



Unlock New Value Chain in AI/ML
Last Updated on December 30, 2022 by Editorial Team
Author(s): Murli Sivashanmugam
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
How could Privacy Preserving ML uncover new values in AI/ML value chain?
The evolution of AI/ML in the past decade is drastic and dramatic compared to any other technology in our past history. This high pace of evolution can be attributed to two primary factors, the availability of datasets and the open-source community with access to these datasets. It is undeniable fact that the datasets like ImageNet, COCO, NLTK, GPT-2, and GloVe, played a significant role in the evolution of AI/ML.
When the AI evolution started a decade ago hardly there was any awareness of the value of data nor its implications on privacy. Fast forward to the present day, countries are rolling our data protection laws and most of us are at least aware of the potential harm a data leak could cause to us. With the increased awareness and regulations on data protection, it is very likely that the public availability of new datasets will come down and hence it could slow down the evolution of AI going further.
Data privacy concerns are far more pronounced with organizations as they treat their data as an Intelectual Property and are not willing to share it with third parties. Privacy-Preserving ML (PPML) has lots of promising potentials to unlock new values in the ML value chain.
What is Privacy Preserving ML?
Today the entire lifecycle of AI/ML applications is confined within a Trust boundary. Every organization is forced to hire an in-house data science team or short-term consultants to extract value from their data. Some of the organizations succeeded in doing so but many of them don’t. The requirement to stone-wall their data is hurting the organisation as its rate of innovation is limited by its in-house capabilities. Today no one is building in-house database applications like MongoDB, Redis, etc., but everyone is building forecasting models, recommendation systems, sequence predictions etc., and trying to put them into production. Privacy-Preserving ML(PPML) could help organisations to transcend trust boundaries and extract values out of AI/ML applications more than what they do today. PPML is not only about controlling and securing training data it is also about securing trained models, data that is sent to the model for inferencing and the predictions that are generated by the model. They form the four pillars [1] of PPML.
Of late there are multiple research and development efforts focused on PPML. Federated Learning has gained popularity recently, thanks to the publication from Google, “Federated Learning for Mobile Keyboard Prediction” [2], which gave a confidence boost for productizing Federated Learning. At the same time the publications like “Advances and open problems in federated learning” [3] and “Federated learning systems: Vision, hype and reality for data privacy and protection” [4] gave us the clarity that Federated Learning is one part of the puzzle that is needed to solve the PPML. The publication “Privacy-Preserving Machine Learning: Methods, Challenges and Directions” [5] outlines a good framework and vocabulary for defining and accessing a PPML solution.
Trust Domains in Privacy Preserving ML
Figure 1 below captures the Trust Domains involved in the ML Value Chain.
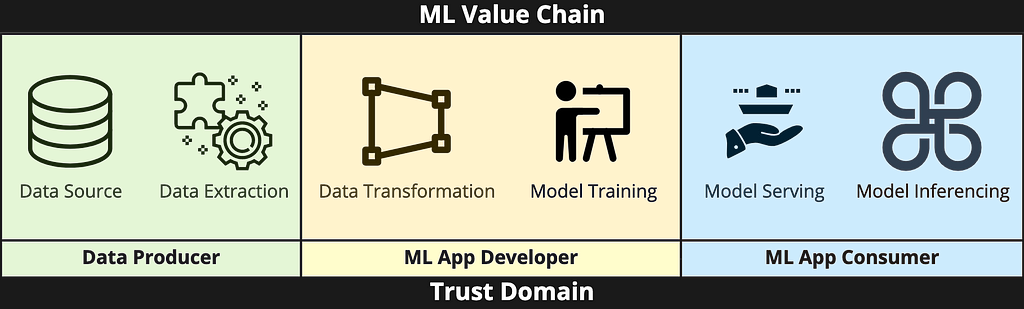
The ML Value chain has three sub-domains namely data generation, model training and model consumption. The primary goal of PPML is to enable multiple parties to participate in this value chain with limited or zero trust. When the responsibility of Data Generation, Model Development and Model Inferencing is owned by a single entity like one person or one scrum team, then there won’t be a need for PPML. As the scope and applicability of ML Applications widen, it is not possible to manage the end-to-end ML lifecycle by a single scrum team or business unit. When the ML value chain is shared by multiple scrum teams or business units or organizations the responsibility of securing ML solutions is also shared and hence there is a need for a PPML framework to ensure the ML value chain is secured end-to-end.
