



Understanding Hyper-parameter-tuning of YOLO’s
Last Updated on July 25, 2023 by Editorial Team
Author(s): Chinmay Bhalerao
Originally published on Towards AI.
Different hyper-parameters and their importance in model building
YOLO (You Only Look Once) is a state-of-the-art object detection system that can detect objects in real-time. YOLOv8 is the latest version of YOLO, and it has several hyperparameters that affect the performance of the model. In this answer, we will discuss the different hyperparameters in YOLOs and YOLOv8 and their meanings.
Hyper-parameter tuning
In the context of object detection, hyperparameter tuning refers to the process of selecting the optimal values for the various parameters and settings that are used in the training of an object detection model. These parameters and settings, which are often referred to as hyperparameters, can have a significant impact on the performance of the model, including factors such as accuracy, precision, and recall.
Hyperparameters in object detection can include settings related to the architecture of the model, such as the number and size of the convolutional layers, as well as parameters related to the training process, such as the learning rate, the batch size, and the number of training epochs.
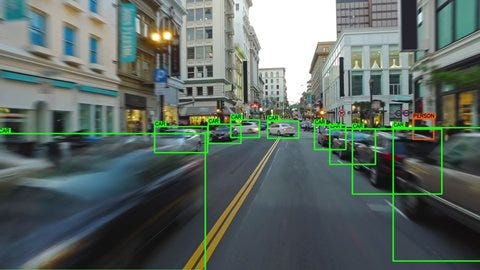
Hyperparameter tuning involves experimenting with different values for these parameters and evaluating the performance of the model under each configuration. This process can be time-consuming and resource-intensive, but it is essential for achieving the best possible performance from an object detection model. Some common techniques for hyperparameter tuning include grid search, random search, and Bayesian optimization.
But if you are new to YOLO 8, then check out the below blog for a detailed understanding of YOLO v8.
YOLO v8! The real state-of-the-art?
My experience & experiment related to YOLO v8
medium.com
Let's understand all hyper-parameters in detail.
Learning rate: The learning rate determines how much the weights of the neural network are updated during training. A high learning rate can cause the model to overshoot the optimal weights, while a low learning rate can cause the model to converge slowly. In YOLOv8, the default learning rate is set to 0.001.
learning_rate=0.001
Batch size: The batch size is the number of samples that are processed at once during training. Larger batch size can lead to faster convergence, but it can also require more memory. In YOLOv8, the default batch size is set to 64.
batch=64
Input size: The input size is the size of the input image that is fed into the neural network. In YOLOv8, the default input size is 608×608.
width=608
height=608
The number of anchors: The number of anchors is the number of bounding box shapes that are used to detect objects in the image. In YOLOv8, the default number of anchors is set to 3.
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
num_anchors=3
Number of classes: The number of classes is the number of different object categories that the model can detect. In YOLOv8, the default number of classes is set to 80, which is the number of classes in the COCO dataset.
classes=80
Confidence threshold: The confidence threshold is the minimum confidence score that an object must have to be considered a detection. In YOLOv8, the default confidence threshold is set to 0.25.
confidence=0.25
NMS threshold: The non-maximum suppression (NMS) threshold is the threshold used to eliminate overlapping bounding boxes. In YOLOv8, the default NMS threshold is set to 0.45.
nms_threshold=0.45
IOU threshold: The intersection-over-union (IOU) threshold is the threshold used to determine whether two bounding boxes overlap. In YOLOv8, the default IOU threshold is set to 0.5.
iou_threshold=0.5
Number of filters: The number of filters is the number of convolutional filters in each convolutional layer. In YOLOv8, the default number of filters is set to 64.
filters=64
Number of layers: The number of layers is the number of convolutional layers in the neural network. In YOLOv8, the default number of layers is set to 53.
layers=53
Activation function: The activation function is used to introduce non-linearity into the neural network. In YOLOv8, the default activation function is the LeakyReLU function.
activation=leaky
These are all important hyperparameters that will help you to increase your model’s performance. Not only for V8 but for any of YOLO most of these parameters will stay the same.
