



MuZero: Master Board and Atari Games with The Successor of AlphaZero
Last Updated on June 8, 2020 by Editorial Team
Author(s): Sherwin Chen
Reinforcement Learning
A gentle introduction to MuZero
Introduction
Although model-free reinforcement learning algorithms have shown great potential in solving many challenging tasks, such as StarCraft and Dota, they are still far from state of the art in domains that requires precision and sophisticated lookahead, such as chess and Go. On the other hand, planning algorithms can master chess and Go, but they usually rely on the knowledge of the environment’s dynamics, preventing their application to real-world domains like robotics. We discuss a model-based RL agent named MuZero, the successor of AlphaZero, also proposed by Silver et al. at DeepMind, that achieves state-of-the-art performance in Atari 2600 while maintaining superhuman performance in precision planning tasks, such as chess and Go.
Similar to its predecessor AlphaZero, MuZero uses Monte Carlo Tree Search(MCTS) to decide each step. The difference is that MuZero does not require knowledge of the environment’s dynamics. Instead, it learns a dynamics model on the latent space, enabling it to be applied to situations where the dynamics are unknown.
This post consists of three parts: Firstly, we talk about how the agent decides at each step. Then we discuss the networks used in MuZero and how these networks are trained. Lastly, we present several interesting experimental results.
Inference

As shown in Figure 1, MuZero creates a search tree at the inference time, where every node is associated with an internal state s. For each action a from s there is an edge (s, a) that stores a set of statistics {N(s, a), Q(s, a), P(s, a), R(s, a), S(s, a)}, respectively representing visit counts N, mean action value Q, policy P, reward R, and state transition S. The start state s⁰ is obtained through a representation function h, which encodes the input planes into an initial state s⁰.
The search repeats the following three stages for several simulations:
Selection: Each simulation starts from the internal root state s⁰ and finishes when the simulation reaches a leaf node s^l. For each step k=1,…,l in the search tree, an action a^k is selected to maximize over a variant of upper confidence bound(UCB), the same one defined in AlphaZero

where c_1 and c_2 control the influence of the prior policy P relative to the action value Q as nodes are visited more often.
Expansion: At the final time-step l, the reward and next state are computed by the dynamics function, r^l, s^l=g(s^{l-1}, a^l), and stored in the corresponding tables R(s^{l-1}, a^l)=r^l, S(s^{l-1},a^l)=s^l. Here, we represent the dynamics function deterministically; the extension to stochastic transitions is still left for future work. A new node, corresponding to state s^l, is added to the search tree, and the policy and value are computed by the prediction function, p^l,v^l=f(s^l). Each edge (s^l, a) from the newly expanded node is initialized to {N(s^l, a)=0, Q(s^l, a)=0, P(s^l, a)=p^l}. Note that the search algorithm makes at most one call to the dynamics function g and prediction function f respectively per simulation, and the statistics of edges to the newly expanded node are not yet updated at this point. As a concrete example, consider Figure 1A. At time step 3, MCTS expands s³ and compute g(s², a³) and f(s³) for bookkeeping).
Backup: MuZero generalizes backup to the case where the environment can emit intermediate rewards and have a discount 𝛾 less than (we still use 𝛾=1 for board games where no intermediate reward is given). For internal node k=l…0, we form an l-k-step estimate of the cumulative discounted reward, bootstrapping from the value function v^l:
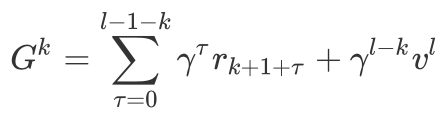
For k=l…0, we also update the statistics for each edge in the path accordingly:
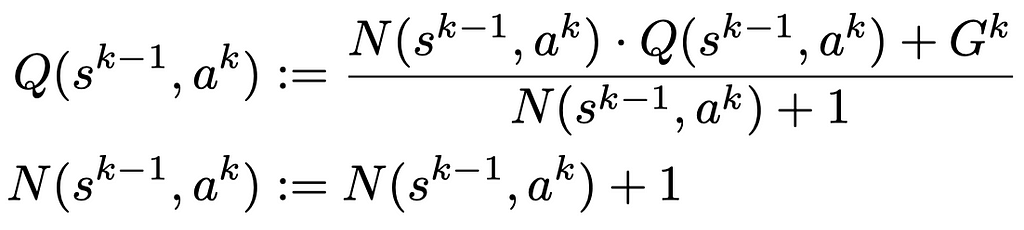
In two-player zero-sum games, the value functions are assumed to be bounded within [0, 1]. This choice allows us to combine value estimates with probabilities using the pUCT rule (Equation 1). However, since in many environments, the value is unbounded, it is necessary to adjust the pUCT rule. To avoid environment-specific knowledge, we replace the Q value in Equation 1 with a normalized \bar Q value computed as follows:
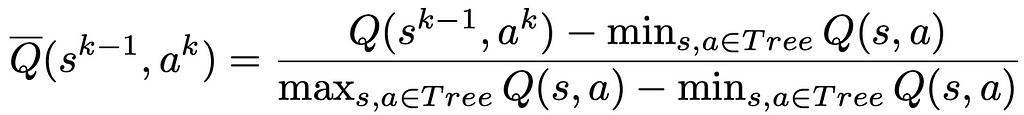
Training

