



What is Ensemble Technique?
Last Updated on July 26, 2023 by Editorial Team
Author(s): Akash Dawari
Originally published on Towards AI.
All About Ensemble Techniques
In this article we will try to understand the idea of the ensemble in the context of machine learning by answering the following questions:
- What are Ensemble Techniques?
- What are the different types of Ensemble techniques?
- What are the advantages and disadvantages of the Ensemble Technique?
- How do implement different Ensemble Techniques?
Before we answer the question let’s take an example, assume there are two teams (Team A and Team B) who are participating in a quiz. Team A has only one member and Team B has 4 members in their team. So, if we have to bet which team will win the quiz without knowing the knowledge of the team members. Most of us will go for team B. This is because the aggregate knowledge of team B must be higher than team A hence the chances of winning are expected with team B.
Ensemble Technique in machine learning follows the same rule that aggregating the results of different algorithms will give better prediction than an individual algorithm. So, in simple words ensemble technique is a way of arranging different or same machine learning algorithms together to get a better prediction.
The main intuition behind using ensemble techniques is to achieve a model with low bias and low variance which finally result in better prediction.
What are the different types of Ensemble techniques?
Ensemble Techniques can be classified on the basis of how we are arranging different or same machine learning models. Basically, they are widely segregated into four types:
- Voting
- Stacking
- Bagging
- Boosting
Let’s go through each type of ensemble technique and understand them.
What is Voting Ensemble Technique?
In a democracy, people vote for different political parties to form a functional government. The same idea is followed by the Voting Ensemble technique.
In Voting Ensemble Technique, we take different machine learning algorithms and feed them the same training data to train. In regression problems, the final outcome will be the mean of all the outcomes predicted by different machine learning models. In the classification problem, the voting ensemble technique is further segregated into two parts:
- Hard Voting
- Soft Voting
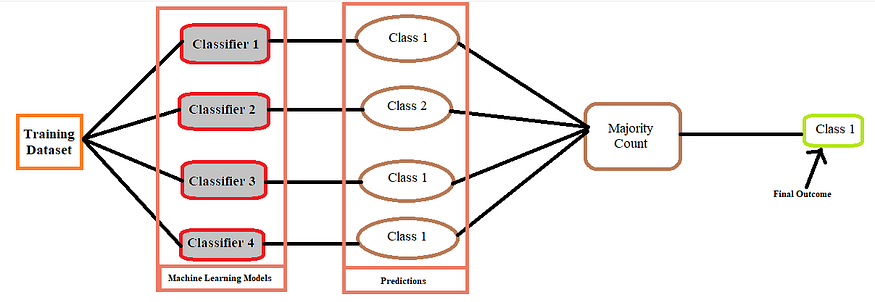
In the Hard Voting classifier, we use ‘majority count’ which means we go for that outcome that is predicted by most of the machine learning models.
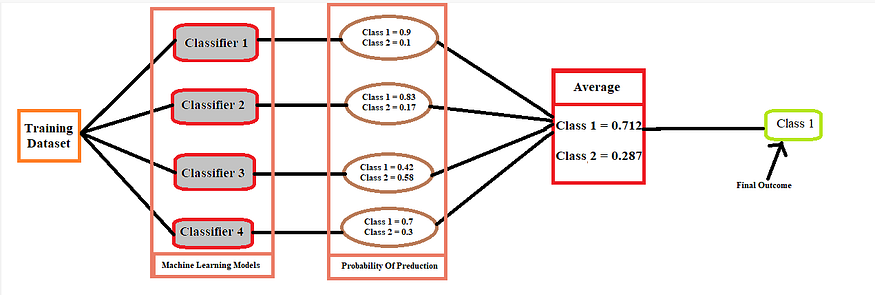
In Soft Voting Classifier, we take the mean of the probability of the outcomes predicted by different machine learning models and then make the final prediction.
What is Stacking Ensemble Technique?
Stacking is another ensemble technique. It is the extension of the voting ensemble technique as we use different learning models which we called Base Models in stacking. On top of that, another model is trained which uses the prediction of the base models for the final outcome. The extra added learning model is known as Meta Model.
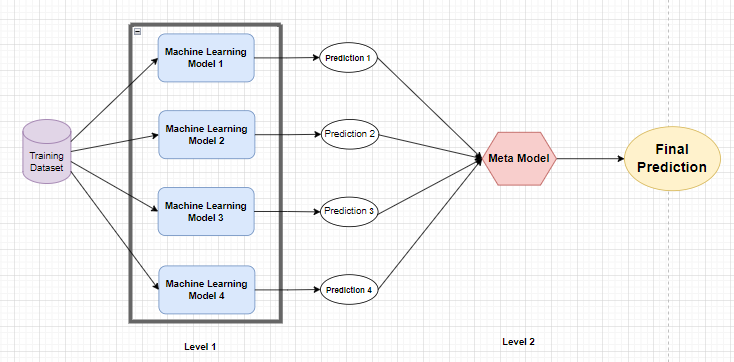
But stacking ensemble faces an overfitting problem because we are using the same training dataset to train the base models and also using the prediction of the same training dataset to train the meta-model. To solve this problem stacking ensemble comes up with two methods.
- Blending
- k-fold
Blending
In this method, we divide the training dataset into two parts. The first part of the training dataset will be used to train the base models then the second part of the training dataset is used by the base models to predict the outcome which is further used by the meta-model.
K-Folds
In this method, we divide the training dataset into k parts/folds, then k-1 parts of the training dataset are used to train the base models and one part which is left is used by the base models to predict the outcome which is further used by the meta-model.
What is the Bagging Ensemble Technique?
Bagging is another ensemble technique. The main idea behind bagging is similar to the voting ensemble technique. But there are two main differences. The first difference, we have to use the same or single algorithm to build the group of predictor or machine learning models and aggregate their results. The second difference, we create random subsets of the training dataset to train the models.