Brut-forcibly speaking, the following can be a grid search for executing hyperparameter tuning. But still, it will be quite computationally expensive to run a grid search for object detection.
from sklearn.model_selection import ParameterGrid
import os
# Define hyperparameters to tune
learning_rates = [0.0001, 0.001, 0.01]
batch_sizes = [32, 64, 128]
optimizers = ['adam', 'sgd']
epochs = [50, 100, 150]
network_architectures = ['yolov8', 'yolov8-tiny']
activation_functions = ['relu', 'leaky_relu']
loss_functions = ['binary_crossentropy', 'focal_loss']
data_augmentation = [True, False]
# Set up the search space
search_space = {'learning_rate': learning_rates,
'batch_size': batch_sizes,
'optimizer': optimizers,
'epochs': epochs,
'network_architecture': network_architectures,
'activation_function': activation_functions,
'loss_function': loss_functions,
'data_augmentation': data_augmentation}
# Create parameter grid
parameter_grid = ParameterGrid(search_space)
# Train and evaluate the model for each combination of hyperparameters
for parameters in parameter_grid:
# Set hyperparameters for the model
learning_rate = parameters['learning_rate']
batch_size = parameters['batch_size']
optimizer = parameters['optimizer']
num_epochs = parameters['epochs']
architecture = parameters['network_architecture']
activation = parameters['activation_function']
loss = parameters['loss_function']
augmentation = parameters['data_augmentation']
# Train and evaluate the model
train_yolo_v8(learning_rate, batch_size, optimizer, num_epochs, architecture, activation, loss, augmentation)
mAP = evaluate_yolo_v8()
# Save the results
result = {'learning_rate': learning_rate,
'batch_size': batch_size,
'optimizer': optimizer,
'num_epochs': num_epochs,
Pros of hyper-parameter tuning:
Improved accuracy: Hyperparameter tuning can help to optimize the model’s parameters to improve its accuracy. This can lead to better object detection results and more precise predictions.
Faster convergence: By tuning the learning rate and other hyperparameters, it is possible to speed up the training process, allowing the model to converge faster.
Customization: Hyperparameter tuning allows for customization of the model to fit specific requirements, such as specific object detection tasks.
Cons of hyper-parameter tuning:
Time-consuming: Hyperparameter tuning can be time-consuming and requires a significant amount of experimentation to determine the optimal hyperparameters.
Overfitting: Tuning the model to perform well on a specific dataset can result in overfitting, which can lead to poor performance on new data.
Computationally expensive: Hyperparameter tuning requires running the model multiple times with different hyperparameters, which can be computationally expensive and resource-intensive.
Difficulty in reproducing results: If the tuning process is not well-documented, it can be challenging to reproduce the same results on different datasets or in different environments.
If you have found this article insightful
It is a proven fact that “Generosity makes you a happier person”; therefore, Give claps to the article if you liked it. If you found this article insightful, follow me on Linkedin and medium. You can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
You can read my other blogs related to :
A Practical Guide to Selecting CNN Architectures for Computer Vision Applications
From LeNet to EfficientNet: Choosing the Best CNN Architecture for Your Project
levelup.gitconnected.com
How to Choose the Best Algorithm for Your Machine Learning Project
Optimizing ML Model Performance: A Guide to Algorithm Selection
medium.com
A Deep Dive into Non-Maximum Suppression[NMS]: Understanding the Math Behind Object Detection
Navigating Non-Maximum Suppression: A Guide to Optimizing Your Object Detection
medium.com
Working on a Computer Vision project? These code chunks will help you !!!
An introduction to a few “used to” methods in a computer vision project
pub.towardsai.net
Signing off,
Chinmay Bhalerao
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