MuZero consists of 3 models: a representation model mapping observations o_1, …, o_t, to the root state s⁰, a dynamics model mapping the state s^{k-1} and action a^k to the next state s^k and reward r^k, and an actor-critic model that takes in state s^k and produces policy p^k and value estimate v^k. All of these are convolutional neural networks.
During training, transitions sequences of length K=5 are selected by sampling a state from the replay buffer, then unrolling K steps from that state. For board games, states are sampled uniformly, whereas, in Atari, samples are drawn in the same way as PER, with priority |𝜈-z|, where 𝜈 is the search value and z the observed n-step return. The network is also unrolled for K steps so that we can compute the corresponding reward, value, and policy losses, as shown in Figure S2.
The training process also introduces several subtleties:
- We scale the loss of each head by 1/K to ensure the total gradient has a smaller magnitude irrespective of how many steps we unroll for
- We scale the gradient at the start of the dynamics function by 1/2. This ensures that the total gradient applied to the dynamics function stays constant.
- We scale the hidden state to [0, 1], the same range as the action input. This improves the learning process and bound the activations.
- For Atari, reward and value are represented by categorical distributions and therefore trained with cross-entropy loss. To reduce the potential unlimited scale of the value function, we further scale the value prediction using the inverse function from Ape-X DQfD.
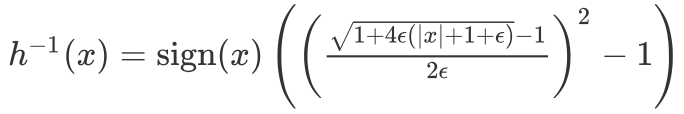
Interesting Experimental Results

