


From Good to Great: Elevating Model Performance through Hyperparameter Tuning
Last Updated on January 29, 2024 by Editorial Team
Author(s): Shivamshinde
Originally published on Towards AI.
This article will explain the concept of hyperparameter tuning and the different methods that are used to perform this tuning, and their implementation using python
Table of Content
- Model Parameters Vs Model Hyperparameters
- What is hyperparameter tuning?
- Examples of hyperparameters for algorithms
- Advantages and Disadvantages of hyperparameter tuning
- How to perform hyperparameter tuning?
– Coarse to Finner Approach (RandomizedSearchCV + GridSearchCV) - Summary
- Code and References
Model Parameters Vs Model Hyperparameters
The model parameters are the variables that allow the model to train on the training data. We do not set the value of model parameters. Their values change gradually during the training process. However, sometimes we do need to provide the initial values for them. The change in the value of model parameters is stopped when the training is completed.
For example, in the training of deep learning models, the weights and biases can be considered as model parameters. This is because before the start of training, weights and biases are initialized randomly, and during the training, they gradually change until the training is completed.
The model hyperparameters are the variables that determine how the training should be conducted. In other words, they control the model parameters indirectly. Unlike model parameters, we need to manually set the values of hyperparameters before the training is started. Additionally, the values of hyperparameters, once set, do not change during the entire process of training.
For example, in the training of deep learning models, the hyperparameters are the number of layers, the number of neurons in each layer, the activation function, the dropout rate, etc. The values of these hyperparameters are initialized at the beginning of the training. Also, once initialized, they do not change during the whole training process. Moreover, note that the value of model parameters such as weights and biases change for every different choice of hyperparameters.
What is hyperparameter tuning?
Every type of machine learning and deep learning algorithm has a large number of hyperparameters. On top of that, most of the training datasets are multi-dimensional and, hence, hard to visualize using even 3-D graphs. As a result of this, we are not able to deduce the combination of hyperparameters that will give us an optimal performance on test data.
To address this issue, we experiment with various combinations of hyperparameters.
We use a certain combination of hyperparameters to train our model and then we record its performance on the test data. We do this for as many combinations as we can and then use the combination of hyperparameters that gives us the best results on the test data.
So, in a nutshell, hyperparameter tuning is just an experiment to see which hyperparameters give the best performance.
Examples of hyperparameters for algorithms
Now that we know what hyperparameters are and what hyperparameter tuning is, let’s see the hyperparameters we need for some of the famous algorithms.
Ridge and Lasso Regression
alpha: This hyperparameter controls the regularization strength. alpha lies in the range [0, Inf).
Elastic Net Regression
alpha: This hyperparameter controls the regularization strength. alpha lies in the range [0, Inf).
l1_ratio: This hyperparameter controls the ratio in which l1 and l2 regularization terms should be added to the cost function. l1_ratio lies in the range [0, 1].
Logistic Regression
penalty: This hyperparameter decides which penalty to add to the cost function. It can have values: [‘l1’, ‘l2’, ‘elasticnet’, ‘None’].
C: This hyperparameter decides the regularization strength. The higher the value of C, the lower the regularization strength. C can take any positive float value.
Support Vector Machine Classification and Regression
C: This hyperparameter decides the regularization strength. The higher the value of C, the lower the regularization strength. C can take any positive float value.
kernel: This hyperparameter decides which kernel to be used in the algorithm. It can take the values: [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’].
K-Nearest Neighbors Algorithm
n_neightbors: This hyperparameter decides the number of neighboring data points to be considered for the algorithm
radius: This hyperparameter decides the radius that is used to find the neighbors in the algorithm
Decision Tree Classification and Regression
max_depth: This hyperparameter decides the maximum depth of the tree
criterion: This hyperparameter decides the function to be used to determine the quality of the split. It can have values: [‘gini’, ‘entropy’, ‘log_loss’].
min_samples_split: The minimum number of samples required to split an internal node
min_samples_leaf: The minimum number of samples required to be at a leaf node
Gradient Boosting Classification and Regression
loss: This hyperparameter represents the loss that needs to be optimized. It can have the values: [‘log_loss’, ‘exponential’]
learning_rate: This hyperparameter decides the rate at which the contribution of the tree is decreased. The value is in the range [0.0, Inf).
n_estimators: The number of boosting stages to perform. The value is in the range [1, Inf).
min_samples_split: The minimum number of samples required to split an internal node
min_samples_leaf: The minimum number of samples required to be at a leaf node
max_depth: This hyperparameter decides the maximum depth of the tree
max_features: The number of features to consider when looking for the best split
validation_fraction: The proportion of training data to set aside as validation set for early stopping
n_iter_no_change: n_iter_no_change is used to decide if early stopping will be used to terminate training when the validation score is not improving.
, etc.
Advantages and Disadvantages of hyperparameter tuning
Advantages
- Model performance could be improved.
- The overfitting or underfitting could be reduced.
- Model generalization on test data could be increased.
Disadvantages
- There is a high computational cost involved since we are training the model multiple times.
- This is a time-consuming process.
- There is no guarantee that we will get the model with better performance.
- To decide the appropriate set of hyperparameters for the tuning, domain expertise is needed.
How to perform hyperparameter tuning?
Let’s use Kaggle’s wine quality dataset for the demonstration of hyperparameter tuning.
Loading the data
## Ignoring warnings
import warnings
warnings.filterwarnings('ignore')
## Importing required libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, RandomizedSearchCV, GridSearchCV, StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# !pip install scikit-optimize
from skopt.space import Integer
from skopt.utils import use_named_args
from skopt import gp_minimize
## Loading the data
df = pd.read_csv('/kaggle/input/red-wine-quality-cortez-et-al-2009/winequality-red.csv')
df.head()

