



Why Perceptron Neurons Need Bias Input?
Last Updated on July 20, 2023 by Editorial Team
Author(s): Caio Davi
Originally published on Towards AI.
Everybody knows what is the neural network bias input. And everybody uses it since the very first Perceptron implementation. But why we use it? Did you ever consider it? Talking for myself, I did not until some time ago. I was discussing some neural network models with an undergrad, and somehow she was mistaking the bias input with the statistical bias. I explained the concepts for her quite easily, but I had a hard time explaining why we use the bias. After a while, I decided to try some code to have a further investigation of it.
Let’s start with a brief context.
The Perceptron is the predecessor of the Multilayer Perceptron (MLP) Artificial Neural Networks. It is a well known, bio-inspired algorithm to do supervised learning. It works as a linear classifier, as we can see in the image:

Below we can see the mathematical equation for this model:
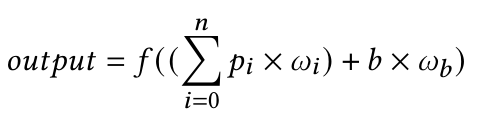
You may notice the similarity with the canonical form of a linear function. If we remove the activation function, those formulas would be the same (here we are considering only one input for clarity):

Comparing those two formulas, it is clear that our bias is the b component of a linear function. So, now the question is: what is the importance of the b component in the linear function? If you didn’t have any linear algebra course in the last years (just like me), it could be hard to remember. But it is a simple concept and quite easy to understand graphically:
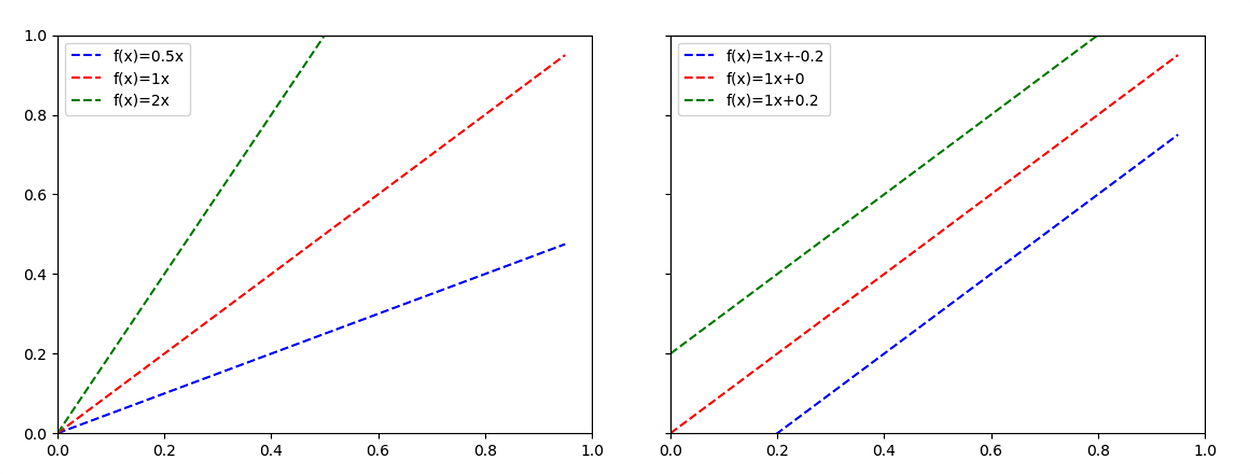
So, it is easy to notice that with b=0, the function will always pass through the origin [0,0]. And when we introduced values to b keeping a fixed, the new functions will always be parallel to each other. So, what could we learn from it?
We can say that a component determines the angulation of the function, while the b component determines where the function cuts the x-axis.
