



Vendor-agnostic Setup for Running ML & DL Experiments with GPU Support
Last Updated on January 6, 2023 by Editorial Team
Author(s): Smiral Rashinkar
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Vendor-agnostic Setup for Running ML & DL Experiments With GPU Support
With many emerging solutions like AWS Sagemaker, Microsoft Azure Machine Learning Studio, Google Cloud AI Platform, etc, It can be overwhelming to choose a solution given the cost constraint and use case.
There are some pros and cons when it comes to using a cloud vendor solution:
Pros:
– A tightly integrated platform for data access, IAM, training, testing, and deploying ML & DL workloads
– Solutions like AWS Sagemaker support multiple kernel configurations out-of-box which can be used to run the same notebook on different environment configurations
– Cloud support may come in handy to resolve issues with the platform
– One-click environment creation & being managed service, these platforms usually have very few issues with infrastructure management
Cons:
– Pricing for such managed solutions can be higher than that of an Accelerated Hardware (GPU) VM.
– Solutions and pipelines created will mostly be vendor-dependent based on managed services or tools used. This introduces Vendor Lock-In, making it difficult to evaluate or move to a different vendor for cloud solutions.
THE VENDOR-AGNOSTIC SETUP
We can run multiple workloads using Docker Containers on the same machine with mounted volume which can help in rapid prototyping and experimentation. This Setup can be evolved by systemizing and integrating with various open-source solutions like Kubeflow, Flytelab for orchestration, MLFlow for Model Repository & versioning, Horovod or Ray for Distributed training, etc.
Pros:
– Smaller workloads can share the same VM and its resources (including GPU).
– With mounted volume, the same files are accessible in all containers hosted on the same VM.
-Separation of concerns for ML & DL Libraries, We can also use environment managers like venv or conda but usually managing packages within these environments can get messy. We can also customize each container’s python version without having any consequences on the base VM or other containers.
– One-time waiting period for pulling base images to the VM: Once all the dependencies are downloaded, Spawning up another container takes less than seconds in comparison to AWS Sagemaker instances which take ~2 mins for allocation of resources every time.
– Cost for a GPU Accelerated VM is typically less than that of managed platforms which may yield significant benefits in the longer run.
– No Vendor Lock-in: Freely move your workloads by pushing docker images to private registries and pulling them to VMs on different cloud vendors.
Cons:
– Data Scientists who are not savvy with infrastructure may prefer managed platforms over managing infrastructure for experimentation and deployments.
– Setting up alerts, service, and infrastructure monitoring takes extra effort which is a must-have for any production system.
Steps to set up a vendor-agnostic setup:
Step 1 :
According to the respective workload requirement, provision any Linux Based VM with resources as needed. For the example, we will assume that we want to set up a GPU accelerated experimentation platform. We will require a VM with a GPU provisioned, for eg G4 Series on AWS or NCasT4_v3-series or a GCP Compute engine with Nvidia t4 with 16 GB Memory, 4 vCPUs, and 125 GB Persistent Storage.
Step 2 :
Install and Update all the dev dependencies needed by the OS to function properly.
Step 3:
Installing the CUDA toolkit to access drivers to use the GPU efficiently
Please skip this step in case:
– VM doesn’t have an Nvidia GPU provisioned
– Base Image OS is custom and already has CUDA Support
Head over to https://developer.nvidia.com/cuda-downloads and choose the appropriate options
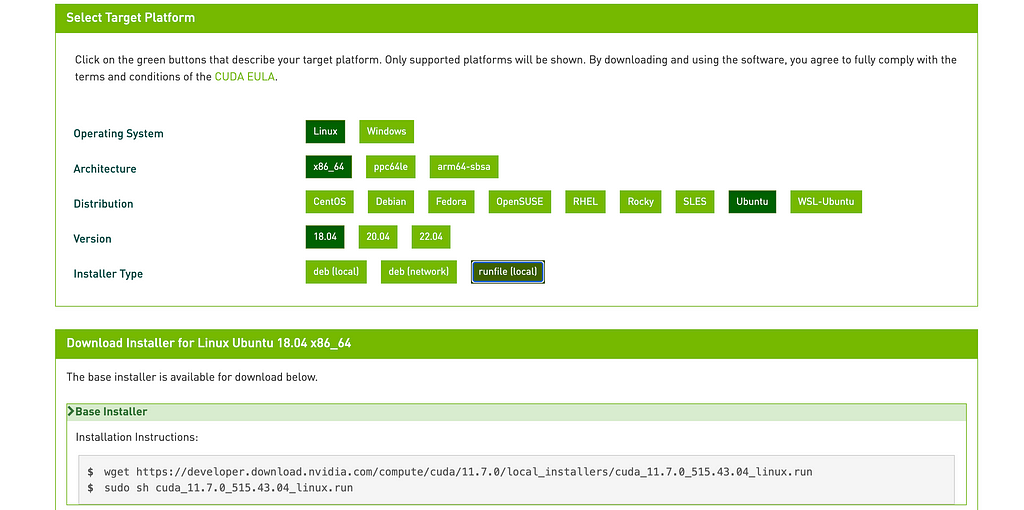
For Advanced users, feel free to head into archives and change the CUDA version and install the same in case of any dependencies or specific use-cases. In case there are no preferences for the CUDA version, the above process should work fine.
