


The Difference Between Open Source Models and Commercial AI/ML APIs
Last Updated on November 5, 2023 by Editorial Team
Author(s): Othmane Hamzaoui
Originally published on Towards AI.
In the last few months, you probably came across countless debates about wether you should use open source or commercial APIs for Large Language Models (LLMs). However, this is not particular to LLMs, the question is applied to Machine Learning (ML) in general. It’s a question I have been asked by many customers in the last 5 years working as an ML architect for AWS.
In this blog I will be sharing the approach I took to help ML engineers, decision makers, and ML teams in general pick between open-source ML models or commercial ML APIs.
An approach that doesn’t only look at model performance but also multiple dimensions of analysis (cost, engineering time, ownership, maintenance) that are crucial, or even more important, when using ML in production.
1. Before we get started, let’s get some definitions right!
An Open Source ML model is the combination of a model architecture (design of the model) and weights (the knowledge the model has). You can go on a public hub of models like Hugging Face, Pytorch Hub, Tensorflow Hub and download it.
A Commercial ML API (ex: OpenAI API) is a service accessed through an API endpoint, encapsulating, among other things we’ll discuss shortly, an ML Model. These ML APIs can be found among the services of cloud providers (AWS, Azure, GCP, etc.) or smaller companies specialising in a subset of domains/ML tasks (Mindee, Lettria, Gladia, etc.)
On the surface, they look very similar: you input your data and receive the desired output, such as text generation. But let’s dig deeper to see how they are different.
2. An ML API is not just an “ML model wrapped in an API”
Let’s look at the blocks around the model and what are they used for:
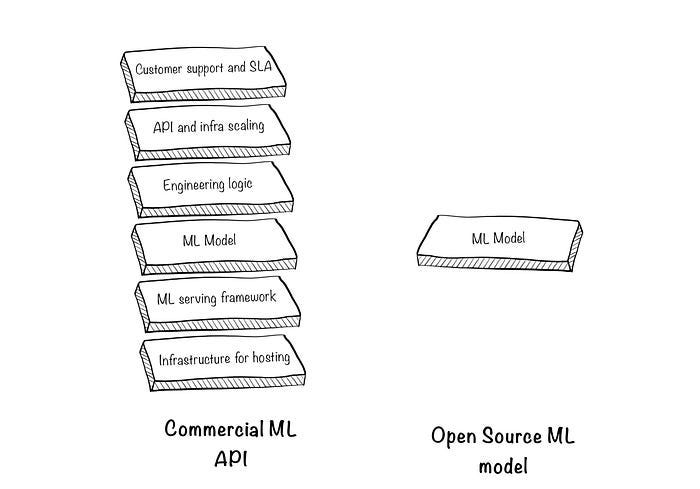
2.1 Infrastructure for hosting: The first thing you do when you pick an ML model is to decide where to run it. If you’re experimenting and it’s a fairly small model, you can run it on your machine. But this not always possible or scalable so you would go through a cloud provider (AWS, GCP, Azure) and rent servers.
2.2 ML serving framework: A model is not just a ‘python function’. To serve predictions in an optimal way, you end up going through a serving framework (TorcheServe, TFServing and more LLM-focused ones here). These frameworks are a necessary evil for achieving optimised latency and handling high concurrency but they do come with a learning curve.
2.3 Engineering logic: This is very case dependent and sometimes can consume a huge amount of time from ML engineers (the devil is in the details).
Let’s take sentiment analysis, for example, a simple use case. Below is an extract from hugging face:

If all you need is generating the sentiment of a few lines of text, then that’s the end of it.
However, if you have, say, 10k documents (different formats: pdf, word, text), and you want to detect their sentiment. You’ll need to :
- First, you run the PDFs through an OCR (Optical character recognition) model.
- Deal with any edge cases (Multiple pages, pages that are not oriented well, etc..)
