



Getting Meaning from Text: Self-attention Step-by-step Video
Last Updated on January 6, 2023 by Editorial Team
Author(s): Romain Futrzynski
Natural Language Processing
In October 2019, Google announced that it would process search queries with the BERT model that its researchers have developed. This model can grasp difficult nuances of language: in the search 2019 brazil traveler to the USA need a visa, it is understood that the traveler is Brazilian, and the destination is the USA. From now on, Google says, this search returns the page of the U.S. embassy in Brazil, and no longer shows a page about U.S. citizens traveling to Brazil.
Remarkably, most of the attention mechanism at the core of many transformer models like BERT relies on just a few basic vector operations.
Let’s see how it works.
What’s the matter with context?
If you see the word bank, you might think about a financial institution, the office where your advisor works, the portable battery that charges your phone on the move, or even the edge of a lake or river.
If you’re given more context, as in It’s a pleasant walk by the river bank, you can realize that bank goes well with the river, so it must mean the land next to some water. You could also realize that you can walk by this bank, so it must look like a footpath along the river. The whole sentence adds up to create a mental picture of the bank.
Self-attention seeks to do the very same thing.
Word embedding
A word like bank is called a token when it represents a fundamental piece of text, is commonly encoded as a vector of real, continuous values: the embedding vector.
Determining the values inside the embedding vector of a token is a large part of the heavy lifting in text processing. Thankfully, with hundreds of dimensions available to organize the vocabulary of known tokens, embeddings can be pre-trained to relate numerically in ways that reflect how their tokens relate in natural language.
How to contextualize the embeddings?
The key to the state of the art performance in Natural Language Processing (NLP) is to transform the embeddings to create the right numerical picture from the tokens in any given sentence.
This is what the scaled dot-product self-attention mechanism does elegantly with (mostly) a few operations of linear algebra.
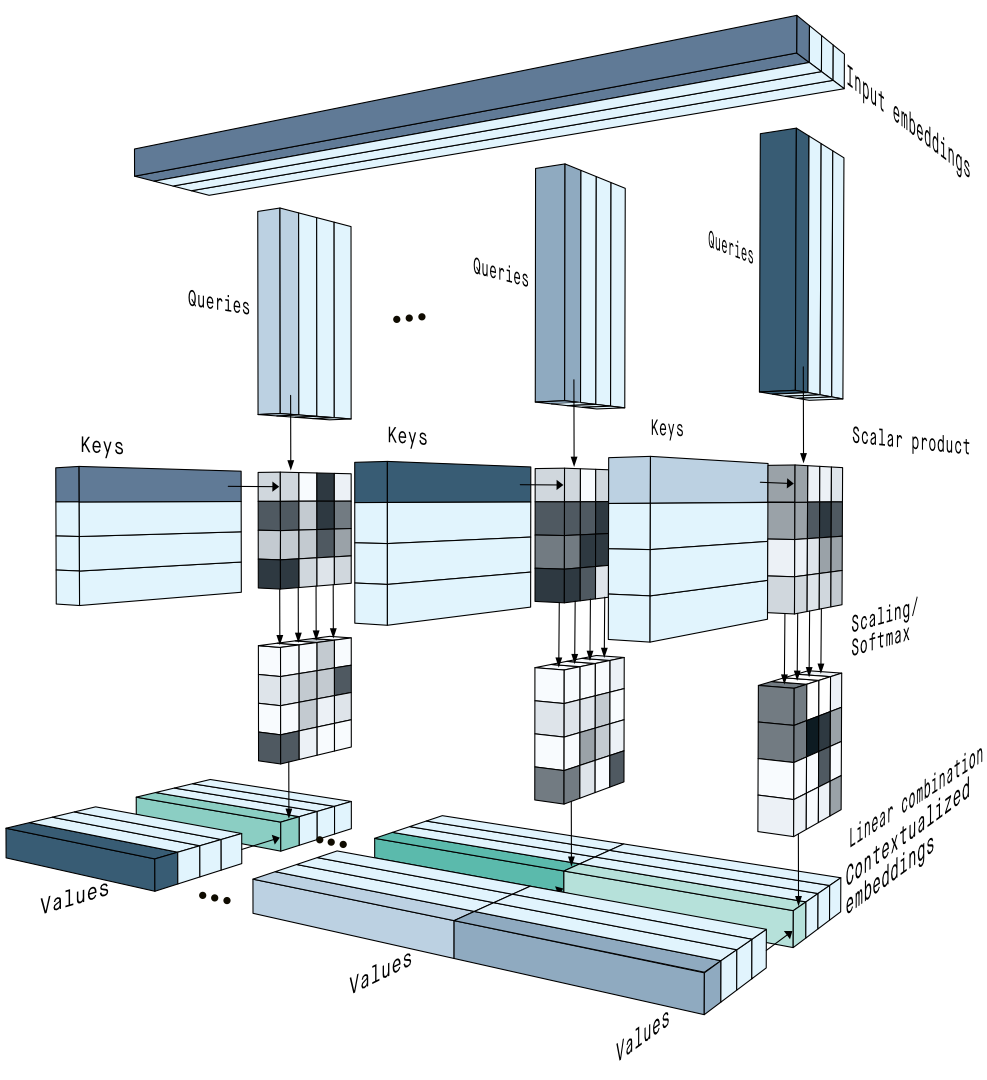
- Token relationships
The words in a sentence sometimes relate to each other, like river and bank, and sometimes they don’t. To determine how related two tokens are, attention simply calculates the scalar product between their embeddings.
