



Extract the text from long videos with Python
Last Updated on January 6, 2023 by Editorial Team
Last Updated on December 13, 2020 by Editorial Team
Author(s): Eugenia Anello
A simple guide to build a speech recognizer using Google’s API
Speech recognition is an interesting task that allows you to improve the quality of your life. In this neverending Covid period, I need to watch many videos of lessons, and it’s so easy to lose concentration. At the same time, the possibility to have all registrations available on my university’s website made me become a perfectionist, so I would like to take every word in my notes. But it’s costly because it needs a lot of work and steals time.
Luckily, there are already API resources available such as Google, Amazon, IBM, and many others, that offer services that convert audio into text. In this article, I’ll focus only on the Google Speech-to-Text API, which I think it’s the most efficient application to transcribe many videos. I’m going to create a speech recognition model with Python that converts a video file into text format.
Google Speech-to-Text API
Google Speech to text has three types of API requests based on audio content:
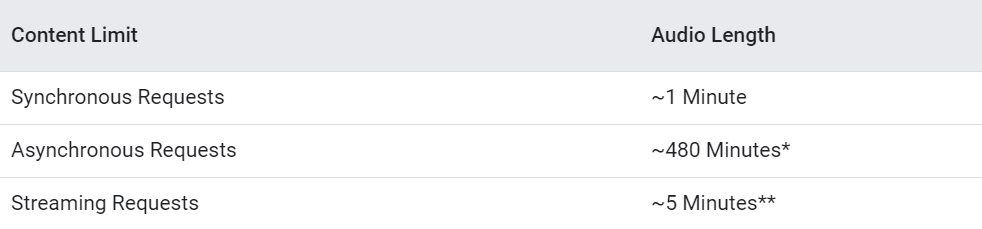
- In Synchronous Requests, the audio file content should be approximately 1 minute. In this type of request, the user does not have to upload the data to Google cloud. I’m going to focus on this type of request.
- In Asynchronous Requests, the audio file should be approximately 480 minutes. In this type of request, the user has to upload their data to Google cloud.
- The Streaming Requests are suitable for streaming data where the user is talking to the microphone directly and needs to get it transcribed. This type of request is apt for chatbots.
The current API usage limits you need to know for Speech-to-Text are:

The table shows that there is a limit of 480 hours of audio per day, while the maximum number of “StreamingRecognize” requests per 60 seconds is 900. Isn’t it amazing to have so many hours to convert audio into text per day? Especially when it’s free! It’s not so obvious if you try other API or standard methods without python.
Step 1: Download video from the website
I downloaded a video from my university’s website with a Chrome extension called Video DownloadHelper. It’s free and very easy to use. Some operations required by Video DownloadHelper cannot be performed from within the browser. In order to make the extension work, I also installed an external app called Companion Application.
Note: Without the Premium status, the video’s download can only be performed 120 minutes after the previous one.
Step 2: Import libraries into Jupiter Notebook
Let’s install the libraries that we’ll use in this program.
SpeechRecognition is a Python library for performing speech recognition with support for Google’s API, while moviepy allows to cut, read, and write all the most common audio and video formats. Moreover, moviepy supports various file format: .ogv, .mp4, .mpeg, .avi, .mov.
Once we installed the libraries, we can import them:
Step 3: Cut video file into chunks of 1 minute and convert each chunk into text format
In my case, the video was in format .mp4 and was 52 minutes long. The variable num_seconds_video contains my video’s number of seconds. After I created a list that will be used to cut the video file into a specific number of chunks, it’s needed for the start and end times in the slices of video. More details about this concept will be explained later.

Moreover, I created an empty dictionary, diz, where the key will be the string “chunk#” and the value will be the text extracted from that chunk. In the for loop, I am going to convert each slice of video into text format.
Note: before running the for iteration, I created a folder “chunks” that contain all the slices of the video and a folder “converted” with all the slices of video converted into wav format. I suggest you do it if you don’t want to be full of files.
- Create a new video file, based on the initial file “ videorl.mp4”, that will be cut between an initial time and an end time(in seconds). For example, the first chunk is between 0 seconds and 60 seconds, and the second chunk is between 58 seconds and 120 seconds, the third chunk will be between the 118 and 180 seconds, and so on until I reach the last chunk between 3058 and 3120 seconds. The chunks overlap by 2 seconds in order to not lose important words. The function used is ffmpeg_extract_subclip(filename, t1, t2, targetname)
- Import the new audio file created in the previous step with the function VideoFileClip(filename)
- Convert mp4 file into wav format, which works better with Google’s API
- Create the Recognizer instance
- Import the audio file with format wav
- Use Google’s Cloud Speech-to-text API to extract the text from the audio file in format wav.
Step 5: Export results into a Text document
As the last task, we’ll create a unique text file, which will contain all the chunks’ texts.
I create a list that only contains the extracted text from each slice of video. After I join each element of the list by a string separator “n”, that is the newline character.
In the end, I created the file, which has all the video’s text.
Congratulations! You obtained the text of your video, or the code is still running. The last case is normal if the file is big. It’s not too fast, but at least you can watch Netflix in the meanwhile. In the end, you will obtain your text transcription. It won’t be perfect, there will be some redundant words because of the overlapping trick of 2 seconds between two chunks, but I think it’s a better solution compared to loose information. I hope you enjoyed this guide and you found it useful. The entire code is in Github.
Extract the text from long videos with Python was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