To enable zero trust between Trust Domains, the privacy mechanism offered by each domain should be self-contained. For example, the trust mechanism employed by ML App Developers should be self-contained and should not be dependent on the Data Producers' Privacy mechanism.
PPML Trust-O-Meter
The infographic below tries to capture the PPML technologies as a framework that can be applied to different levels of Trust. These infographics are not intended to provide a complete map of all the PPML technologies available today but rather provide a sense of possible options one can consider for rolling out PPML solutions for different requirements.
Data Producers Trust-O-Meter
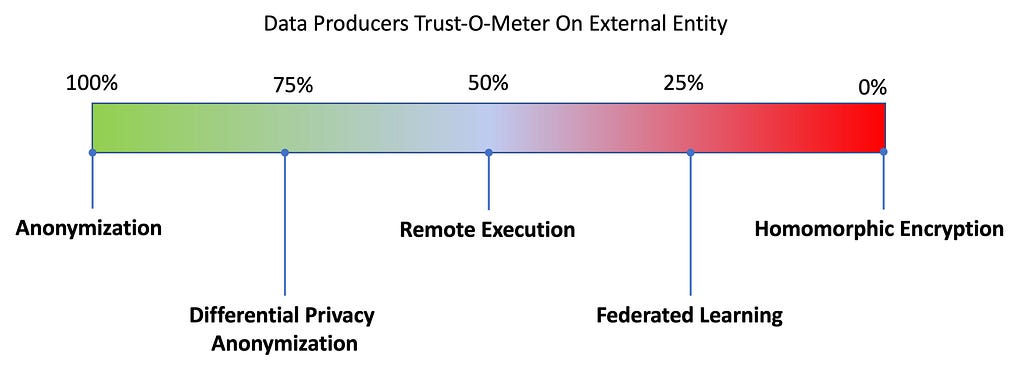
Data Producers to participate in the ML value chain needs to safeguard their Data and ensure that the Data doesn’t leave their trusted domain. They need to expose a controlled, restricted and auditable interface of their data to third parties without compromising data privacy and risk of losing their data asset. The Data Producer should consider implementing Anonymization at the least to obfuscate sensitive information. Differential Privacy based anonymization and Remote Execution technologies can be considered when the Trust factor is considerably high on the external entity. When the Trust factor is limited, one could consider employing Federated Learning and Homomorphic Encryption. Federated Learning has seen limited rollouts to production in recent times and where as Homomorphic Encryption is still in the research domain.
ML App Providers Trust-O-Meter
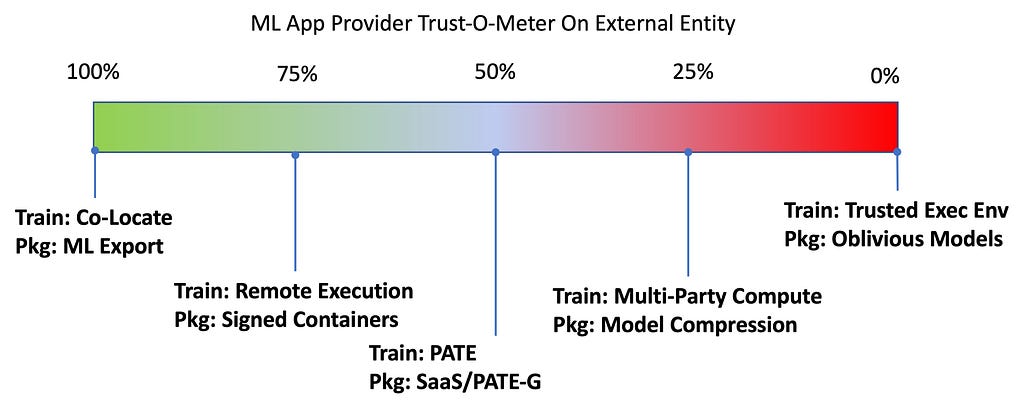
The Model or ML App Providers needs to perform EDA and train the models without having access to the actual data locally. The ML App providers would be interested in protecting their models from multiple external entities of Data providers and Model Consumers. They need to protect model weights and architecture to ensure that the training data and model training can not be reverse-engineered. The ML App providers could consider Remote Execution environments and a ‘PATE’ type of knowledge distillation approaches for training when the Trust level is considerably high on the Data Providers and could consider Signed Containers and SaaS or PATE-G type of model abstraction for packaging models for interfacing by model consumers. When the Trust level is low one could consider approaches like Multi-Party Compute (MPC) and Trusted Execution Environment (TEE) for training and Model Compression and Oblivious Models for Model Packaging.