df.info()

Preprocessing the data
## Preprocessing the data:
## dropping duplicate records
df.drop_duplicates(inplace=True)
## Splitting the data into dependent and independent features
X, y = df.drop('quality', axis=1), df['quality']
## 1. Dropping duplicates is necessary.
## 2. There are no missing values in the data.
## 3. Data has outliers.
## 3. Data needs scaling.
## 4. Dataset is not imbalanced.
## Splitting the data into training and testing data
Xtrain, Xtest, ytrain, ytest = train_test_split(X,y,test_size=0.2,stratify=y)
## Dealing with the outliers: replacing the outlier with the median of feature column
quantiles = Xtrain[Xtrain.columns].quantile(np.arange(0,1,0.25)).T
quantiles = quantiles.rename(columns={0.25:'Q1', 0.50: 'Q2', 0.75:'Q3'})
quantiles['IQR'] = quantiles['Q3'] - quantiles['Q1']
quantiles['Lower_Limit'] = quantiles['Q1'] - 1.5*quantiles['IQR']
quantiles['Upper_Limit'] = quantiles['Q3'] + 1.5*quantiles['IQR']
for feature in Xtrain.columns:
Xtrain[feature] = np.where((Xtrain[feature] < quantiles.loc[feature,'Lower_Limit']) U+007C
(Xtrain[feature] > quantiles.loc[feature,'Upper_Limit']) & (Xtrain[feature] is not np.nan),
Xtrain[feature].median(), Xtrain[feature])
for feature in Xtest.columns:
Xtest[feature] = np.where((Xtest[feature] < quantiles.loc[feature,'Lower_Limit']) U+007C
(Xtest[feature] > quantiles.loc[feature,'Upper_Limit']) & (Xtest[feature] is not np.nan),
Xtest[feature].median(), Xtest[feature])
## Scaling the features
sc = StandardScaler()
Xtrain = sc.fit_transform(Xtrain)
Xtest = sc.transform(Xtest)
Coarse to Finner Approach (RandomizedSearchCV + GridSearchCV)
In this approach, we will first randomly search the whole search space to find the area that is giving us the best results. Once we get the area, then we search systematically inside this area for the optimal hyperparameters.
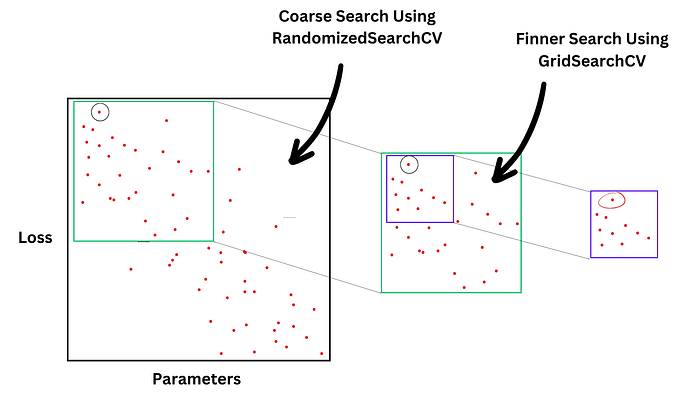
Coarse search using RandomizedSearchCV
## Coarse hyperparameter tuning using RandomizedSearchCV
coarse_search_space = dict()
coarse_search_space['n_estimators'] = list(np.arange(100,500))
coarse_search_space['criterion'] = ['gini', 'entropy', 'los_loss']
coarse_search_space['max_depth'] = list(np.arange(2,5))
coarse_search_space['min_samples_split'] = list(np.arange(2,10))
coarse_search_space['min_samples_leaf'] = list(np.arange(1,10))
coarse_search_space['max_features'] = list(np.arange(2,11))
rfc = RandomForestClassifier()
skf = StratifiedKFold(n_splits=5)
r_grid = RandomizedSearchCV(estimator=rfc, param_distributions=coarse_search_space, cv=skf, verbose=1, scoring='accuracy')
r_grid.fit(Xtrain, ytrain)