- Potentially use a different model based on the document type and build an orchestration workflow to get all the data to the right format
- You pass everything to the sentiment analysis model. But you notice you can’t do it sequentially as it will take forever
- You implement a parallelisation pipeline that takes X documents, splits them into multiple processes (maybe multiple servers), run predictions and return the results
- Create tests and and automated processes to ensure stability of the above solution
These components is the devil in the details that’s abstracted by a Commercial ML API. The API provider will hire engineers in their team to do the work above, maintain it, and update it, so you can use something like:
#pseudo-code (not an actual library)
import providerx
#You set an API key so that you can access the provider
providerx.api-key = "123452"
#This will take the data to the provider, do the above steps and
sentiments = providerx.detect_sentiment('./folder-containing-documents/',
document_types=["pdf","word", "txt"]))
2.4 API and infrastructure scaling: This includes two aspects. First, package all the above components into an API to make your model predictions accessible to the rest of your tech stack and product. Second, make sure it can handle concurrency and sudden increases of traffic. To illustrate:
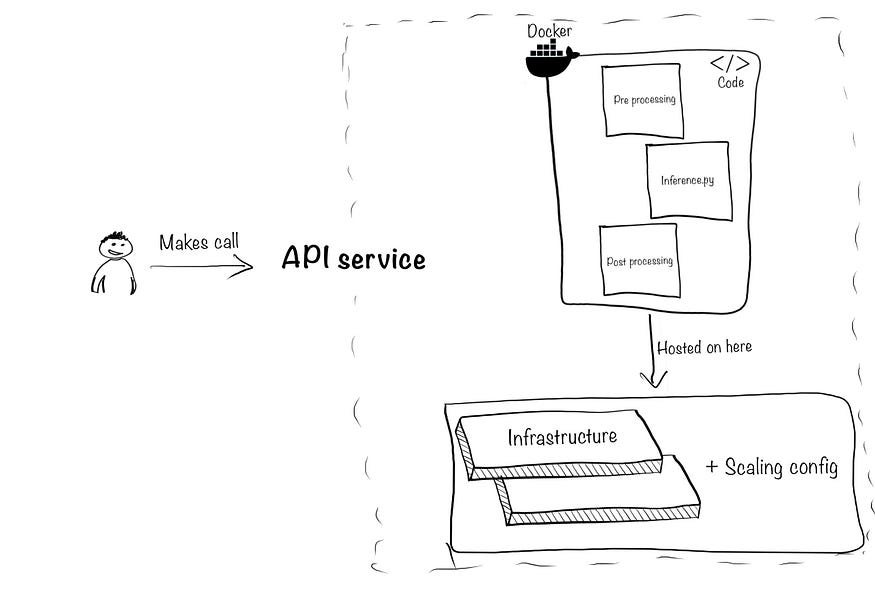
To package your model, you’ll need to combine your inference code (the inference.py script), any other pre/post-processing files, create a docker container, and use something like FastAPI, Amazon API gateway, Apigee API management to create the API.
Then comes scaling, the more users or predictions you make the more infrastructure you will need behind the API you just created. You will start with a small server (~30$/month) and maybe have to scale to (~200$/month) based on the traffic of your users. Then, scale down again when no one is using your API.
There is where things get messy, you’re no longer just making ML predictions you’re creating a small software/service within your team.
Which is fine if it’s your core business (ex: you’re building the recommendation system of your company’s retail website). But it’s completely risky if the project is for a support function (ex: extracting text from operational documents to facilitate data entry in excel)
2.5 Customer support and SLA: Last but not least, when things don’t work as expected or something breaks, who will fix it?
When you build the solution in-house using open-source ML models, you also should account for at least 1 engineer in the team to dedicate time for support and bug fixing.
When you use a Commercial ML API, it’s part of the service to get support under service level agreements (SLAs). An SLA would, for example be, “if our service breaks, we’ll assign an engineer to fix it in under 6 hours”.