We can imagine that the embeddings of bank and river are more similar since they should both encode the aspect of nature so that their scalar product should be higher than if the tokens were completely unrelated. - Keys, queries, and values
Unfortunately, calculating the scalar product directly on the embeddings would simply tend to give higher values when two tokens are the same and give smaller values otherwise. But what grammatical analysis taught us is that important relationships can happen between words that can be completely different: a subject and a verb, a preposition, and a complement, etc.
To have more flexibility, the embeddings go through different linear projections so that one embedding creates a key, a query, and a value vector. The projections allow us to select which components of the embeddings to focus on and to orient them so that the scalar products between the keys and the queries represent the relationships that matter. - Activations
The scalar products between a query and the keys, which give the level of relationship between the query’s token and every other token, are typically scaled down for numerical stability, then passed through a softmax activation function.
The softmax makes large relationships exponentially more significant. Since this operation is non-linear, it also means that self-attention can be re-applied several times to achieve more and more complex transformations, making the process deep learning. - Linear combinations
New contextualized embeddings are created by combining the values corresponding to every input token, in proportions given by the results of the softmax function: if the query of the river token has a strong relationship with the key of the bank token, the value of bank is added in large part to the contextualized embedding for river.
Multi-head attention and BERT
A single sequence of input embeddings can be projected using many different sets of key, query, and value projections in what is called multi-head attention. Each projection set can focus on calculating different types of relationships between the tokens and create specific contextualized embeddings.
The contextualized embeddings coming from different attention heads are simply concatenated together.
Deep learning models for Natural Language Processing typically apply many layers of multi-head attention and mix in extra operations to get robust results.
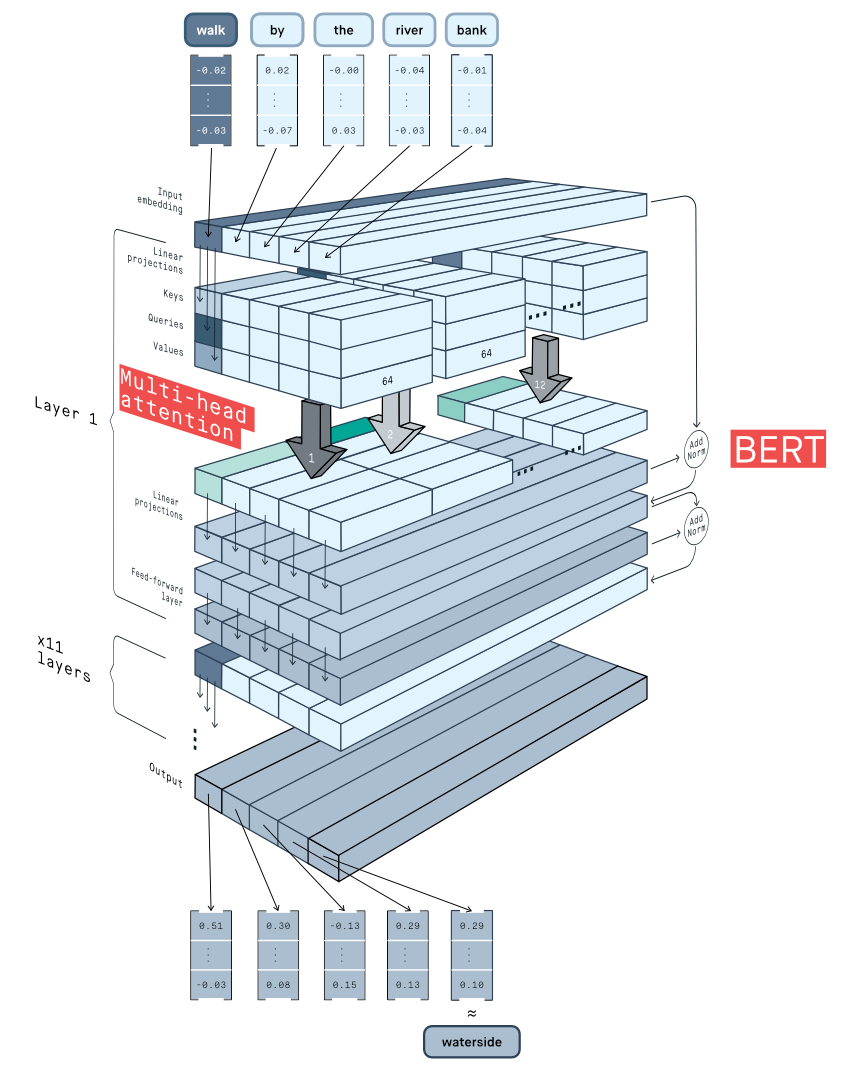
For instance, the BERT Encoder uses the WordPiece embeddings of tokens but always begins by adding them to positional embeddings. This step gives information about the order of the tokens in the input sentence, which self-attention would not consider otherwise.
Additional linear projections, normalization, and feed-forward layers give the whole model more flexibility and stability.
The result is a model that can remove ambiguity from natural text and reduce it to precise values that you can use to automatically search, classify, or even annotate text content.
Read more
Literature
- Attention is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Online resources
- The Illustrated Word2vec
- The illustrated transformer
- Vectoring words (word embeddings)
- Webinar: How NLP and BERT will change the language game
- A year in review: NLP in 2019
- Understanding searches better than ever before
- The Annotated Transformer
- Lines of the official Google attention implementation for BERT
Getting Meaning from Text: Self-attention Step-by-step Video was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