ML App Consumers Trust-O-Meter
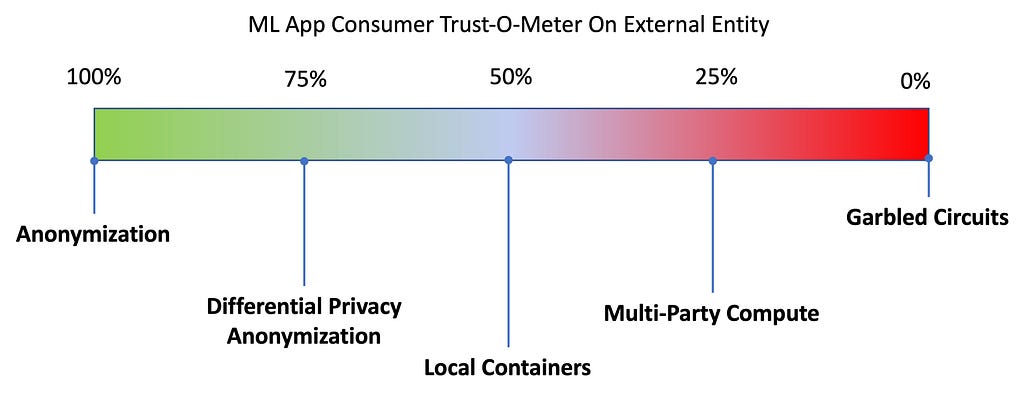
The ML App Consumers would like to protect the sensitive input data like health records, credit scores and the resulting inferences like diagnosis, credit rating etc from ML App providers. At the least ML App Consumers should consider employing traditional Anonymization techniques on sensitive information. When the Trust level is considerably high, one could consider applying approaches like Differential Privacy based Anonymisation techniques and Local Containers to safeguard input data. When the trust level is low one should consider employing Multi-Party Compute and Garbled Circuits technology to ensure the privacy of input data. The technologies of Multi-Party-Compute and Garbled Circuits are still in the research domain.
Security and privacy are never absolute and there will always be a compromise between trust, security and resource availability. One needs to make a trade-off decision depending on the value that needs to be protected on a case-to-case basis. For every use case, one should get into the practice of assembling a PPML profile depending on the parties involved, the trust factor, and resource requirements. Hope the infographics mentioned above could serve as a starting point for creating such profiles.
Conclusion
Even though many of the PPML technologies today are still in the research domain, there are considerable technologies, especially in the Data Producer’s domain, that can be rolled out to production today. One should look at deploying PPML technologies to production as they evolve and thus uncovering new values in ML value chains so that collectively we keep pushing ML to new frontiers in a secure way.
References
- Perfectly Privacy-Preserving AI. What is it, and how do we achieve it? | by Patricia Thaine | Towards Data Science
https://towardsdatascience.com/perfectly-privacy-preserving-ai-c14698f322f5 - Andrew Hard, Kanishka Rao, Rajiv Mathews, Swaroop Ramaswamy, Françoise Beaufays, Sean Augenstein, Hubert Eichner, Chloé Kiddon, Daniel Ramage: “Federated Learning for Mobile Keyboard Prediction”, 2018; arXiv:1811.03604
- Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, et al: “Advances and Open Problems in Federated Learning”, 2019; arXiv:1912.04977
- Qinbin Li, Zeyi Wen, Zhaomin Wu, Sixu Hu, Naibo Wang, Yuan Li, Xu Liu, Bingsheng He: “A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection”, 2019; arXiv:1907.09693
- Runhua Xu, Nathalie Baracaldo, James Joshi: “Privacy-Preserving Machine Learning: Methods, Challenges, and Directions”, 2021; arXiv:2108.04417
Copyright © A5G Networks, Inc.
Unlock New Value Chain in AI/ML was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

