



A Complete Guide to RAG and LlamaIndex
Last Updated on January 25, 2024 by Editorial Team
Author(s): Luv Bansal
Originally published on Towards AI.
A comprehensive guide to Retrieval-Augmented Generation (RAG) with LlamaIndex Implementation
Language models like LLMs are extensively pre-trained on vast amounts of public information, enabling them to perform various NLP tasks such as text classification, summarisation, question answering, and even chatbot development, etc. While these models possess immense knowledge about a wide range of topics worldwide and exhibit exceptional reasoning and mathematical abilities, a critical question arises: are they truly effective for specific use cases, such as developing a chatbot tailored to answer questions about a particular company (let’s say, XYZ)? It seems unlikely, as language models may lack training on company-specific data.
Therefore, how can we make these models work with our own data? i.e, how could we augment LLMs with our own private data? To bridge this gap and customize LLMs for our specific needs, we delve into the concept of Retrieval-Augmented Generation (RAG). This blog will delve into RAG, with a particular focus on understanding and incorporating LlamaIndex to seamlessly incorporate our own private data, residing in diverse sources like Amazon S3, PDFs, SQL databases, Notion, APIs, raw files, and more, to enhance the capabilities of these language models and enhance the performance of language models in our domain.
Teaching the model to recognize when it doesn’t know
Paradigms for inserting knowledge into LLMs
- Fine-tuning:
Fine-tuning is a process that takes a model that has already been trained and then tunes or tweaks the model to make it perform a similar task. Therefore, instead of training a new network from scratch, we can re-use the existing one. So, we start the training on the new data but with the weights initialized to those of the initial network.
Downsides
- High Computation
- Data preparation effort
- High Cost
- Need ML expertise
2. In context learning:
Putting context into the prompt.
Less learning and more how do I find the best conditional variable or prompt engineering in order to make sure that when prompt send to LLM, it has all the context information and get the output we want. It works on the principle, given the context, and then answers the following question.
Challenges
- How to retrieve the right context for the prompt?
- How do we deal with long context, as the context might be too long and could exceed the context window of LLM?
- How to deal with unstructured/semi structure/ structure data?
- How to deal with source data that is potentially very large
3. Retrieval-Augmented Generation (RAG):
Retrieval-Augmented Generation (RAG) involves enhancing the performance of a large language model by making it refer to a reliable knowledge base beyond its initial training data sources before generating a response. Large Language Models (LLMs) undergo training on extensive datasets and leverage billions of parameters to generate unique content for tasks such as answering questions, language translation, and sentence completion. RAG takes the powerful capabilities of LLMs a step further by tailoring them to specific domains or an organization’s internal knowledge base, all without requiring the model to undergo retraining. This cost-effective approach ensures that the output of LLMs remains relevant, accurate, and valuable in diverse contexts.
RAG resolves all the downsides and challenges of previous approaches. Let’s see how RAG overcame all the downsides and challenges of previous approaches by understanding how the RAG works
How Does Retrieval-Augmented Generation Work?
Without RAG, the LLM takes the user input and creates a response based on the information it was trained on — or what it already knows. With RAG, an information retrieval component is introduced that utilizes the user input to first pull information from a new data source. The user query and the relevant information are both given to the LLM. The LLM uses the new knowledge and its training data to create better responses. The following sections provide an overview of the process.
Create external data and store it in a vector database
The new data outside of the LLM’s original training data set is called external data. It can come from multiple data sources, such as APIs, databases, or document repositories. The data may exist in various formats like files, database records, or long-form text. Another AI technique, called embedding language models, converts data into numerical representations and stores it in a vector database. This process creates a knowledge library that the LLM can understand.
Retrieve relevant information
The next step is to perform a relevancy search. The user query is converted to a vector representation called embedding and matched with the vector databases. For example, consider a smart chatbot that can answer human resource questions for an organization. If an employee searches, “How much annual leave do I have?” the system will retrieve annual leave policy documents alongside the individual employee’s past leave record. These specific documents will be returned because they are highly-relevant to what the employee has input. The relevancy was calculated and established using mathematical vector calculations and representations called semantic search.
Augment the LLM prompt
Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context (query + context). This step uses prompt engineering techniques to communicate effectively with the LLM. The augmented prompt allows the large language models to generate an accurate answer to user queries.

The System Workflow
This workflow explains the overall working of RAG in a very intuitive way
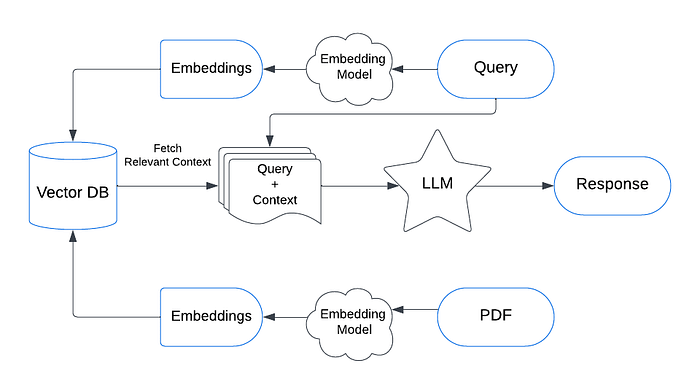
The workflow of the RAG-based LLM application will be as follows:
- Receive query from the user.
