraging extra document to provide more signal to the model such that it can predict masked token accurately. The name this approach as a retrieve-then-predict approach. The following diagram shows pre-trianing workflow.
- Given a masked sentence (The [MASK] at the top of the pyramid)
- Feeding a masked sentence to Neural Knowledge Retriever. It will return a document (not necessarily a whole article) that relates to the input.
- Passing both the original sentence and augmented document to Knowledge-Augmented Encoder. It will predict the masked token (pyramidion).
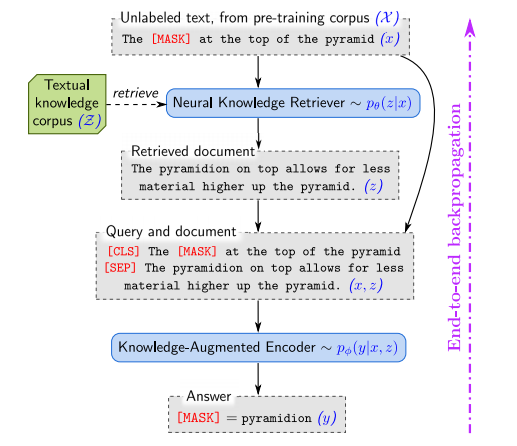
For the fine-tuning stage, it used unmasked sentence instead of a sentence which contains a masked token.
Model Architecture
From the previous overview, you may awared that REALM (Guu et al., 2020) contains two models which are knowledge retriever and knowledge-augmented encoder. We will go through it one by one.
Knowledge Retriever
First of all, the objective of the knowledge retriever is outputting a useful document for the next step. For input, it uses BERT-style to convert the sentence to a token with [CLS] and [SEP] as prefix and prefix respectively. For external documents, it includes both document’s title and body as well. Therefore, we need to concatenate it bye [SEP] which is following BERT-style. You may visit this story for more information about BERT-style format.

After that, it uses a inner product of the vector embeddings (input and document from knowledge corpus). Softmax will be applied on the inner product result in order to pick the most related document.
Knowledge-Augmented Encoder
Same as knowledge retreiver, Guu et al. follows BERT mechanism for training and fine-tuning this encoder.
In the pre-trianing phase, it uses Masked Language Modeling (Devlin et al., 2018). Basically, the training objective is predicting a masked token by unmasked token. You may visit the story for better understanding on MLM mechanism (Devlin et al., 2018)
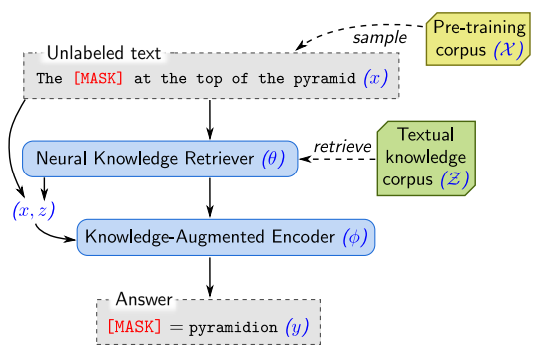
In the Open-QA fine-tuning phase, there is no masked token and Guu et al. assume the answer can be found from document (the output from Knowledge Retriever). It follows BERT-style to construct vector embeddings and passing it to the transformer model.
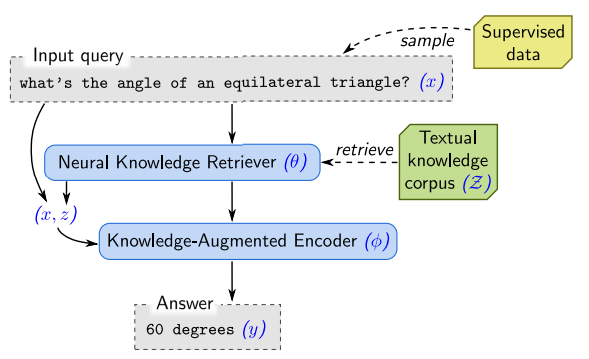
Maximum Inner Product Search (MIPS)
The major challenge of this retrieve-then-predict architecture is selecting a good document from a larger external corpus. Guu et al. proposed to use MIPS to shorter retrieving time.
