



How I Won at Italian Fantasy Football ⚽ Using Machine Learning
Last Updated on July 15, 2023 by Editorial Team
Author(s): Giuseppe Musicco
Originally published on Towards AI.
How I Won at Italian Fantasy Football U+26BD Using Machine Learning
Cracking the code of Fantacalcio through the power of AI
As a mechanical engineer with a keen interest in programming and computer science, I became fascinated by the world of machine learning and artificial intelligence a few years ago. Recognizing their potential across various engineering disciplines, I embarked on a journey to study machine learning. However, despite acquiring theoretical knowledge, I struggled to find practical ways to apply and practice my newfound skills. While ready-made datasets were available, they did not provide the complete experience of collecting and processing data. Then, a thought occurred to me: why not apply machine learning to help me win at fantasy football?
Introduction to Fantacalcio

Fantacalcio is a highly popular game among Italian football fans. Participants form groups and compete throughout the year based on the performances of real players in Serie A, the top Italian football league. Prior to the start of the season, participants hold an auction to draft their rosters of more than 20 players. After each Serie A matchday, players receive votes based on their performance, with additional bonuses for goals and assists. These accumulated votes and bonuses determine the participants’ scores. One of the crucial aspects of the game is selecting a weekly lineup of players, and making decisions on who to play regularly and who to bench.
Aim of my work
The primary objective of my machine learning algorithm would be to predict the vote and fanta-vote (vote plus bonus) of Serie A players based on their team’s match. Football is an inherently uncertain game, as it is impossible to guarantee whether a player will score or not. However, certain players have a higher likelihood of scoring compared to others, and their performance can vary based on the team they are up against. My goal was to find an objective method for determining which player had a higher probability of delivering a stronger performance on any given Serie A matchday.
Disclaimer: sections like this will be used in the article to provide real-case examples from Fantacalcio, to illustrate the concepts discussed. If you are not familiar with the game or Serie A players, feel free to skip these sections.
Gathering and processing the data
Once I downloaded the archive of votes from Fantacalcio, the next step was to collect a comprehensive set of features to train the machine learning algorithm. To construct this dataset, I found fbref.com to be an invaluable resource, providing a convenient means to scrape statistics for both Serie A players and teams. The site offered an extensive range of meticulously compiled statistics, encompassing various metrics such as expected goals, tackles, passes, and average number of chances created. The abundance of detailed data available on FBRef greatly facilitated the process of assembling a robust feature set for training the machine learning algorithm.


The approach I took involved constructing a dataset comprising of more than 50 features for each player. This dataset combined the processed average statistics of the player, merged with their team’s stats and the stats of the opposing team for a given matchday. The target outputs for each row of the dataset were the player’s vote and fanta-vote. To build the dataset, I considered the last three seasons of Serie A.
To address the challenge of unreliable statistics for players with limited game time in the season, I employed three strategies:
- Weighted averaging with the previous season’s stats.
- In the absence of reliable historical data, the player’s stats were averaged with those of the average player in a similar role.
- I used a predefined list to partially average a player’s stats with those of a previous player from the same team who played a similar role.
For instance, the performance of Napoli rookie Kim might be compared to the previous performance of Koulibaly, or Thauvin’s performance could be assessed in relation to his predecessor, Deulofeu (but this turned out to be incorrect).

Definition and training of the algorithm
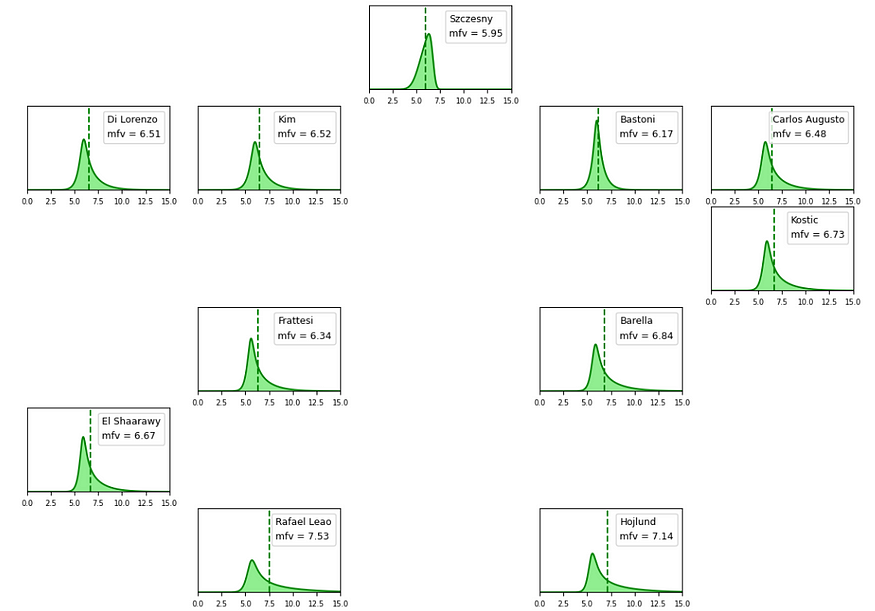
In order to make things more interesting and results nicer to visualize, the machine learning algorithm was designed to go beyond simple vote and fanta-vote predictions. Instead, a probabilistic approach was adopted, leveraging TensorFlow and TensorFlow Probability to construct a neural network capable of generating a probability distribution. Specifically, the network predicted the parameters of a sin-arcsinh probability distribution. This choice was made to account for the inherent skewness in the distribution of player performance vote. For instance, in the case of an offensive player, although their average fanta-vote may be around 6.5, the algorithm recognized that a vote of 10 (indicating an exceptional performance, such as scoring a goal) would be much more likely to occur than a vote of 4 (representing a rare subpar performance).