I think you already noticed the problem in that, right? We lose a lot of flexibility without the b component. It might work to classify some distributions, but not for everyone. How about testing it and see how it works in practice? Let’s use a simple example: the OR function. Let’s take a look at its distribution (actually, the table of truth):
If we plot it on a Cartesian-Plane:
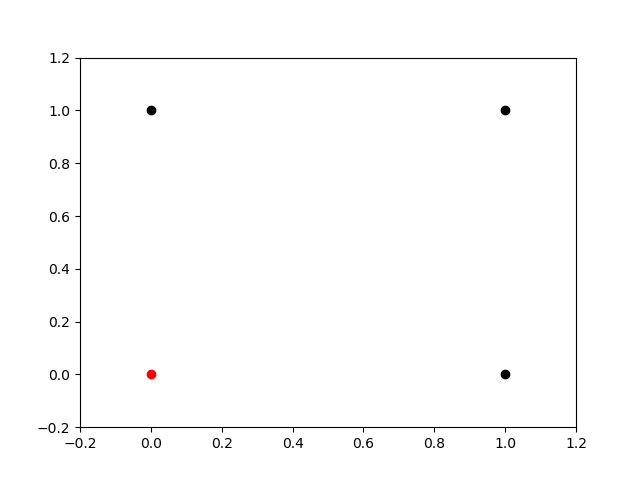
I think you have already figured out the problem. There are two points ([0,0] and [1,0]) passing through the origin with different classifications. There is no way for a line passing throw [0,0] to split these two populations. How will the Perceptron deal with it? How will it be with bias and without bias? Let’s get into some code to see how things will happen! There is a simple Python implementation of a Perceptron Neuron:
class Perceptron():def __init__ (self, n_input, alpha=0.01, has_bias=True):
self.has_bias = has_bias
self.bias_weight = random.uniform(-1,1)
self.alpha = alpha
self.weights = []
for i in range(n_input):
self.weights.append(random.uniform(-1,1))def classify(self, input):
summation = 0
if(self.has_bias):
summation += self.bias_weight * 1
for i in range(len(self.weights)):