print(f"The best score: {r_grid.best_score_}\n")
print(f"The best parameters:\n {r_grid.best_params_}\n")

Finner search using GridSearchCV
## Finner hyperparameter tuning using GridSearchCV
coarse_search_space = dict()
coarse_search_space['n_estimators'] = [50,100,150,200]
coarse_search_space['criterion'] = ['gini']
coarse_search_space['max_depth'] = [2,3,4]
coarse_search_space['min_samples_split'] = [5,6,7]
coarse_search_space['min_samples_leaf'] = [3,4,5]
coarse_search_space['max_features'] = [8,9,10]
rfc = RandomForestClassifier()
skf = StratifiedKFold(n_splits=5)
grid = GridSearchCV(estimator=rfc, param_grid=coarse_search_space, cv=skf, verbose=1, scoring='accuracy')
grid.fit(Xtrain, ytrain)

print(f"The best score: {grid.best_score_}\n")
print(f"The best parameters:\n {grid.best_params_}\n")

We can observe here that the score increased slightly from coarse to finner search.
Summary
In this article, we learned the difference between model parameters and model hyperparameters, the pros and cons of hyperparameter tuning, and its examples, and the implementation using different libraries. Many other libraries, such as Hyperopt, Optuna, etc., can be used for the hyperparameter tuning. But all perform the same operations.
Code and References
Whole Code
Hyper
Explore and run machine learning code with Kaggle Notebooks U+007C Using data from Red Wine Quality
www.kaggle.com
References
Parameters Vs Hyperparameters: What is the difference?
Discuss with 4 different examples
medium.com
What is Hyperparameter Tuning? – Hyperparameter Tuning Methods Explained – AWS
What is Hyperparameter Tuning how and why businesses use Hyperparameter Tuning, and how to use Hyperparameter Tuning…
aws.amazon.com
Blog
Here at Analytics Vidhya, beginners or professionals feel free to ask any questions on business analytics, data…
www.analyticsvidhya.com
Hyperparameter tuning – GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and…
www.geeksforgeeks.org
Bayesian Optimization Concept Explained in Layman Terms
Bayesian Optimization for Dummies
towardsdatascience.com
https://machinelearningmastery.com/what-is-bayesian-optimization/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts




Popular posts

 for 2021")



Updates

Recent Posts