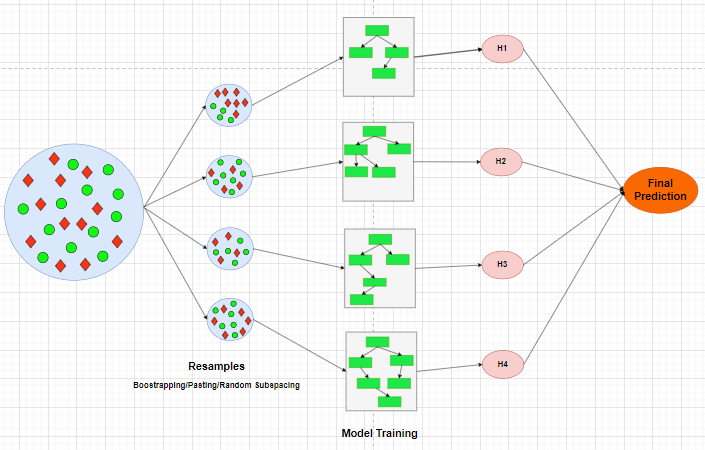
The bagging ensemble technique converts a low bias high variance model to a low bias low variance model by performing randomization and aggregation operations.
We can classify the bagging ensemble technique into three sub-categories on the bases of how the subsets of the training dataset are created.
- Bootstrapping
- Pasting
- Random Subspace
Bootstrapping: In this, subsets of the training dataset are created by picking random rows/tuples with a replacement which means rows of the datasets can be repeated.
Pasting: In this, subsets of the training dataset are created by picking random rows/tuples without replacement which means rows of the datasets cannot be repeated.
Random Subspace: In this, a subset of the training dataset is created by picking random features/columns.
What is Boosting Ensemble Technique?
Boosting is a little different from all the ensemble techniques we have seen above. In boosting, we combine weak machine learning models to achieve a strong model which predicts outcomes with less error margin. But the combination of models is in sequence such that each model considers the errors made by its predecessor. This helps the model to outperform on those particular error points. Finally, we combine all these models by assigning some weights on the basis of their performance and calculate the outcome by using some mathematical function.
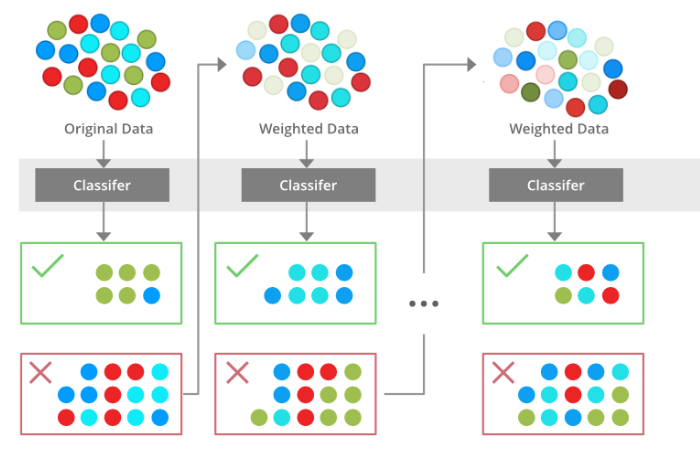
Boosting ensemble technique converts a high bias low variance model to a low bias low variance model by performing additive combination operation.
What are the advantages and disadvantages of the Ensemble Technique?
Advantages:
- Ensemble technique able to produce highly accurate prediction compared to an individual model.
- The Ensemble technique handles the tradeoff between bias and variance pretty well and is able to produce a model which has low bias and low variance.
- The Ensemble technique is able to handle both linear and non-linear datasets because different models are combined which is able to handle these kinds of data.
- Ensemble techniques produce stable models which means they do not show different behavior when exposed to new data points.
Disadvantages:
- The Ensemble technique is costly in terms of time complexity, memory consumption, and procession power.
- The Ensemble technique is not easy to interpret as it’s become impossible to observe each and every model separately and calculate their output then combine them to generate final outcome.
- In ensemble technique, the combining of different models becomes hard and tricky as a single wrong model can decrease the performance of the whole ensemble model.
How do implement these different Ensemble Techniques?
Sklearn provides all the respective packages to implement these ensemble techniques. Let’s see the coding part.
First Import the important packages from python
Preparing a sample dataset

To see how the ensemble techniques give us an advantage, we must see how the individual machine learning models perform with the above dataset. For this example, we will use Logistic regression, K Nearest Neighbors, and Decision Tree algorithms.

Logistic Regression accuracy score = 0.8266666666666667
K Nearest Neighbors accuracy score = 0.9066666666666666
Decision Tree accuracy score = 0.8533333333333334
Now, we will implement different ensemble techniques


Voting Ensemble Technique accuracy score = 0.92
Stacking Ensemble Technique accuracy score = 0.9066666666666666
Bagging Ensemble Technique accuracy score = 0.92
Boosting Ensemble Technique accuracy score = 0.8533333333333334
As we can observe that Voting and Bagging Ensemble technique performing very well.
If you want to explore more in the coding part or want to visualize how different algorithms fit the dataset. Then, please click the below Github repository link.
Articles_Blogs_Content/All_About_Ensemble_Techniques.ipynb at main ·…
This repository contains jupyter notebooks regarding the Articles published in blogs. …
github.com
Like and Share if you find this article helpful. Also, follow me on medium for more content related to Machine Learning and Deep Learning.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



