Logo:
Logo:  Areas Served:
Areas Served: Let’s Learn: Neural Nets #2 — Nodes
Last Updated on July 26, 2023 by Editorial Team
Author(s): Bradley Stephen Shaw
Originally published on Towards AI.
A beginner’s guide to nodes and neurons in neural nets.
Following the Feyman approach to learning about neural networks, I’ve identified that I know a little bit about nodes, weights and biases as they relate to neural nets, but not a whole lot. So I’m here to change that.
If you’re interested in what I’m doing — or are on a similar path yourself — take a look at my journey¹.
Nodes
I think I have a basic understanding of nodes and layers, but below is a summary of additional research that I’ve done and my thoughts on it.
Let’s start with what I think I know about nodes:
- Nodes are the building blocks of neural nets.
- Oftentimes the networks if formed of tons of the little things.
- Nodes are organized into layers.
- Nodes can be connected in some way — i.e., information flows from one node to another (and potentially back around again) as it goes through the network.
Let’s see what else I can find out about them. First up — can we nail down a definition for a node?
What is a node?
From “Explained: Neural networks” published in MIT News²:
… a neural net consists of thousands or even millions of simple processing nodes that are densely interconnected. Most of today’s neural nets are organized into layers of nodes, and they’re “feed-forward,” meaning that data moves through them in only one direction. An individual node might be connected to several nodes in the layer beneath it, from which it receives data, and several nodes in the layer above it, to which it sends data.
Here’s a different explanation, from freeCodeCamp³:
A neuron, in the context of Neural Networks, is a fancy name that smart-alecky people use when they are too fancy to say function. A function, in the context of mathematics and computer science, is a fancy name for something that takes some input, applies some logic, and outputs the result.³
And a third, because round numbers… this time from Machine Learning Mastery⁴ (I love this site!):
A node, also called a neuron or Perceptron, is a computational unit that has one or more weighted input connections, a transfer function that combines the inputs in some way, and an output connection.
Nodes are then organized into layers to comprise a network.
Input… function… output. Right.
What kind of input does a node receive?
From the AI Wiki⁵:
Weights and biases (commonly referred to as w and b) are the learnable parameters of a some machine learning models, including neural networks.
Neurons are the basic units of a neural network. In an ANN, each neuron in a layer is connected to some or all of the neurons in the next layer. When the inputs are transmitted between neurons, the weights are applied to the inputs along with the bias.
I’ve heard of weights and biases, but I feel like I need to look at them in more detail. So I’ll leave it there for now and come back to it later.
What about this “transfer function”?
Jason Brownlee at Machine Learning Mastery⁶:
An activation function in a neural network defines how the weighted sum of the input is transformed into an output from a node or nodes in a layer of the network.
Sometimes the activation function is called a “transfer function.” If the output range of the activation function is limited, then it may be called a “squashing function.” Many activation functions are nonlinear and may be referred to as the “non-linearity” in the layer or the network design.
Again, my spidey-senses are tingling… A quick Google search makes me think activation functions need an article of their own.
And a node’s output?
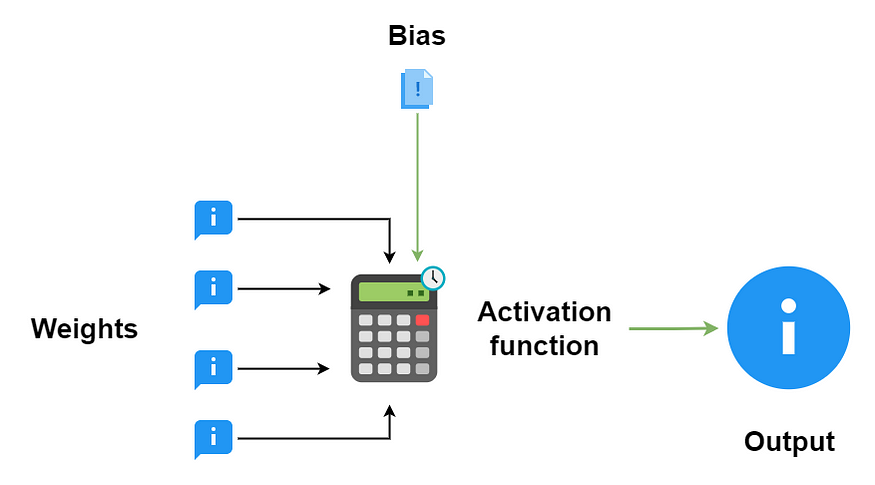
We know from the articles that the output of the node is simply (ha!) the result of the node’s activation function working on the weights and bias input into the node.
Since I know that the nodes are organized into layers, I would expect that this output either flows into another node, or into some sort of “final” activation function (if the node is in the output layer).
Let’s draw a picture!
Wrap up
- Nodes are the building blocks of neural networks. There are oftentimes hundreds (or even thousands) of nodes in a neural network.
- A node can be thought of quite simply as a function, where input flows into the node, the function rule is applied to the input, and the result flows out of the node.
- Two types of input flow into the node: an array and a constant (“weights” and “bias” respectively).
- A node’s output is the result of the node’s activation function working on the weights and biases flowing into that particular node. A node’s output can flow into another node or into another activation function (if the node is in the output layer).
Next up: a dive into activation functions.
References
- Let’s Learn: Neural Nets #1. A step-by-step chronicle of me learning… U+007C by Bradley Stephen Shaw U+007C Jan, 2022 U+007C Medium
- Explained: Neural networks U+007C MIT News U+007C Massachusetts Institute of Technology
- Neural Networks for Dummies: a quick intro to this fascinating field (freecodecamp.org)
- How to Configure the Number of Layers and Nodes in a Neural Network (machinelearningmastery.com)
- Weights and Biases — AI Wiki (paperspace.com)
- How to Choose an Activation Function for Deep Learning (machinelearningmastery.com)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts