



We Train Our Machines, Then They Retrain Us: The Recursive Nature of Building AI
Last Updated on August 18, 2023 by Editorial Team
Author(s): Tabrez Syed
Originally published on Towards AI.
On May 10, 1941, German bombs reduced the storied British House of Commons to smoldering ruins; the famous Gothic revival complex had stood for over two centuries as the backdrop for vigorous political debate, yet now this architectural symbol lay in ashes. Amidst the smoke, a pressing question emerged — rebuild identical to the past, or embrace modern redesigns like the sweeping semicircular halls found overseas? To Winston Churchill, the answer was clear. In a 1943 speech, he remarked, “We shape our buildings, and afterwards our buildings shape us,” believing the old chamber’s confrontational intimacy was woven into British democracy’s raucous soul.
Unlike expansive foreign legislative spaces (like the semi-circular layout of the US Capitol building), the old Commons crammed 427 seats tightly together, packing opposing factions face-to-face across a narrow aisle with nowhere to hide. The democratic spirit was fueled by a direct confrontation that led to accountability. While it may have been noisy and messy, it was authentic. Though open to functional improvements, Churchill pushed for the restoration of the arena. Despite the destruction, preserving the shape that had housed centuries of clamorous debate took priority.
Churchill’s sentiment — that constructed spaces shape collective life — extends beyond building design. This notion, sometimes called “architectural determinism,” suggests our built environment profoundly influences human behavior. Urban planners apply these principles deliberately, widening sidewalks to foster pedestrian activity along city boulevards. Or consider a quaint one-lane bridge over a winding creek — its narrowness promotes patience and cooperation as drivers politely wait their turn to cross.
In the digital age, architectural determinism manifests through choices made in constructing AI systems, which will shape the very structure of discourse as large language models permeate society.
Shaping Our Assistants: Teaching AI Through Human Feedback
When OpenAI unveiled GPT-2 in 2019, the natural language model represented a leap forward. Trained on 40 GB of internet text through unsupervised learning, its 1.5 billion parameters could generate remarkably coherent passages. Yet inconsistencies remained. Without human guidance, GPT-2’s impressive but aimless prowess produced verbose meanderings as often as useful information.
To refine their creation, OpenAI pioneered a new approach: reinforcement learning from human feedback (RLHF). The technique, detailed in the paper “Fine-tuning Language Models from Human Feedback,” blends human intuition with AI to steer models toward more “useful” behaviors.
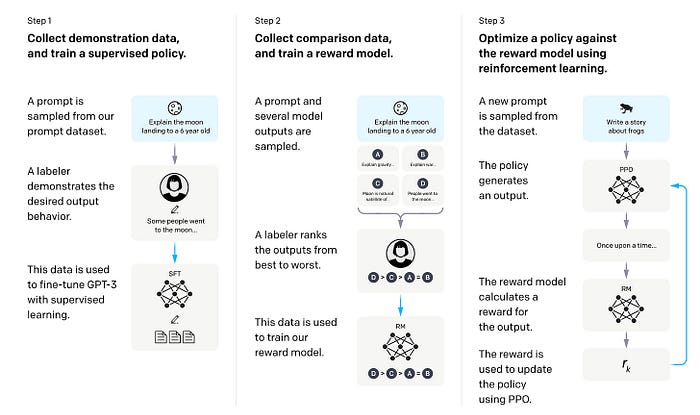
Here’s how it works: Starting with a base model like GPT-2, human trainers interact with the system, playing both user and AI. This conversation creates a dataset reflecting human preferences. Trainers then further shape the model by ranking its sample responses, allowing a “reward model” to be developed that scores output based on quality. The AI progressively improves by fine-tuning the model to maximize its rewards, generating text more aligned with human values. Through cycles of feedback and refinement, RLHF sculpts once erratic models into more helpful, on-point companions.
The fruits of this approach arrived with ChatGPT in 2022. Trained using RLHF, it dazzled users with thoughtful, conversational responses.
The High Cost of Human Wisdom
After the breakthrough of ChatGPT, other AI labs quickly adopted reinforcement learning from human feedback (RLHF). Companies like DeepMind, Anthropic, and Meta leaned on RLHF to craft assistants like Sparrow, Claude, and LLaMA-2-chat.
Yet while effective, RLHF requires immense resources. Each round involves human trainers generating conversations, evaluating responses, and providing guidance at scale. For GPT-3, OpenAI outsourced this laborious process to contractors in Kenya. The “non-profit’s” financial backing enabled this human-powered approach, but such costs limit accessibility for many.
Some organizations are getting creative to overcome the hurdle. The Open Assistant Project invites the public to contribute directly to model training through a crowdsourcing platform. DataBricks gamified the process internally, encouraging its 5,000 employees to judge sample interactions through a fun web interface. This allowed them to build the dataset for their own assistant, Dolly rapidly. Startups like Scale AI also offer services to manage the human annotation required for RLHF.
Copying Classmates: Using LLMs to Bootstrap One Another
As RLHF’s prohibitive price deters many, some researchers are cutting costs by replacing human feedback with the output of other language models.
Stanford’s Human-Centered AI group demonstrated this shortcut. Seeking to retool Meta’s 7 billion parameters LLaMA into a more capable assistant like ChatGPT, they wrote 175 seed tasks and used OpenAI’s DaVinci model to generate a 52,000 example dataset for just $500. Rather than painstaking human annotation, davinci produced labeled data automatically. Fine-tuning LLaMA on this synthetic dataset created Alpaca-7B, an adept assistant, for just $600 total.
Researchers at UC Berkeley collaborated to train the 13 billion parameters Vicuna model using 70,000 conversations scraped from ShareGPT (a website where people share their ChatGPT threads). Vicuna reached 90% of ChatGPT’s performance, trained on data at a fraction of the cost.
Meanwhile, Microsoft and Peking University developed Evol-Instruct, a novel method to exponentially grow seed data using an LLM. Their resulting WizardLM even surpasses GPT-4 in certain skills, demonstrating the power of synthetic datasets.
Open-source datasets like RedPajama’s 1.2 trillion token replicas of LLaMA also aim to democratize model training.
We become what we behold. We shape our tools, and then our tools shape us
Churchill grasped centuries ago how constructed spaces shape collective norms. His insight rings true once more as LLMs proliferate through synthetic training loops. The architectural choices made in those initial models propagate as their output trains new generations. Early flaws and biases subtly ripple down the line, shaping discourse itself.
When LLMs generate text read by millions daily, their idiosyncrasies permeate human expression. As models optimized for engaging chat advise writers, their tendencies infuse published content. Our tools reflect our values, and in time, remake us in their image.
But this dance between creator and creation is not abnormal — it’s the story of human progress. From the printing press to the television, inventions have always circled back to influence their makers. LLMs are just the latest invention to shape society as it is shaped by us.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

