



Vector Quantization & VQ-GAN
Last Updated on July 25, 2023 by Editorial Team
Author(s): Jack Saunders
Originally published on Towards AI.
Towards Generating Ultra-High Resolution Talking-Face Videos with Lip-Synchronization
The holy grail of deepfake models is the person-generic model, which, given only a single image or very short video of a person's face, can produce an altered video of that person. As you may know from a previous post, person-generic models, particularly those based on the popular wav2lip model, usually suffer from two considerable setbacks: an inability to capture the idiosyncrasies of a person and a generally low visual quality. In this article, we will look at one of the models designed to address the latter of these issues. The paper [1] titled:
“Towards Generating Ultra-High Resolution Talking-Face Videos with Lip Synchronization”
takes a Wav2Lip [2] style approach, using an expert discriminator that can tell if lips are synchronized or not. While Wav2Lip works on 96 by 96-pixel images, this paper looks to extend the method to 768 by 768 pixels, a huge 64 times increase in the number of pixels! A natural question to ask would be how easy is it to just increase the size of the training data and make the models from Wav2Lip deeper? The answer to this is that it does not work. Just look at the spin-off GitHub repos that have tried to do just this. Clearly, then, some new method is needed to achieve this. Enter Vector-Quantization.
Given a dataset, Vector Quantization involves learning a latent representation of the data using an autoencoder, but with unique features. The latent space consists of discrete vectors, rather than continuous ones. This may not sound like a huge difference, but it is. Using discrete tokens allows for a huge level of compression, and also enables token-based models such as the transformer to operate on the latent space.
Vector Quantization is achieved by jointly learning encoder and decoder networks, as well as a codebook consisting of learnable and continuous latent vectors. This may seem counterintuitive, as we want to learn a discrete latent space. However, the codebook actually allows us to do this. We can represent the latent space by the index of the latent vector in the codebook. As an example, the codebook may be: {0=(0, 0.2), 1=(0.5, 0.6), 2=(0.8, 0.4)} then a latent vector (0.8, 0.4) could be written using the index 2. In practice, many latent vectors are used to represent each image, as shown in the diagram below.
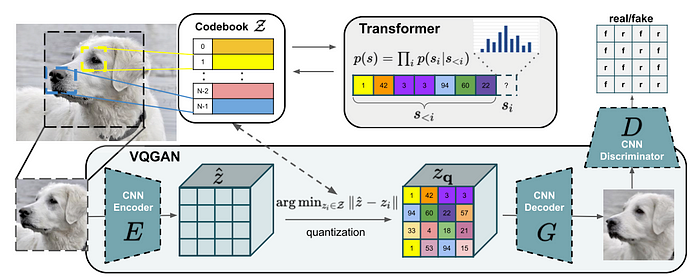
There are several subtypes of Vector Quantization models. The one used for this paper is a VQGAN [3], based on the Generative Adversarial Network. Here, in addition to a reconstruction loss, an adversarial loss is also applied to improve the reconstruction quality. Two VQGAN networks are trained, one for the full face images, and one for the same images, but with the lower half of the face masked.

Reframing the Problem
Given these VQGANs, the problem can now be reframed. Rather than trying to inpaint the bottom half of the face image, containing over a quarter of a million pixels, the problem is now to convert the quantised masked face image to the quantised full face image. This is a much easier problem.
The main section of the paper now largely follows the Wav2Lip style approach. If you’re not familiar with it, I would suggest reading my previous post on it. But, in essence, to generate a frame with the lips changed you do the following:
- Mask out the lower half of the face.
- Take an audio window corresponding to the new lips, using MEL spectrograms, centred around the target frame.
- Take a random reference frame from the same video.
- Encode each separately, combine them by concatenation and then decode.
In this paper, it is much the same, except now the masked frame and reference frame are first converted in the quantized space.

In a similar fashion, the lip-sync expert discriminator, the SyncNet, is also trained in the quantised space. The SyncNet is now given both an audio segment and a sequence of quantised frames and is asked to predict if they are in or out of sync. This network can then be used as a loss for the lip-sync generation. It is worth noting that, as this model is trained in the lower dimensional quantised space, it can be trained on longer sequences. For this work, a full second is used, which helps further improve the sync.
Further Improving the Quality
Despite the improved visual quality obtained by using VQGAN, there is still some noticeable lack of quality in the final output, particularly in the lip region. To address this, the authors propose an additional post-processing step. They train a face restoration GAN [4], which is able to improve the sharpness of the lips and use this as a post-processing step.
Verdict
This paper makes impressive strides in improving the visual quality of person-generic models. However, the results are not publicly available anywhere, as far as I can tell, making it hard to gauge how good the model is. What’s more, the results that can be seen in the paper seem to suggest that this model still struggles with the other problem in person generic models: capturing person-specific idiosyncracies. I suspect this is largely due to idiosyncrasies being overwritten by the VQGAN where it is unable to capture them. As an example, look at the lips in the following figure:

For the man in the bottom row, the lips are far more pink than one would expect, suggesting that the model has not learned the idiosyncrasies correctly. It would be interesting to see what happens if more than one reference frame is given per person.
Despite these drawbacks though, the quantitative and quantitative evaluations show that the model is very high quality and I look forward to seeing the videos in the future!
References
[1] Towards Generating Ultra-High Resolution Talking-Face Videos with Lip-Synchronization. Gupta et. al. WACV 2023
[2] A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild. Prajwal et. al. ACM Multimedia 2020
[3] Taming Transformers for High-Resolution Image Synthesis. Esser et. al. CVPR 2021
[4] GAN Prior Embedded Network for Blind Face Restoration in the Wild. Yang et. al. CVPR 2021
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