The deep neural network architecture employed for this task comprised multiple dense layers, each utilizing the sigmoid activation function. To prevent overfitting and enhance generalization, regularization techniques such as Dropout and Early Stopping were used. Dropout randomly disables a fraction of neural network units during training, while Early Stopping halts the training process if the validation loss ceases to improve. The chosen loss function for training the model was Negative Log Likelihood, which measures the discrepancy between the predicted probability distribution and the actual outcomes.
A snippet of the code written for building the neural network is shown here:
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience = 10)
neg_log_likelihood = lambda x, rv_x: -rv_x.log_prob(x)
inputs = tfk.layers.Input(shape=(X_len,), name="input")
x = tfk.layers.Dropout(0.2)(inputs)
x = tfk.layers.Dense(16, activation="relu") (x)
x = tfk.layers.Dropout(0.2)(x)
x = tfk.layers.Dense(16, activation="relu") (x)
prob_dist_params = 4
def prob_dist(t):
return tfp.distributions.SinhArcsinh(loc=t[..., 0], scale=1e-3 + tf.math.softplus(t[..., 1]), skewness = t[..., 2],
tailweight = tailweight_min + tailweight_range * tf.math.sigmoid(t[..., 3]),
allow_nan_stats = False)
x1 = tfk.layers.Dense(8, activation="sigmoid")(x)
x1 = tfk.layers.Dense(prob_dist_params, activation="linear")(x1)
out_1 = tfp.layers.DistributionLambda(prob_dist)(x1)
x2 = tfk.layers.Dense(8, activation="sigmoid")(x)
x2 = tfk.layers.Dense(prob_dist_params, activation="linear")(x2)
out_2 = tfp.layers.DistributionLambda(prob_dist)(x2)
modelb = tf.keras.Model(inputs, [out_1, out_2])
modelb.compile(optimizer=tf.keras.optimizers.Nadam(learning_rate = 0.001),
loss=neg_log_likelihood)
modelb.fit(X_train.astype('float32'), [y_train[:, 0].astype('float32'), y_train[:, 1].astype('float32')],
validation_data = (X_test.astype('float32'), [y_test[:, 0].astype('float32'), y_test[:, 1].astype('
Employing the neural network for predictions
The trained algorithm offered probability distribution predictions for a player’s vote and fanta-vote. By considering the player’s averaged stats, team information, opponent data, and home/away factors, it was capable of predicting the player’s performance for future Serie A matches. Through post-processing of the probability distributions, an expected numeric vote prediction and a maximum potential vote could be derived, simplifying the decision-making for lineup selections in Fantacalcio.

Using Monte Carlo technique, the probability distributions of each player were employed to predict the expected total vote of a lineup. The Monte Carlo method involves running multiple random simulations to estimate potential outcomes. And that’s it! I had all the tools that allowed me to choose the best lineup from my Fantacalcio roster for each Serie A matchday.

Where the algorithm succeded
As an additional metric, I compared the expected votes with my own subjective expectations and found the results satisfying. The algorithm proved particularly effective in the Mantra Fantacalcio variant, which involves players assuming multiple roles similar to real football, ranging from central backs and full-backs to wingers and strikers. Selecting the optimal lineup from the available modules presented a complex challenge, as it wasn’t always the case that offensive players outperformed defensive ones.
Additionally, by using the algorithm to predict selecting a statistically average Serie A team as an opponent, it was useful in preparing for the January market auction. It enabled me to identify undervalued players who may have been underestimated by popular opinion.
Players like El Shaarawy and Orsolini are notable examples of players who performed exceptionally well in the later stages of the Serie A season. The algorithm predicted their expected performance to be at the level of other top midfielders already by the end of January.

Where it failed or could be improved
The algorithm’s weak point lays in predicting the performance of goalkeepers. A separate neural network was developed, utilizing different features and adding clean sheet probability as an output. However, the results were not as satisfying, likely due to the limited number of goalkeepers (only one per team) compared to outfield players. This resulted in a less diverse dataset, increasing the risk of overfitting.
Furthermore, the algorithm considered only the average stats of each player throughout the season. While this approach was sufficient, incorporating data from the player’s previous two or three matches leading up to a given matchday could enhance the algorithm’s ability to account for their current form. This would provide a more comprehensive assessment of the player’s recent performance.
All of the work in public
You can find the code written for this project, as well as the results generated for several Serie A matchdays on Github. I plan to make further improvements for the next season whenever time permits. If you have any questions or need clarification, feel free to contact me.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