Finally, note that just because the Commercial ML API does more things by design doesn’t mean you can’t do them yourself. What matters is that you know that these are the elements you’ll need to build eventually if you want to achieve the same level of service as a Commercial ML API.
3. When comparing costs, use Total Cost of Ownership (TCO)
Most stop at the “ML model is free” or “API calls are too expensive”, let’s see how much of that is true.
Starting with the cost of generating the predictions:
1/Using an open source model: Hosting a ResNet50 (for image classification) on a g4dn.xlarge instance costs $0.526/hour and can achieve ~75 Predictions Per Second for this model (table at the end here). Assume you need to ensure a real-time response to your users, so you keep the instance up 24/7, it will cost you ~$400, and you’ll be able to make ~200 million (75*60*60*24*31) predictions if you can the API nonstop.
2/Using the Amazon Rekognition API: It will cost you $0.00025 per prediction, and if you want to achieve 200 million predictions in a month, that’s a whopping $50, 000
So clearly, you should go for option 1 right? Well, it depends on how many calls you’re making a month:
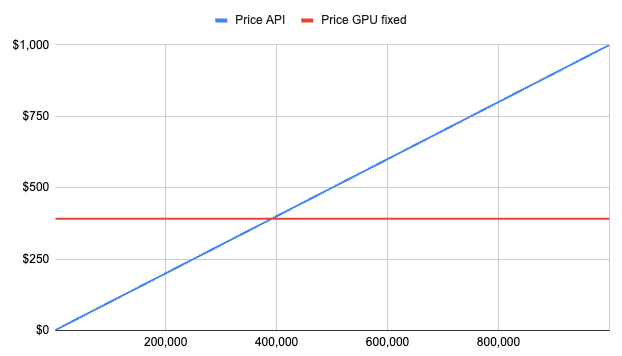
Note that the graph doesn’t take into account “bursts” in traffic. The more users you have calling your ML models at once, the more servers you’ll need to spin up to handle the load. So, the price of GPU is not completely fixed, but for simplification purposes, let’s focus on steady workloads and conclude the following:
-> If you’re making less than 400,000 predictions a month, you’re better off paying for Commercial ML API. If your volume is higher than that, each month, yes, go for the open-source version and host it yourself.
Note: A similar study on LLMs has been done here.
—
So far, we have only looked at how much it costs to make predictions. However, when looking at cost, you should look at TCO (Total Cost of Ownership). It’s basically answering the question:
If we include the model, infrastructure, engineering time spent, the operational and maintenance efforts, how much would it cost me?
The engineering logic, the configuration of the frameworks, the scalability of your infrastructure, maintenance and support etc. You pay for these things with human capital. It’s the hardest part to estimate because it depends on what ML task you want to achieve, what level of service you want to provide, and what resources you have.
Assuming you hire two people, one with expertise in ML and another in backend/cloud. The average annual salary for Software Engineers is $120k in US (and 60k in Europe) so that’s a total of $240k (~120k in Europe) minimum* (indeed, glassdoor)
In short the Commercial ML API hires engineers, rents infrastructure and through the power of mutualization of their service they are able to “rent” bits and pieces of their infrastructure and engineering capacity through their API so you don’t have to take big commitments on your side.
4. Fine-tuning
“Yes, but I like to fine-tune my models to my data and my use case”. You can do that with both open-source models and commercial ML APIs. The difference is in terms of the degree of customization and the effort it will take you to customize.
Keep in mind that in both cases, the hardest part is getting the data and making it ready to be ingested for fine-tuning.
For open-source models, you definitely have more flexibility. As you have access to the model, you can go deep and even change the model’s architecture. However, this requires you to have someone with ML knowledge, not only to understand how to properly fine-tune the model but also the architecture of the model and its parameters.
For Commercial ML APIs, you’ll get less flexibility but also less work on your side. The best example of a fine-tuning commercial API is the recently released GPT-3.5 fine-tuning. Other examples are custom labels with Amazon Rekognition, which is very useful if you use specific images or Mindee’s OCR fine-tuning API for custom documents.