Run the Nvidia-smi command to verify the proper install Cuda
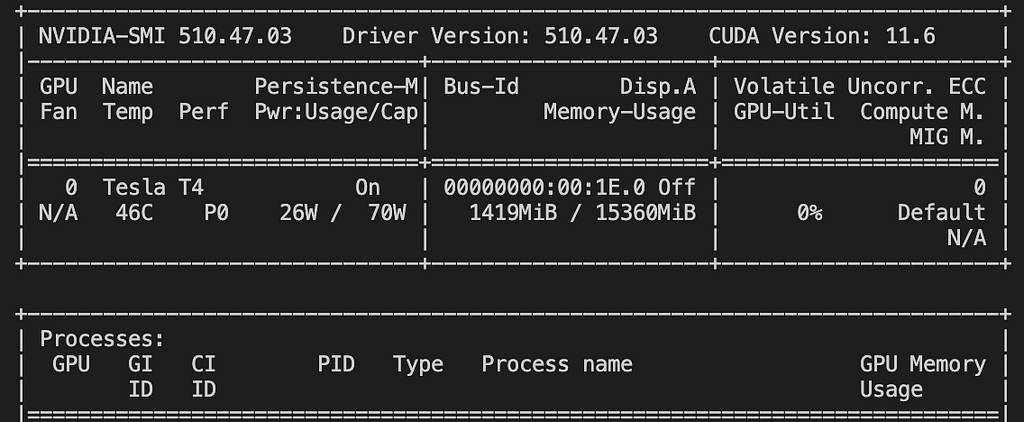
Troubleshooting CUDA Installation:
Make sure CUDA_HOME, and LD_LIBRARY_PATH are added to the path which will invoke the nvidia-smi command properly
Installing Nvidia cuDNN (Optional):
NVIDIA cuDNN is a GPU-accelerated library of primitives for deep neural networks. In case we require running deep learning and neural network-based workloads, it is recommended to have cuDNN installed on the base VM.
Head over to https://developer.nvidia.com/rdp/cudnn-download and accept the terms and conditions. Download the latest one in case there are no frozen requirements for the workloads.
Note: For installation of cuDNN follow the documentation: Link
make sure to match the versions of CUDA and cuDNN package deb downloaded from the site while installing dependencies
8.x.x.x-1+cudaX.Y <- 8.x.x.x-1 refers to cuDNN version downloaded and cudaX.Y refers to CUDA version installed previously. To confirm the Cuda version run the Nvidia-smi command. (Above version is 11.6)
Run the following command to ensure cuDNN is properly installed:

Step 4:
Installing Docker and Docker-compose –
#Docker installation
curl https://get.docker.com | sh
&& sudo systemctl --now enable docker
#Docker-compose installation
cd /usr/local/bin && sudo rm -rf docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-x86_64" -o /usr/local/bin/docker-compose
sudo chmod +x docker-compose
We can use docker-compose to set up multiple dependencies like mock DB for our training containers. This can come in handy while evaluating new solutions through rapid prototyping with docker-compose.
Installing Nvidia-Docker2 :
In the case of having GPU Accelerated workloads, we need the following configurations to be met by the system –
1. Docker Engine requires additional drivers to run workloads on GPUs.
2. Accelerated workload containers require Cuda drivers installed on containers to leverage GPU processing.
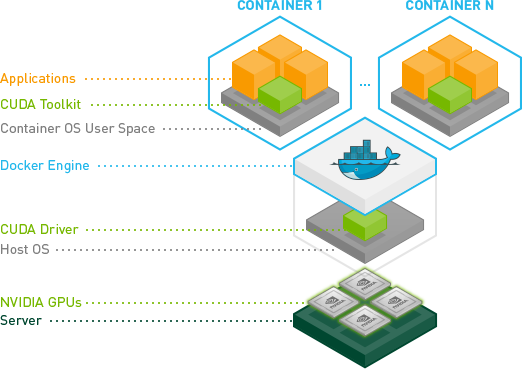
Run the following to install nvidia-docker2 on the VM instance.