summation += self.weights[i] * input[i]
return self.activation(summation)def activation(self, value):
if(value < 0):
return 0
else:
return 1
def train(self, input, target):
guess = self.classify(input)
error = target - guess
if(self.has_bias):
self.bias_weight += 1 * error * self.alpha
for i in range(len(self.weights)):
self.weights[i] += input[i] * error * self.alpha
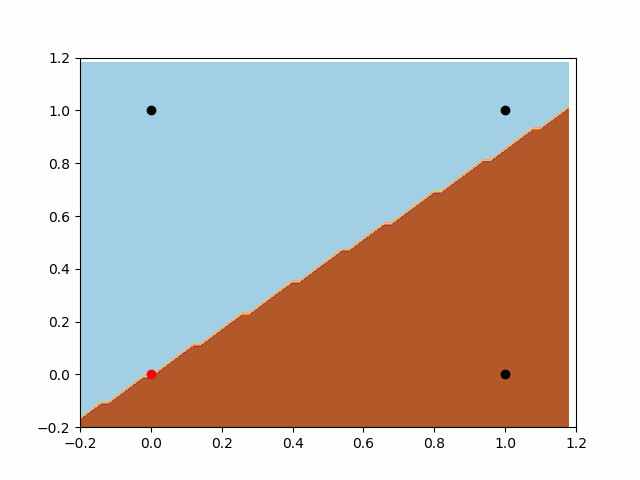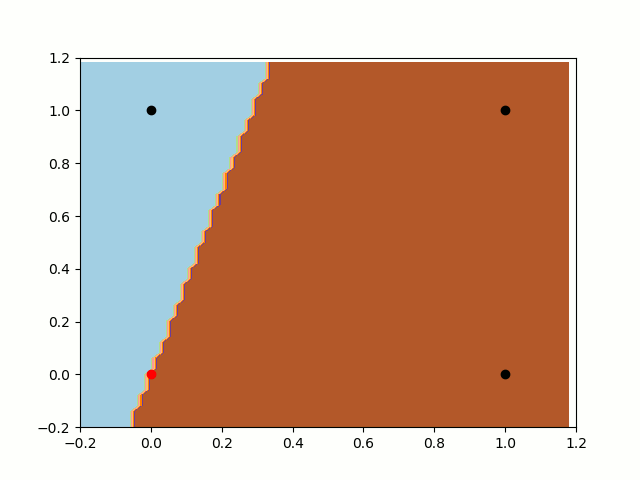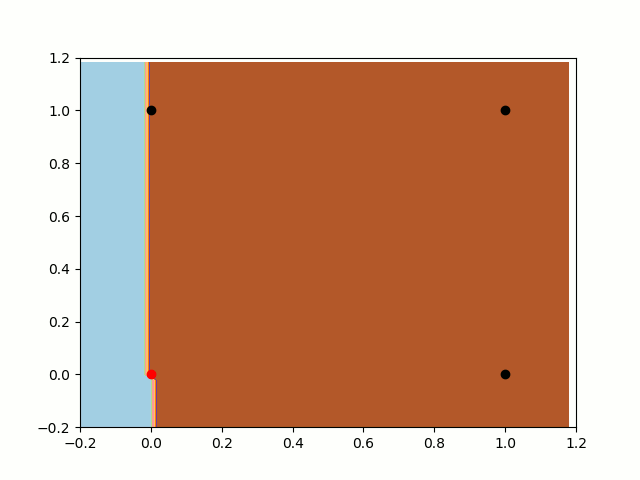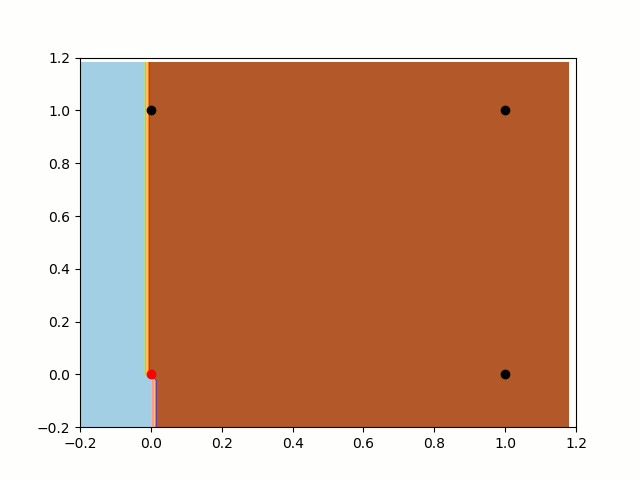
First, let’s take a look at the training without bias. As we know, the classification rule (our function, in this case) will always pass throw the point [0,0]. As we can notice bellow, the classifier will never be able to separate the classes. In this case, it is very near to a do it, but it can’t split [0,0] and [1,0] apart.
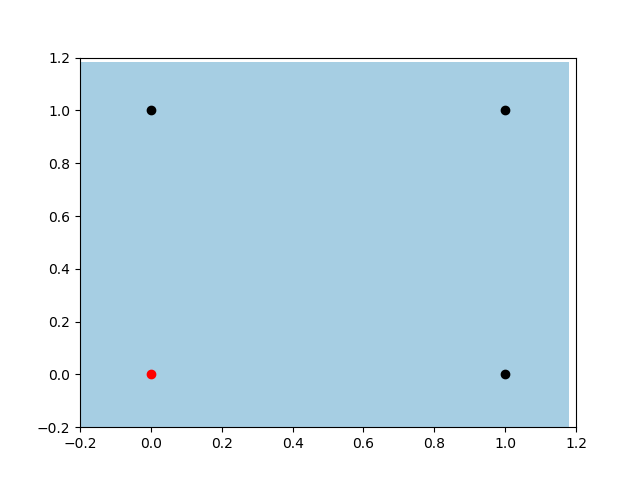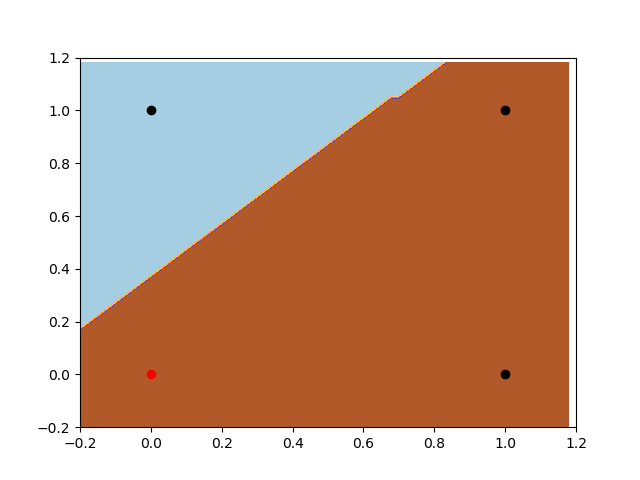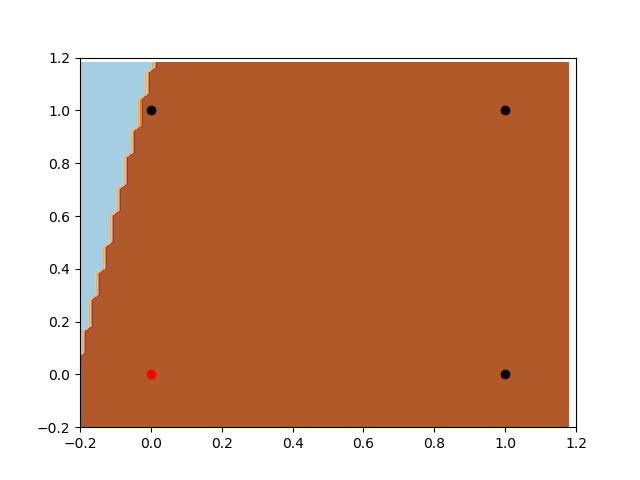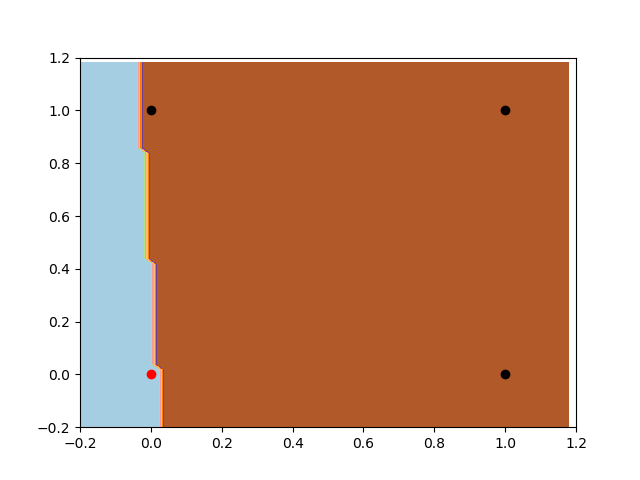
Let’s take a look now on the Perceptron with the bias input. Firstly, notice the freedom of the classifier. As we talked before, it has much more flexibility to create different rules. Also, we can notice that it is looking for the same local minimum of the last example, but now he can move openly and find the best place to split the data.
So, I think the importance of the bias input is quite clear now. You might be thinking in the activation function, I know. We used a step function on the python example, and maybe if we use a sigmoid as activation function, it could work better without the bias. Trust me: it won’t. Let’s take a look at how the function changes when we plug-in the linear function into a sigmoid activation function ( then we have σ(f(x)) ):
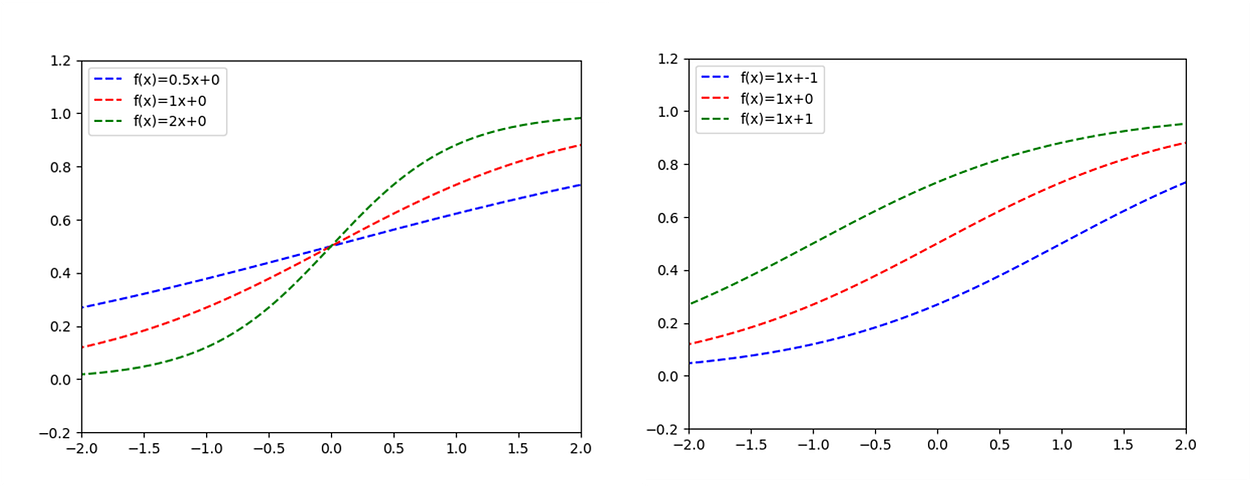
Did you notice that what we have here is quite similar to the linear function example? The sigmoid function changes the format, but we still have the same problem: without bias, all the functions pass throw the origin. And it is still an undesired behavior when we are trying to fit a curve into a population. If you want to try it out and see how it works, you just need to make some little modifications to the python code.
I genuinely appreciate your interest in the subject. If you have any suggestions, opinions, or just want to say hi, please leave a comment! I’ll be glad to discuss it with you!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