The Commercial ML API will ask you to provide the data and the labels through their API/Interface, and they take care of the rest: Training, optimizing and deploying a custom model for you with the same stack as the generalist models.
Start with the fine-tuning APIs, feed in the inputs and outputs you have, if the performance is not great first reach out to the provider. They can assess your use case and tell you if it’s feasible. If not then consider hiring an ML specialist who can go deep in the details of the Open Source models and adapt them.
5. Security & Privacy
Security is about how secure your system is against attacks. Unless you have security experts on your team, the harsh truth is that you’re more likely to build less secure systems than those of a Commercial ML API. They have a dedicated security team, implement industry standards, and run continuous checks on their systems.
Unless you do the same you can’t tag Open Source and self-hosted Models as “secure” just because you’re the one managing them.
Privacy, on the other hand, is different; once your data goes out of your data center/servers and through an API, you take the risk of your data being read by someone else besides you. When this is tied to regulatory rules (i.e.: If your company data goes through service x then you need to do y) then it’s just a matter of respecting those rules and jumping through approval hoops.
When privacy is related to a concern of “the provider will look at my data”, keep in my mind that their business is selling you API calls, and they can’t do that if they can’t be trusted. Check out who’s providing the API before you use it, who they are exactly, and what are their privacy rules. Established vendors are clear about what they do with your data, encrypt your data in transit and at rest and sometimes even propose options to opt out of the use of your data for training purposes etc.
Summary and takeaways
Below is a table that provides guidelines on when to choose what
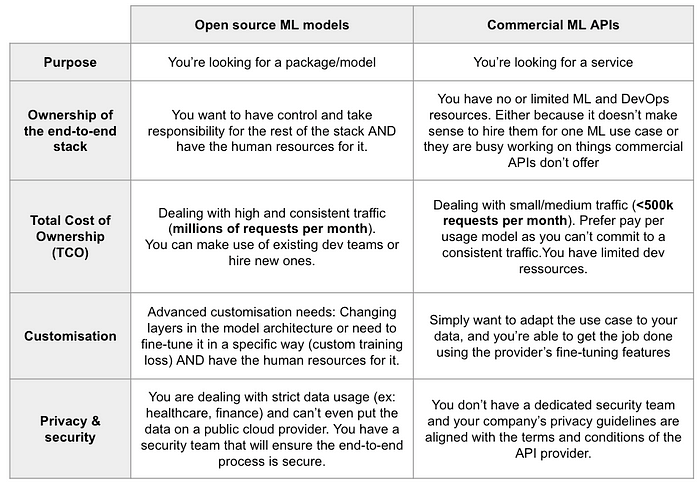
Most importantly keep in mind that both Open Source ML models and Commercial ML APIs are needed, they just serve different purposes. Which one is better depends on the criteria we mentioned above and your situation. A summary of recommendations:
- The higher the monthly volume of predictions (>~400–500k) the more chances you’re better off using Open Source Models and hosting them.
- Always try the Commercial ML APIs first. If they get the job done and the price fits your budget, stick to that. If the price is slightly higher, consider how much it will cost you to hire people to build and maintain a similar service.
- Try fine-tuning features of the Commercial ML APIs if the results are bad, work on your data, and/or contact the provider for help. If it’s still bad, consider investing in an ML specialist, and if the ML performance is great then invest in an ML engineer/DevOps to help put the model in production.
—
Thanks for reading! If we haven’t met, I’m Othmane and I spent 5 years at AWS as an ML engineer, helping over 30 companies embed ML in their products/businesses.
If you have any questions, don’t hesitate to reach out over Twitter (@OHamzaoui1) or Linkedin (hamzaouiothmane).
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts




Popular posts

 for 2021")



Updates

Recent Posts