#adds the distribution to OS for installing drivers for docker
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add —
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
#Update and install nvidia-docker2
sudo apt-get update
sudo apt-get install -y nvidia-docker2
#restart docker engine to load new config
sudo systemctl restart docker
We can verify the installation by the following command:
sudo docker run -rm -gpus all nvidia/cuda:11.0-base nvidia-smi
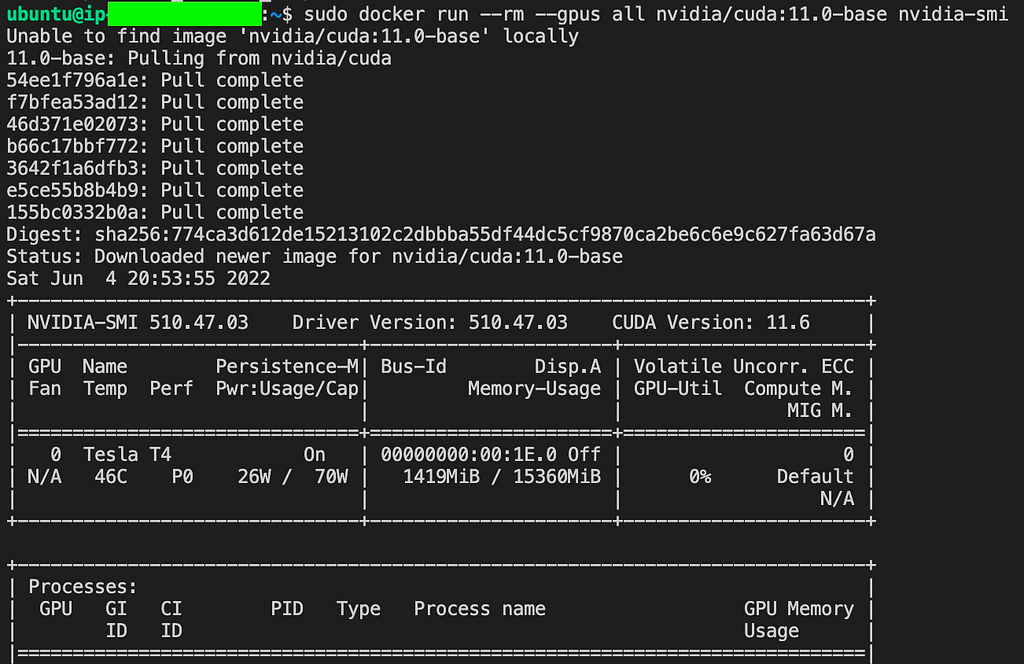
With this, we have completed the basic setup required to run and manage GPU Workloads on platform-agnostic VMs.
Creation of custom docker images as per requirements:
As noted above, if we want to run GPU Accelerated workloads the container must have a Cuda toolkit and drivers to communicate with the GPU.
This can be achieved by getting a base image for the docker build which already has Cuda drivers preinstalled which we can further customize by installing packages for python and OS. To learn more about using containers for Data Science workloads check out the blog: Link.
Note: For running containerized workloads that use GPUs on VM for acceleration, the docker run command would look like
# Here — gpus all specify that all GPUs available are to be used for # accelerating workload
sudo docker run — gpus all tensorflow/tensorflow:latest-gpu-jupyter
So now we have the basic setup, where are we headed to?
Now that you’re able to run platform-agnostic accelerated workloads only using a VM inside the docker containers, it can finally evolve into more opinionated systems based on customized requirements and use cases. Remember that these can again be integrated with managed open-source offerings or even with cloud-specific tools if needed.
For Example (See fig1), Containers can access data residing in any structured or unstructured DB through private VPC enabled for the VM or Kubernetes cluster network. We could have a single VM with GPU acceleration to run multiple smaller workloads or a powerful multi-GPU instance running distributed training on a large amount of data. These can then be integrated with MLFlow for storing, and managing ML artifacts and its training and evaluation metrics. We can further configure the artifact store to be an s3 bucket, azure blob storage or a GCP bucket based on the cloud environment preferred.
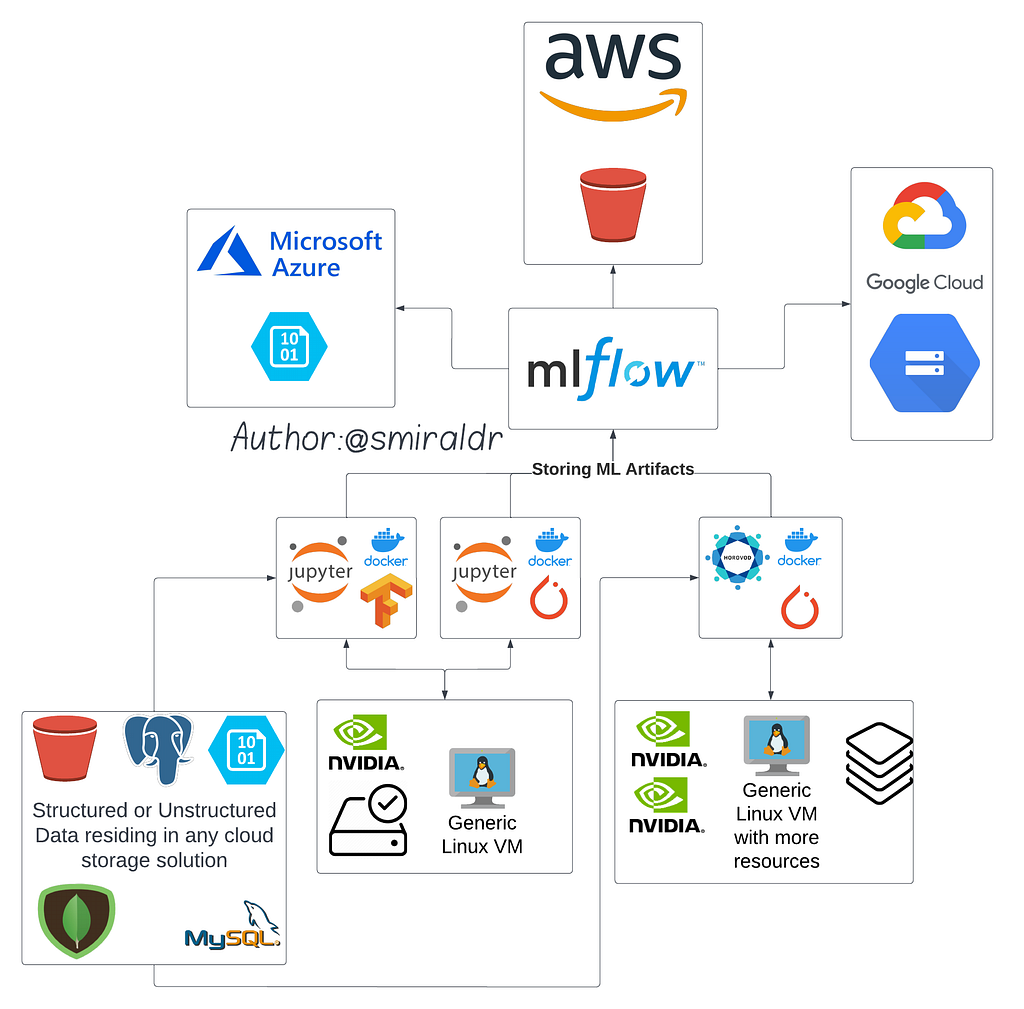
Moving further (see Fig2) after the deployment of the model, using MLOps solutions like whylogs, nannyml, etc we can trigger the kubeflow pipeline based on model inference metrics depreciation, and drift metrics. The pipeline can be configured to spawn a spot instance pod (cheaper than an on-demand instance pod) on Kubernetes which can then be used to repeat the training process with new or modified data in the same environment on a Ray cluster for distributed training. After the training completion, resources are freed which can help reduce costs in the longer run.

All these systems need a one-time setup effort. Configuring monitoring and custom alerts are also needed to improve the transparency of pipelines.
Sum and Substance
ML Architects will have to evaluate the situation for the typical “build vs buy” scenario. If we are planning to run smaller experiments for less period on a short-term basis, buying and using the managed services would provide a better ROI as building a custom platform has to be justified for its efforts. In the case of running larger and longer experiments on a long-term basis where customized solutions are required; after a cost and effort analysis, building a platform might be more suitable for training, deploying, monitoring, and maintaining ML Models in production for an extended period.
Vendor-agnostic Setup for Running ML & DL Experiments with GPU Support was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