- Convert it to an embedded query vector preserving the semantics, using an embedding model.
- Retrieve the top-k relevant content from the vector database by computing the similarity between the query embedding and the content embedding in the database.
- Pass the retrieved content and query as a prompt to an LLM.
- The LLM gives the required response.
Advantages of RAG
I hope you now have a better understanding of how RAG has overcome all the downsides and challenges of previous approaches. Let’s look at the advantages of RAG.
- Less/ no computation: No need to train the model on our own data; therefore, less computation is required
- Easily deal with unstructured/semi structure/ structure data
- Easily deals with long context: RAG retrieves content that is most relevant to a user query, that usually less than the context length of LLM
- No need of ML expertise
What we need to implement RAG
- Framework to implement RAG
There are frameworks like llamaIndex and langchain, which have all the things to implement RAG. In this blog, we’ll look thoroughly at llamaIndex, understand how it works, and implement RAG using llamaIndex. - Embedding Model
RAG needs an embedding model to index data and convert all data into a numerical format so that our LLM can understand. There are various SOTA embedding model exits; some are optimized to index data for RAG. - Vector Store
Vector Stores are the databases that are used to store the vector embeddings and provide an efficient way to store data in indexed form so it would be easy and efficient to retrieve context when the query is received from the user. - LLM
It’s the language model and the most important component which provides answers to the user query by passing retrieved content and query as a prompt to an LLM
LlamaIndex: Framework to Implement RAG
Now, we’ll look at the AI framework, which helps us implement RAG into the application and scale up to the larger corpus of our data.
What is LlamaIndex?
LlamaIndex is an AI framework that simplifies the integration of private data with public data for building applications using Large Language Models (LLMs). It provides tools for data ingestion, indexing, and querying, making it a versatile solution for generative AI needs.
In simple terms, LlamaIndex acts as the interface between our data and language model, and the interface is fast, cheap, efficient, and performant.
LlamaIndex different components
- Data Connectors
This helps to connect our existing data sources and data formats (like APIs, PDFs, etc.) and address these data sources in a format that can be used with LlamaIndex - Data Indices
This helps to structure data for the different use cases; once we loaded all the data from different data sources, then how to actually splits them up, define relationships between nodes, and have a way of organizing this information such that regardless of the task that you want to solve (question-answer, summarisation, etc.) you’re able to use this index to retrieve the relevant information. - Query Interface
It is the interface to input prompt and obtain a knowledge-augmented output from the LLM.
All these different components make llamaIndex the central interface and data management system, specifically in the service of LLMs
Installation and Setup
Before exploring the exciting features, let’s first install LlamaIndex on your system. If you’re familiar with Python, this will be easy. Use this command to install:
pip install llama-index
- By default, LlamaIndex uses OpenAI’s gpt-3.5-turbo for creating text and text-embedding-ada-002 for fetching and embedding. You need an OpenAI API Key to use these. Get your API key for free by signing up on OpenAI’s website. Then set your environment variable with the name OPENAI_API_KEY in your python file.
import os
os.environ["OPENAI_API_KEY"] = "your_api_key"
Now, we look at each of the different components thoroughly
Data connectors: Powered by LlamaHub
- It allows easy ingesting of any kind of data from anywhere into the unified document containers
- LlamaHub is a registry of open-source data connectors that you can easily plug into any LlamaIndex application
- There are hundreds of connectors to use on LlamaHub!
Less 10 lines of code to ingest data from Notion.
from llama_index import download_loader
import os
NotionPageReader = download_loader( NotionPageReader')
integration_token = os. getenv("NOTION_INTEGRATION_TOKEN")
page_ids = ["‹page_id>"]
reader = NotionPageReader(integration_token=integration_token)
documents = reader.load_data (page_ids=page_ids)
Less 5 lines of code to ingest data from local directory.
Loading using SimpleDirectoryReader
The easiest reader to use is our SimpleDirectoryReader, which creates documents out of every file in a given directory. It is built into LlamaIndex and can read a variety of formats, including Markdown, PDFs, Word documents, PowerPoint decks, images, audio, and video.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader('/content/content').load_data()
Less 10 lines of code to ingest data from Database
LlamaIndex downloads and installs the connector called DatabaseReader, which runs a query against a SQL database and returns every row of the results as a Document:
from llama_index import download_loader
DatabaseReader = download_loader("DatabaseReader")
reader = DatabaseReader(
scheme=os.getenv("DB_SCHEME"),
host=os.getenv("DB_HOST"),
port=os.getenv("DB_PORT"),
user=os.getenv("DB_USER"),
password=os.getenv("DB_PASS"),
dbname=os.getenv("DB_NAME"),
)
query = "SELECT * FROM users"
documents = reader.load_data(query=query)
Data Indexes
- With our data loaded, we now have a list of Document objects (or a list of Nodes). It’s time to build an
Indexover these objects so you can start querying them. - Data indexes help to abstract away common boilerplate/pain points for a context-learning
- It structures your data, chunks it up, and stores context in an easy-to-access format for prompt insertion.