Figure 2 shows the performance throughout training in each game. MuZero slightly exceeds the performance of AlphaGo, despite using less computation per node in the search tree (16 residual blocks per evaluation in MuZero compared to 20 blocks in AlphaGo). This suggests that MuZero may be caching its computation in the dynamics model to gain a deeper understanding of the position.
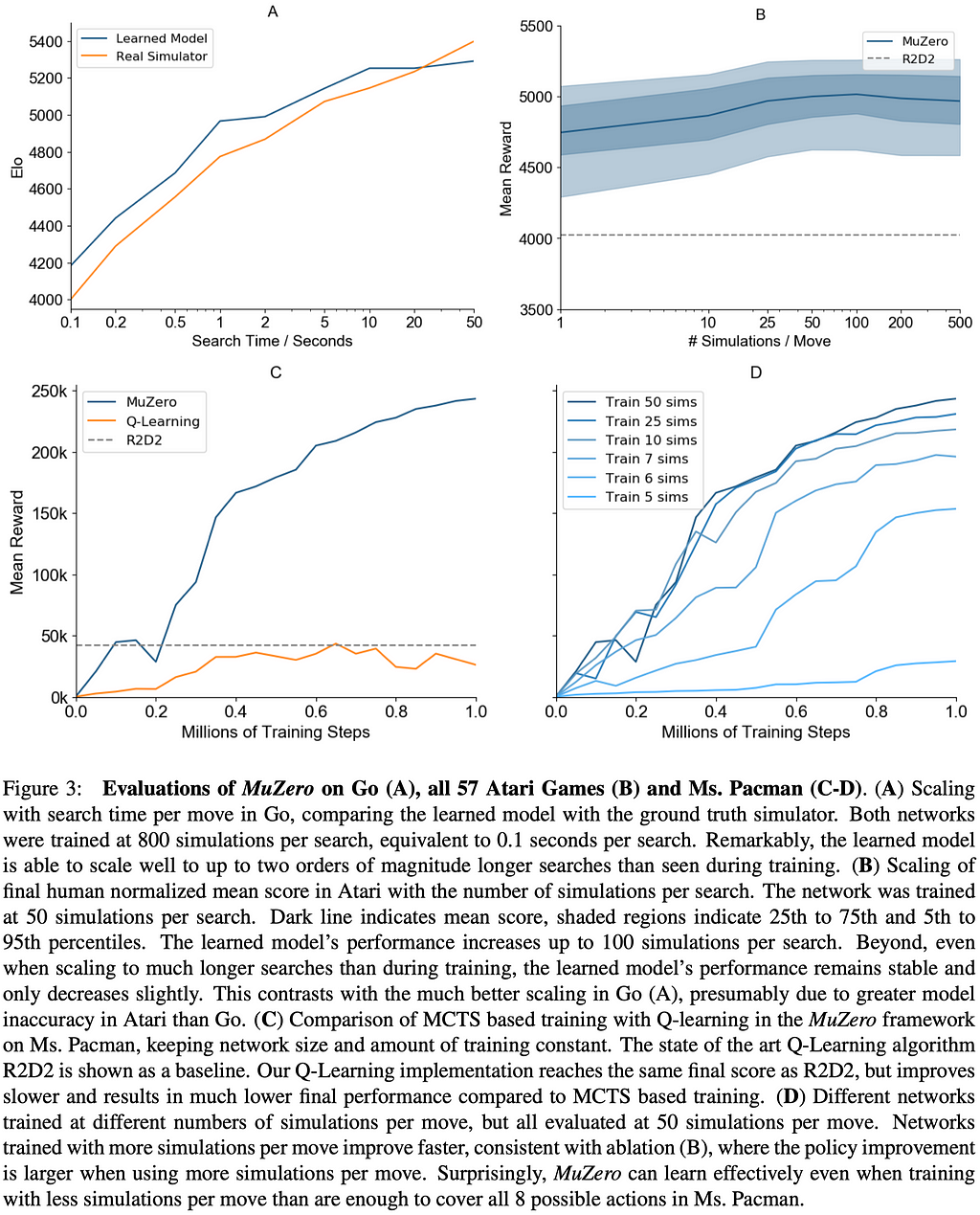
Figure 3 shows several experiments on the scalability of the planning of MuZero:
- Figure 3A shows MuZero matches the performance of a perfect model, even when doing much deeper searches (up to 10s thinking time) than those from which the model was trained (around 0.1s thinking time).
- Figure 3B shows that improvements in Atari due to planning are less marked than in board games, perhaps because of greater model inaccuracy; performance improves slightly with search time. On the other hand, even a single simulation — i.e., when selecting moves solely according to the learned policy — performs well, suggesting that, by the end of the training, the raw policy has learned to internalize the benefits of search.
- Figure 3C shows that even with the same network size and training steps, MuZero performs much better than Q-learning, suggesting that the search-based policy improvement step of MuZero provides a stronger learning signal than the high bias, high variance targets used by Q-learning. However, they did not analyze the effect of the categorical representation of the reward and value predictions. This may contribute to the performance of MuZero as it’s known that cross-entropy loss provides a stronger learning signal than MSE.
- Figure 3D shows that the number of simulation plays an important role during training. But it’s plateaued potentially because of greater model inaccuracy, as mentioned before.
References
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, David Silver. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
MuZero: Master Board and Atari Games with The Successor of AlphaZero was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")