



On Common Split for Training, Validation, and Test Sets in Machine Learning
Last Updated on July 25, 2023 by Editorial Team
Author(s): Barak Or, PhD
Originally published on Towards AI.
In this post, we deal with determining the appropriate ratio for training, validation, and test sets in small and large databases
Background
Splitting a dataset into training, validation, and test sets is a crucial step in building a machine learning model, as it allows for the model to be trained on one set, tuned on another, and evaluated on a final set. Larger datasets benefit from more portion of training data while shuffling and ensuring normal distribution to avoid biases. During this process, we need to split the entire dataset to succeed with our task.
Common Split for Training, Validation, and Test Sets
When splitting a dataset into training, validation, and test sets, it’s not just about the size of the dataset but also about the statistical distribution of the data.
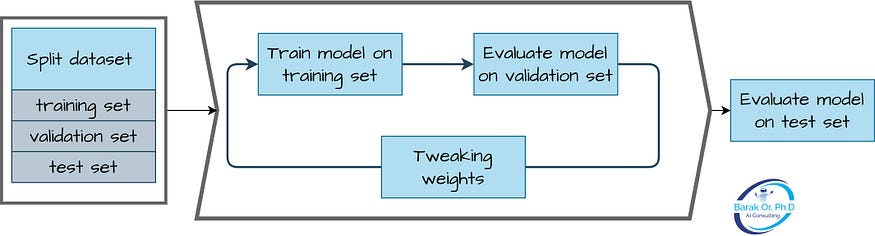
The purpose of splitting the data into these sets is to train the model on the training set, tune the hyperparameters on the validation set, and evaluate the performance of the final model on the test set. If the training, validation, and test sets have different statistical distributions, the model may perform well on the training and validation sets but poorly on the test set, which is known as overfitting.
Therefore, it’s important to ensure that the training, validation, and test sets have similar statistical distributions. This means that the proportion of samples from each class should be roughly the same in all sets. If the dataset is imbalanced, you may need to use techniques such as stratified sampling to ensure that all sets have a proportional representation of each class.
Another consideration is ensuring that the samples in the training and test sets are randomly selected. This helps to avoid any systematic bias that may be present in the dataset, such as the ordering of the samples or the location of the samples within the dataset.
Determining the appropriate size for training, validation, and test sets depends on various factors, such as dataset size, complexity, number of features, and problem nature. Generally, larger datasets benefit from larger training sets as it helps the model understand complex relationships between features and the target variable. However, validation and test set sizes also matter, as they assess the model’s performance and generalization ability. Typically, a common practice is to divide the dataset into 60–80% training, 10–20% validation, and 10–20% test sets.
Consideration of Training/validation/test sets
The appropriate size for training, validation, and test sets in machine learning model development is a crucial factor that is often overlooked. The commonly used split of 70/15/15 or even 80/10/10 may not be the best approach for larger databases, and the size of these sets should be determined based on the size of the dataset itself.
For example, in a big dataset with 1,000,000 samples, a division of 98/1/1 may be sufficient for testing, with the majority of the data used for training. However, it is crucial to shuffle the dataset and ensure that it has a normal distribution prior to splitting it into these sets.
During the training phase of an ML model, the goal is to achieve a level of generalization that allows the model to perform well on new, unseen data (“Generalization Capability”). In order to test whether this generalization has been achieved, we need a set of data that is statistically similar to the training data. This means that the distribution of the data in the test set should be the same as that in the training set.
The question then arises, how many examples do we need in the test set to accurately represent the distribution of the data? This depends on various factors, such as the size of the dataset and the effectiveness of techniques such as shuffling and normalization. In general, a smaller test set may be sufficient if it is properly selected and represents the same statistical distribution as the training set. However, it is important to ensure that the test set is large enough to provide a meaningful evaluation of the model’s generalization capabilities.
The reasons behind this approach are twofold. Firstly, large datasets can benefit from having a larger proportion of the data used for training, as this can help the model learn more complex relationships between features and the target variable. Secondly, shuffling the dataset and ensuring a normal distribution prior to splitting can help to prevent biases in the resulting sets, which can negatively impact model accuracy.
By understanding the importance of dataset size and the benefits of shuffling and normal distribution, one can make informed decisions about the size of their training, validation, and test sets in machine learning model development.

Small dataset
The rule of 80/10/10 may not be appropriate for small datasets as it can result in insufficient data for the model to learn from. In such scenarios, cross-validation is a commonly used technique.
Cross-validation involves partitioning the dataset into k equal subsets, or “folds.” Of these, k-1 subsets are used for training the model, while the remaining subset is reserved for testing. This process is repeated k times, with each fold being used as the test set once. The results from each fold are then averaged to provide a final estimate of the model’s performance.
One advantage of cross-validation is that it helps to ensure that the model is not overfitting to the training data. As overfitting occurs when a model is too complex and fits the training data too closely, it eventually results in poor performance on new, unseen data. Here, cross-validation addresses this issue by evaluating the model’s performance on multiple subsets of the data, which can provide a more reliable estimate of how well the model will generalize to new data.
However, one disadvantage of cross-validation is that it can be computationally expensive, particularly for complex models. In addition, the choice of the number of folds can have an impact on the results obtained, with larger values of k generally providing a more accurate estimate of the model’s performance but increasing the computational cost.
Summary
When working with a very large database or a very small database, determining the optimal size for the training, validation, and test sets requires careful consideration. The amount of available data, the complexity of the problem, and the desired level of model accuracy are all important factors that come into play. However, above all else, it is crucial to ensure that the model is capable of generalizing effectively to new data. There is no one-size-fits-all approach to determining the size of these sets in a large database.
Thanks for reading!
More Resources
[1] How (and why) to create a good validation set: https://www.fast.ai/posts/2017-11-13-validation-sets.html
[2] What is the Difference Between Test and Validation Datasets?
https://machinelearningmastery.com/difference-test-validation-datasets/
About the Author
Barak Or is an Entrepreneur and AI & navigation expert; Ex-Qualcomm. Barak graduated with a Ph.D. degree in the fields of Machine Learning and Sensor Fusion. He holds M.Sc. and B.Sc. in Aerospace Engineering and B.A. in Economics & Management from the Technion. Winner of Gemunder prize. Author of several papers and patents. He is the founder and CEO of ALMA Tech. LTD, an Artificial Intelligence & Advanced Sensor Fusion company.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