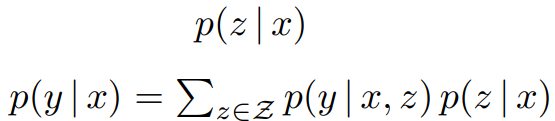
In order to reduce computation time, Guu et al. proposed a 2 step computation. First of all, calculating the possibility of documents from a larger corpus by providing input sentence x. Leveraging MIPS (Ram and Gary, 2012) to pick top k probability documents as inputs for the next step. MIPS uses build a ball tree to disect data points (i.e. vectors) into differnt cluster. Data points will be splitted into cluster and it will belongs to only one cluster (same level of cluster). Therefore, Guu et al. can use much less running time in order to find top k document.
Data Processing in Pre-training
Besides using MIPS to select most relative documents, Guu et al. injects extra information in pre-training to assist model training.
Salient Span
As REALM focus on Open-QA domain, they inteneded to emphasize named entities and dates. Those named entities and dates will be masked as salient spans. To use less effort to figure out named entities, BERT-based tagger is trained in order to identify named eneities and dates.
Null Document
Guu et al. assume that not all masked tokens requrie extra knowledge to predict. Empty document is injected to the top k retrieve documents to similar this situation.
Dropout Trivial Retrievals
It may possible that top k documents include same input sentence. To prevent encoder predict result by focus on unmasked token, this kind of trivial training data will be exlcuded in pre-training phase.
Vector Initialization
Good vectors lead a better result in predicition. For sake of easier, we may use random initialization but it introduces a cold-start problem. Therefore Guu et al. uses Inverse Cloze Task (ICT) for pre-training of pre-trianing. In short, it is a inverse version of masked token predicition. Giving a query (the left hand side of the below figure), the objective is picking a true context from candidates (the right hand side of the below figure)
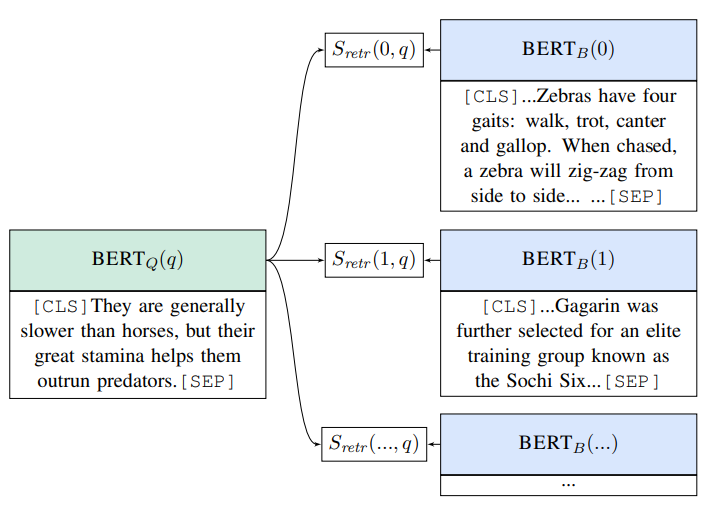
Take Aways
- Salient span for named entities and dates are important. As this model eyes on OpenQA. It is important to let the model to focus on those named entities and dates.
- Selecting the document from a larger corpus is important. The assumption is that the final result exist in extra documents. It is also important to pick top k related doucments.
About Me
I am Data Scientist in Bay Area. Focusing on state-of-the-art in Data Science, Artificial Intelligence , especially in NLP and platform related. You can reach me from Medium Blog, LinkedIn or Github.
Reference
- P.Ram and A. G. Gray. Maximum Inner-Product Search using Tree Data-structures. 2012
- Devlin J., Chang M. W., Lee K. and Toutanova K.. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2018
- K. Guu, K. Lee, Z. Tung, P. Pasupat and M. W. Chang. REALM: Retrieval-Augmented Language Model Pre-Training. 2020
REALM: Retrieval-Augmented Language Model Pre-Training was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