- It also deals with context length limitation (8k or 32k for GPT-4) since it only gives relevant information as a context to the LLM.
- It deals with splitting and structuring data into the right format and into the right chunk size.
What is an Index?
In LlamaIndex terms, an Index is a data structure composed of Document objects, designed to enable querying by an LLM. Index is designed to be complementary to your querying strategy.
LlamaIndex offers several different index types. We’ll cover the most common one here.
Vector store Index
A VectorStoreIndex is by far the most frequent type of Index you’ll encounter.
It works as follows:
- It first ingests the data from the source documents (ex: Notion, PDFs, etc)
- Then, llamaIndex user the hood splits up the text into chunks and then stores each chunk as a node
- Each node would be associated with embeddings for that node, ready to be queried by an LLM. Embedding could be generated from any embedding model.
- Store all embedding into the vector database called vector store.
- The user query is itself turned into a vector embedding, and then a mathematical operation is carried out by VectorStoreIndex to rank all the embeddings by how semantically similar they are to your query.
Top K Retrieval
Once the ranking is complete, VectorStoreIndex returns the most-similar embeddings as their corresponding chunks of text. The number of embeddings it returns is known as k, so the parameter controlling how many embeddings to return is known as top_k. This whole type of search is often referred to as “top-k semantic retrieval” for this reason.
from llama_index.llms import OpenAI
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.embeddings import OpenAIEmbedding
embed_model = OpenAIEmbedding()
llm = OpenAI(temperature=0.1, model="gpt-4")
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model, chunk_size=1000
)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
Service Context in LlamaIndex
The ServiceContext is a bundle of commonly used resources used during the indexing and querying stage in a LlamaIndex pipeline/application
Here’s a complete example that sets up all objects using their default settings:
from llama_index import (
ServiceContext,
OpenAIEmbedding,
PromptHelper,
)
from llama_index.llms import OpenAI
from llama_index.text_splitter import SentenceSplitter
llm = OpenAI(model="text-davinci-003", temperature=0, max_tokens=256)
embed_model = OpenAIEmbedding()
text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None,
)
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
text_splitter=text_splitter,
prompt_helper=prompt_helper,
)
Integrating vector store
The API calls to create the embeddings in a VectorStoreIndex can be expensive in terms of time and money, so we will want to store them to avoid having to constantly re-index things.
LlamaIndex supports a huge number of vector stores which vary in architecture, complexity and cost. In this example, we’ll be using Chroma, an open-source vector store.
First, you will need to install chroma:
pip install chromadb
import chromadb
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
from llama_index.llms import OpenAI
from llama_index.embeddings import OpenAIEmbedding
# load some documents
documents = SimpleDirectoryReader("./data").load_data()
# Initialise LLM and embedding model
llm = OpenAI(temperature=0.1, model="gpt-4")
embed_model = OpenAIEmbedding()
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
# initialize client, setting path to save data
db = chromadb.PersistentClient(path="./chroma_db")
# create collection
chroma_collection = db.get_or_create_collection("quickstart")
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# create your index
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, service_context=service_context
)
Storage Context defines the storage backend for where the documents, embeddings, and indexes are stored. You can learn more about storage and how to customize it.
Query Interface
- Query Interface on top of these indices that simultaneously retrieve/synthesizes information
- Users have a Natural language query, and it first generates an embedding for that query.
- Then use that query embedding to retrieve the top-k nodes from the vector store using data indexes.
response = index.query("What are the best ideas for the site?")
print(response)
Retrieve more context for any query
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("What did the author do growing up?")
print(response)
as_query_engine builds a default retriever and query engine on top of the index. You can configure the retriever and query engine by passing in keyword arguments. Here, we configure the retriever to return the top 5 most similar documents (instead of the default of 2). You can learn more about retrievers and query engines.
Response Modes in LlamaIndex
This defines how to process the query and retrieve relevant information from the indexed data. You can learn more about response modes here.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("What did the author do growing up?")
print(response)
Building chatbot using LlamaIndex
we can also build a chatbot using LlamaIndex instead of Q&A. You can learn more about here.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)
response = query_engine.chat("Oh interesting, tell me more.")
print(response)
Final thoughts
This guide provides a solid foundation for understanding RAG and implementing it using LlamaIndex. Our deep dive into Retrieval-Augmented Generation (RAG) and LlamaIndex has uncovered powerful strategies for enhancing the capabilities of Large Language Models (LLMs). By incorporating private data seamlessly into LLMs, we address the limitations of traditional approaches, such as high computation costs and the need for extensive data preparation. RAG’s advantages, including minimal computation, effective handling of unstructured data, and efficient management of long contexts, make it a game-changer. LlamaIndex emerges as a vital framework, simplifying the integration of private and public data, offering tools for data management, and serving as a fast and efficient interface between our data and language models.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



