
 Logo:
Logo:  Areas Served:
Areas Served: 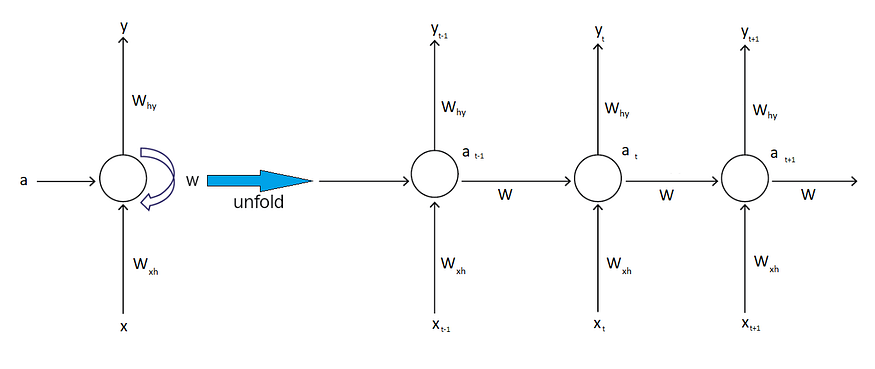
Introduction to the Architecture of Recurrent Neural Networks (RNNs)
Last Updated on July 25, 2023 by Editorial Team
Author(s): Manish Nayak
Originally published on Towards AI.
RNNs Architecture U+007C Towards AI
Introduction
In my previous post, I explain different ways of representing text as a vector. you can read about Word2Vec, Doc2Vec and you can also find a jupyter notebook for Word2Vec model using fastText. We can perform sentiment classification on top of those representations using a dense layer. you can find a jupyter notebook for the sentiment classification using a dense layer on GitHub.
There is one issue with this approach, the dense layer doesn’t consider the order of the words. For example, consider these two sentences
- Bob is stronger than Tom.
- Tom is stronger than Bob.
Here
- In both sentences, words are exactly the same.
- But the order of the words is different.
- The vector representation of the words will be the same in both sentences.
We know that both sentences are different and they should not be represented the same by mathematical structure.
Recurrent Neural Networks (RNNs) is useful for such kind of scenarios where the order of the word needs to be considered.
You can think of RNNs as a mechanism to hold memory — where the memory is contained within the hidden layer.
RNN Architecture
The network on the right is unrolled diagram of the network on the left where
- Wxh: is weights for the connection of the input layer to the hidden layer.
- W: is weights for the connection of the hidden layer to the hidden layer.
- Why: are the weights for the connection of the hidden-layer-to-output-layer layer.
- a: is the activation of the layer.
The recurrent neural network scans through the data from left to right.
The parameters it uses for each time step are shared. In the above diagram, parameters Wxh, Why and W are the same for each time step.
In RNN making a prediction at time t, it uses not only input “xt” at time t but also information from previous input at time t-1 through activation parameter “a” and weights “W” which passes from previously hidden layer to current hidden layer.
Note: There is one weakness of this RNN is that it only uses the information that is earlier in the sequence to make a prediction. So the prediction of RNN at a certain time uses inputs or uses information from the earlier in the sequence but not information later in the sequence.
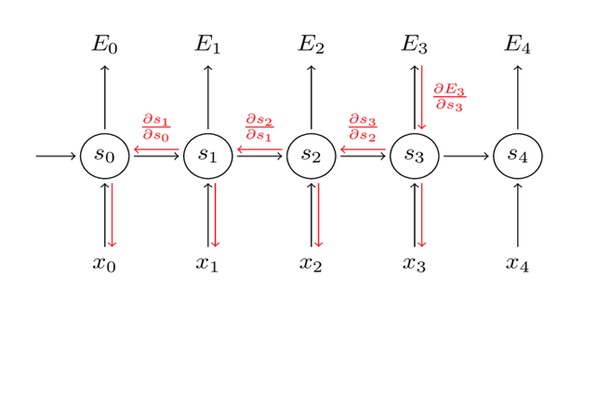
Backpropagation through time
The error is back propagated from the last time step to the first time step. The error at each time step is calculated and this allows us to update the weights. The below diagram is a visualization of the backpropagation through time.
Architecture And Their Use Cases
There can be a different architecture of RNN. Some of the possible ways are as follows.
- One-To-One: This is a standard generic neural network, we don’t need an RNN for this. This neural network is used for fixed sized input to fixed sized output for example image classification.

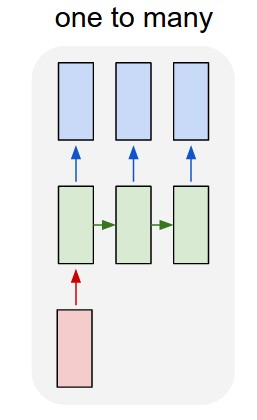
- One-To-Many: Image captioning, for image captioning Input, is an image and output is the caption of the image. Music generation, for music generation one input note is feed to the network and it predicts the next note in the sequence.
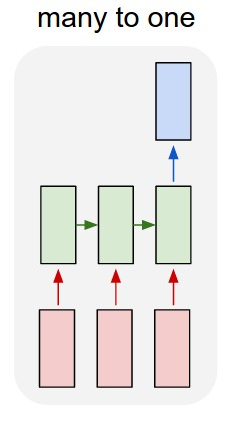
- Many-To-One: Input is a movie’s review (multiple words in input) and output is sentiment associated with the review.
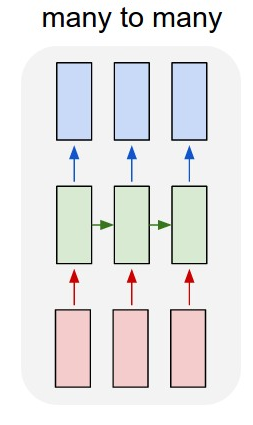
- Many-To-Many: Machine Translation of a sentence in one language to a sentence in another language. speech recognition.

- Many-To-Many: Name Entity Recognition where the input length and the output length are identical.
Accompanied jupyter notebook for this post can be found on Github.
Conclusion
Recurrent neural networks (RNNs) are a family of neural networks for processing sequential data. RNNs consider and uses previous information from the input sequence for the prediction. RNNs also has the limitation that it does not use the information later in the sequence.
I hope this article helped you to get an understanding of RNNs, Backpropagation through time( BPTT), the different architecture of RNNs and how RNNs consider the order of the words and previous input for prediction.
References
Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks. http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts



