



Information Retrieval For Retrieval Augmented Generation
Last Updated on July 24, 2023 by Editorial Team
Author(s): Nadav Barak
Originally published on Towards AI.
Three Battle-Tested Tips to Dramatically Boost Performance
Retrieval Augmented Generation (RAG) refers to Large Language Model (LLM)-based applications that use an Information Retrieval (IR) component in their context generation process. Having a high-performing IR component that provides the LLM with relevant information is key to building a robust RAG application. This post delves into three (and a half) simple tips that can dramatically improve the performance of your information retrieval system. So, without further ado, let’s dive in!
Tip 0.5 – Evaluate your IR performance
Information retrieval refers to the process of finding information from a vast pool of data that is relevant to answer a retrieval query. In RAG applications, the retrieved texts will be attached to the question provided by the user to create the prompt that will be sent to the LLM.
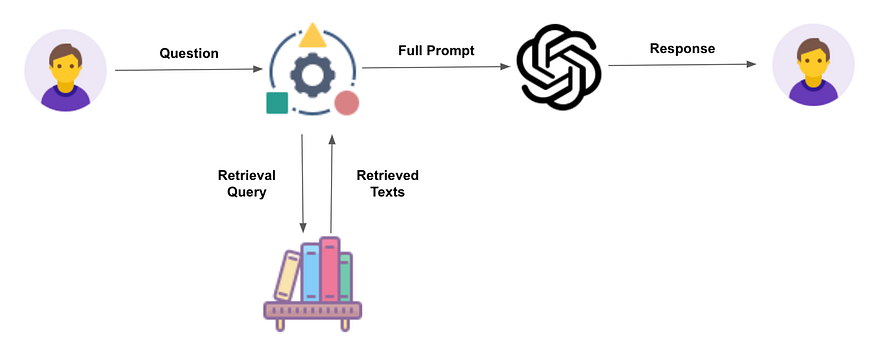
Before we can start talking about performance-improving tips, we first need a reliable way to measure our information retrieval performance.
Building your evaluation set
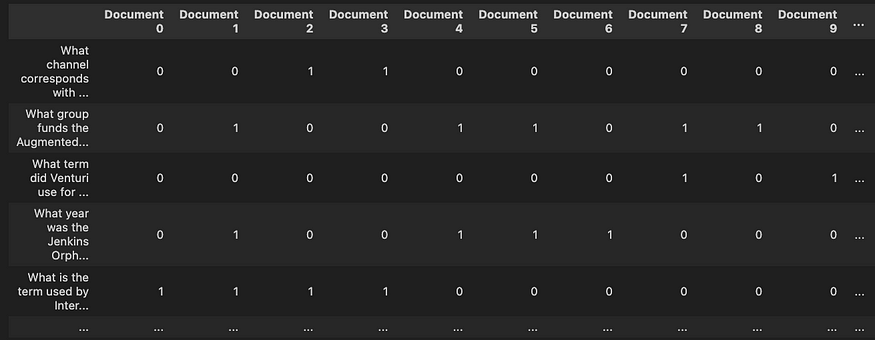
The evaluation set should contain a list of representable queries Q, a list of documents D, and a binary matrix stating which document is relevant to answer which query. Representable queries are indicative or typical of the different kinds of searches that users will commonly perform in the system.
Tip: Utilize an LLM in order to build the matrix by asking it whether a specific document contains relevant information to answer a specific query.
Choosing the right evaluation metrics
We want to check whether the IR system returns all the relevant documents (high recall) but also that it only returns documents that are indeed relevant (high precision). Depending on your use case, one can be more important than the other.
Another decision we have to make when building our IR system is what will be the number of returned documents, K. This is somewhat of an art. We want to have K as small as possible to reduce noise (and potentially costs) while making the result contain as much relevant information as possible. Hence the importance of measuring the expected quality for different K values.
Based on that two considerations, the metrics I would recommend for most use cases are Precision at rank k (P@k) and Recall at rank k (R@k), which measure Precision and Recall for a variety of possible K values. It is important to spend time selecting the right evaluation metric for the use case. For additional details, I highly recommend the following blogpost by Pinecone.

Now that we have the tools to establish a baseline and to check whether my tips are any good, let’s get down to business.
Tip 1- Integrate TF/IDF for similarity distance
Are you telling me there is something more to similarity distance than cosine similarity on the embedding space? Well, yes.
Before all the fancy embedding-based distance calculations, IR systems were based on TF/IDF, the intuitive approach of calculating document similarity based on terms that occur frequently in a particular document but are rare in the overall document collection. As it turns out, integrating a variation of TF/IDF (In addition to the embedding-based search) in the similarity calculations can provide a significant performance boost.
This can be done by representing each document as a combination of a dense embedding vector and a sparse bag of words vector. This method, otherwise known as hybrid search or hybrid retrieval, has out-of-the-box support in many of the popular vector store providers such as Pinecone, Weaviate, and many more.

Tip 2 — Don’t embed your text as is
Regardless of what embedding method or model we chose, its goal is to create a vector representation such that “similar” texts will be mapped to “similar” embedded vectors.
The problem arises when our stored information has a completely different format than our retrieval query. For example, in question answering, the stored information is likely to be long informational documents, while the retrieval query is likely to be a short question.
In order to mitigate the problem, we need to make sure that the stored information and the retrieval query are formatted to a common structure as the first step of the embedding process. This can be done either in the embedding procedure for the stored information, the retrieval query, or both. The formatting operations should be use-case and domain-specific.
Tip: In many use cases, the formatting operation can be performed by a LLM.
Examples:
- Question and answer — For each stored document, ask an LLM, ‘What question does this document provide an answer for?’ Use the embeddings of this response as the document’s representation.
- Nontextual formats such as JSON can be converted to textual paragraphs describing the information stored within them.
Tip 3 — Embed paragraphs, not documents
Focusing on smaller-sized textual objects is likely to improve the quality of the overall retrieved-context due to the following reasons:
- More accurate embeddings: The embedded vector will have better context preservation as paragraphs typically focus on a single topic, while documents could span multiple topics.
- Less noise: The returned results will be more focused and contain less off-topic information.
- Specifically for RAG — Ability to fit information from more documents in the context window.
On the other hand, there are some notable drawbacks:
- Significant increase in the number of embedded vectors we need to store and calculate distance calculations on.
- Some paragraphs may contain information that cannot be understood without the document context.

Conclusion
The efficiency of Retrieval Augmented Generation depends largely on the effectiveness of the Information Retrieval component in place. Thus, it is important to accurately evaluate the information retrieval component and work towards improving it.
Small modifications in the way we store our information and perform our similarity search can dramatically improve the quality of our information retrieval. The three tips discussed in this post are battle tested and have been proven to increase the performance of the applications they were integrated into.
Looking forward to hearing if integrating the tips delivered what was promised, as well as hearing additional tips that worked for you.
Nadav Barak is a hands-on researcher at Deepchecks, a start-up company that arms organizations with tools to validate and monitor their Machine-Learning-based systems. Nadav has a rich background in Data Science and is a domain expert in building and improving Generative NLP applications.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



