



How I Screwed up a HackerRank Test With a Line of Code
Last Updated on October 26, 2021 by Editorial Team
Author(s): Michelangiolo Mazzeschi
Click here to get to know me, my projects, and my latest articles.
One week ago I was very excited after getting accepted to a coding test for a company I was applying to. I spent the last week preparing for hardcore coding and studying essential algorithms. The date of the test was set for yesterday when I performed my first coding test using HackerRank for an ML Engineer position.
My overall experience was pleasant, at least at the beginning, as I was able to solve 2 problems out of 3 in the first 20 minutes. I was on fire! I honestly thought I had it in the palm of my hand, however, I was claiming victory too fast. Spoiler alert, this was the line of code (the red one instead of the green one) that cost me the test, and, I am assuming, the next round as well.
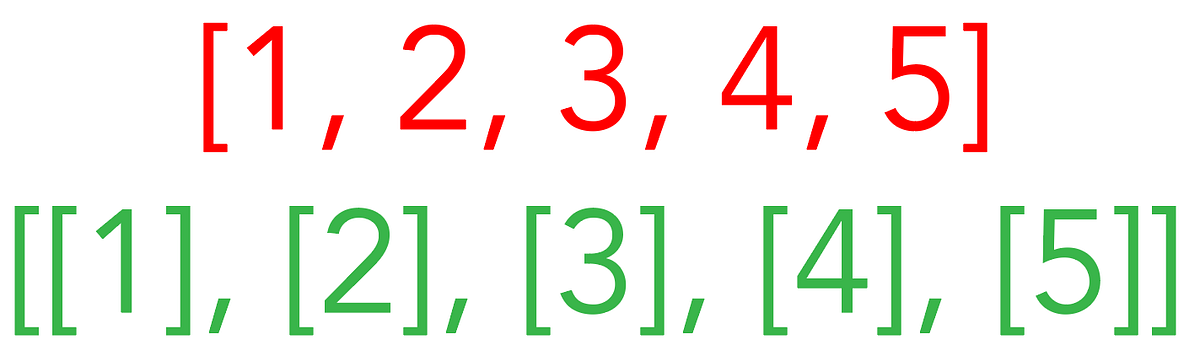
In this article, I explain to you in detail why using the wrong line of code I have not been able to use one of the most rudimental ML models to solve a straightforward HackerRank test.
The problem I had to solve
Although, as asked, I will not reveal the details of the question on the HackerRank test, this was the essence of the problem: I was given a random time-series and I had to perform predictions on it. Seems very simple, I thought, it only needs a regression model, except the part where you have to deal with dates, and that may require a few extra minutes.
My plan was to convert the dates to ordinal numbers beginning from 0 (for ex. 2005, the first date, becomes 0, 2006 -> 1, 2007 -> 2, 2008 -> 3, 2009 -> 4… and so on), then create the regression model. So far so good, except that when I tried to apply the regression model with the dates as Features and the values as Labels: nothing was working.
My mistakes
Before sharing the code, these were my mistakes at the time of the test: I have spent the last day collecting notes and improving my code to prevent them from happening again.
- A bit unprepared one the DateTime library
- My mock function for debugging was too complex to spot the mistakes I was making on the code
- Had trouble recognizing the linear algebra debugging output from sklearn when I was incurring the error: I did not spot my mistake in time, although I conceptualized the resolution of the problem correctly.
How to not commit the same mistakes again
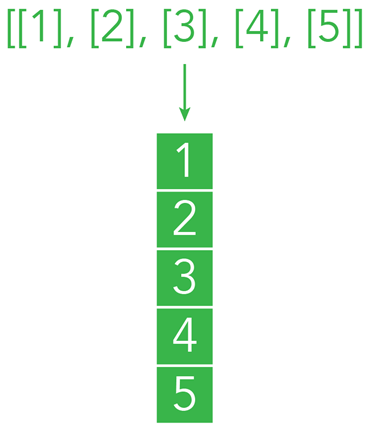
I was trying to apply a regression algorithm on a NumPy with the wrong number of dimensions (5), rather than a nested list (5, 1).
This very little mistake committed on the basis of linear algebra has not allowed me to create a functioning algorithm: the linear regression model (which, in my defense, I have not been using for 6 months) applied to the original Features, was outputting the same exact number!
For example, if I am creating a regression model on these 5 samples because the dots do not follow a linear path, I would expect the regression line to show different results if applied to the features (1, 2, 3, 4, 5). Instead, applying the linear regression on the features I was getting back (98, 97, 88, 75, 82), how was that possible?

The reason is that it was not applying it to every individual feature, but rather considering a whole number.
As a plus, I dedicated a few hours studying in-depth the DateTime library, so that in the future I can just look at my notes with pre-made solutions rather than searching for the documentation.
Why did I commit the rookie mistake?
Maybe pressure, but hopefully, that was not the only cause. To code ML I have been using pandas as a solution ad nauseam. Even the simpler ML model I have been writing in the past month was in the form of pandas DataFrame. What I did not take into account, is that pandas DataFrames are already a nested NumPy array, and because HackerRank was giving me a simple list as input, I had to make the proper conversion in a nested NumPy array.
Right code
Immediately after the test, I decided to try writing the right code and add it to my notes. I figured out in 5 minutes what was the mistake (yes, a bit too late). During the test, instead of using a very simple example like the one below, I tried to correct the code I already had, working on 96 points rather than 5. This level of overcomplexity in addition to the debugging difficulties of HackerRank did not allow me to see things clearly from the beginning, and not realizing that I was inputting a NumPy of 96 numbers of the shape (96, ), rather than (96, 1).
With the simple code below I perform a very simple linear regression starting from a NumPy array, rather than a pandas df (the df is there for reference, I convert it to an array the line after).
import pandas as pd import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model from sklearn.metrics import mean_squared_error, r2_score
#linear regression on timeseries df = pd.DataFrame([[1, 2, 3], [100, 25, 30]]).T df
#np conversion X = np.array(df[0]) y = np.array(df[1])
#reshaping X = X.reshape(3, 1) y = y.reshape(3, 1)
reg = LinearRegression().fit(X, y) reg.predict([[4]])
Graphing the model
Because the test was already over and I had no time limit, I spent a few extra minutes finding an algorithm to visualize the model:
#red dots as scatter plt.scatter(X, y, color='red') #we are graphing the normal dataset
#blue line as regression plt.plot(X, reg.predict(X), color='blue', linewidth=3) #we are graphing [[1], [2], [3]] and the predictions for 1, 2, 3
plt.xticks(()) plt.yticks(()) plt.show()
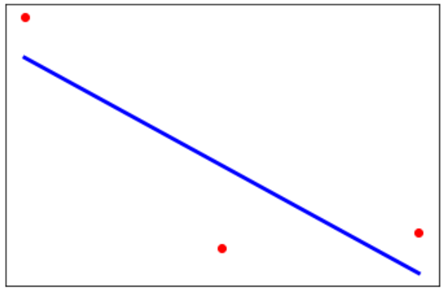
If during the code I would have written the algorithm in its simplest form (3 dots only), I would have probably noticed my mistake on time. However, even if this is not my regular practice, I overcomplicated it.
Conclusion
There is nothing left to say at this point, keep studying, keep improving, let’s crack the next test!
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts




Comments are closed.